 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoralBERT: Detecting Moral Values in Social Discourse
Paper and Code
Mar 12, 2024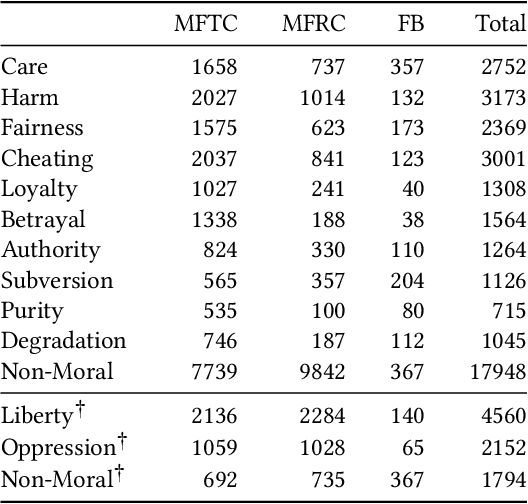
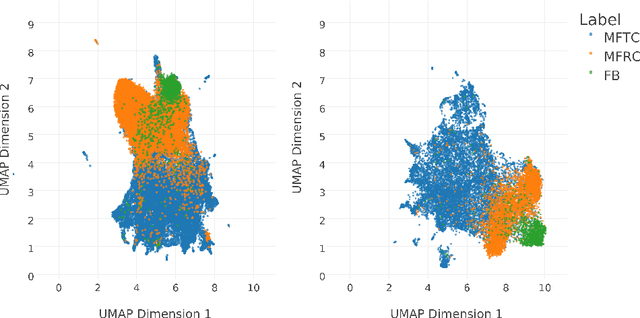
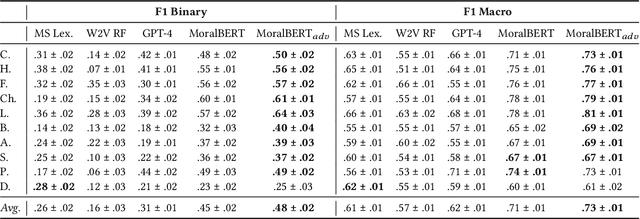
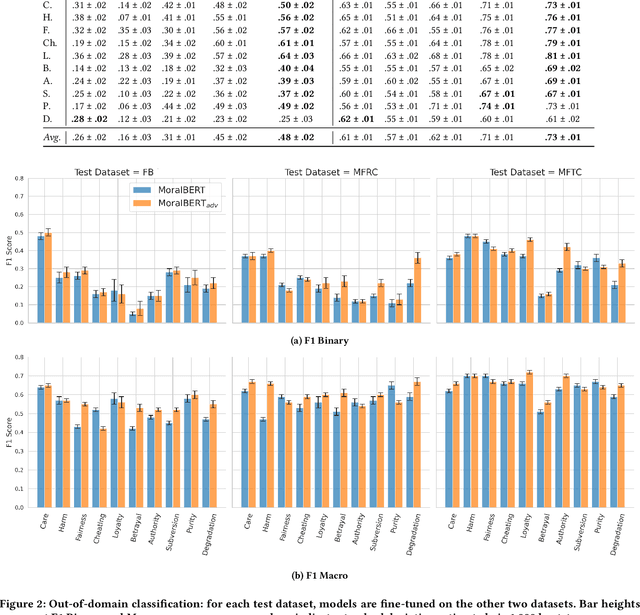
Morality plays a fundamental role in how we perceive information while greatly influencing our decisions and judgements. Controversial topics, including vaccination, abortion, racism, and sexuality, often elicit opinions and attitudes that are not solely based on evidence but rather reflect moral worldviews. Recent advances in natural language processing have demonstrated that moral values can be gauged in human-generated textual content. Here, we design a range of language representation models fine-tuned to capture exactly the moral nuances in text, called MoralBERT. We leverage annotated moral data from three distinct sources: Twitter, Reddit, and Facebook user-generated content covering various socially relevant topics. This approach broadens linguistic diversity and potentially enhances the models' ability to comprehend morality in various contexts. We also explore a domain adaptation technique and compare it to the standard fine-tuned BERT model, using two different frameworks for moral prediction: single-label and multi-label. We compare in-domain approaches with conventional models relying on lexicon-based techniques, as well as a Machine Learning classifier with Word2Vec representation. Our results showed that in-domain prediction models significantly outperformed traditional models. While the single-label setting reaches a higher accuracy than previously achieved for the task when using BERT pretrained models. Experiments in an out-of-domain setting, instead, suggest that further work is needed for existing domain adaptation techniques to generalise between different social media platforms, especially for the multi-label task. The investigations and outcomes from this study pave the way for further exploration, enabling a more profound comprehension of moral narratives about controversial social issues.