 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploration in two-stage recommender systems
Paper and Code
Sep 01, 2020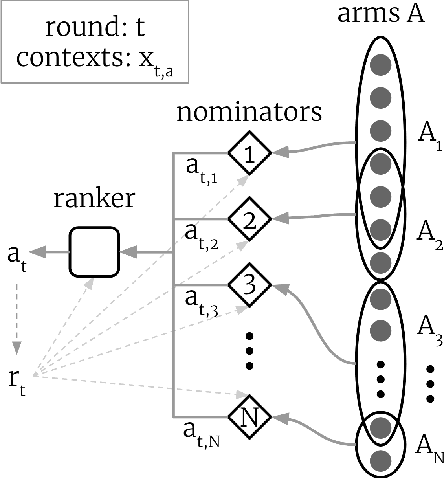
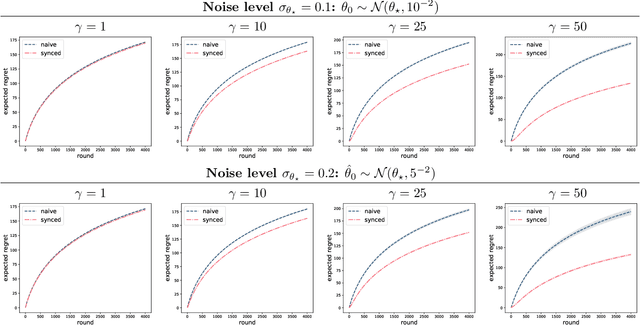
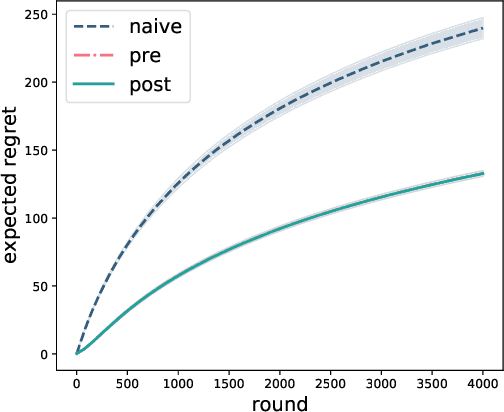
Two-stage recommender systems are widely adopted in industry due to their scalability and maintainability. These systems produce recommendations in two steps: (i) multiple nominators preselect a small number of items from a large pool using cheap-to-compute item embeddings; (ii) with a richer set of features, a ranker rearranges the nominated items and serves them to the user. A key challenge of this setup is that optimal performance of each stage in isolation does not imply optimal global performance. In response to this issue, Ma et al. (2020) proposed a nominator training objective importance weighted by the ranker's probability of recommending each item. In this work, we focus on the complementary issue of exploration. Modeled as a contextual bandit problem, we find LinUCB (a near optimal exploration strategy for single-stage systems) may lead to linear regret when deployed in two-stage recommenders. We therefore propose a method of synchronising the exploration strategies between the ranker and the nominators. Our algorithm only relies on quantities already computed by standard LinUCB at each stage and can be implemented in three lines of additional code. We end by demonstrating the effectiveness of our algorithm experimentally.