 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving COVID-19 Forecasting using eXogenous Variables
Jul 20, 2021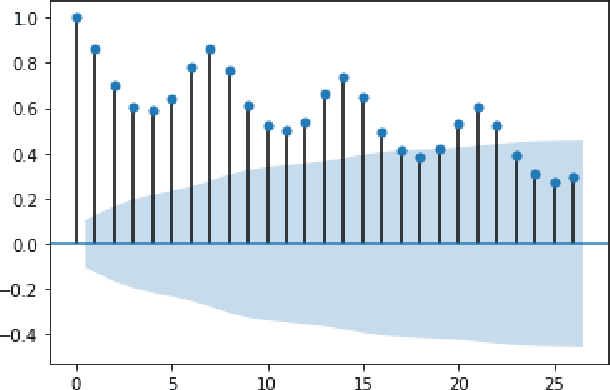
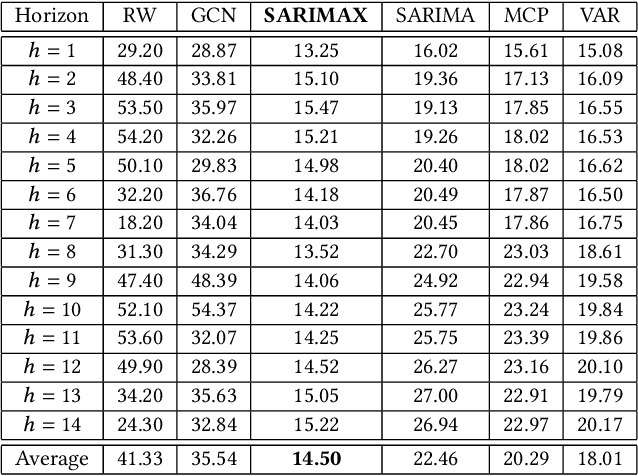
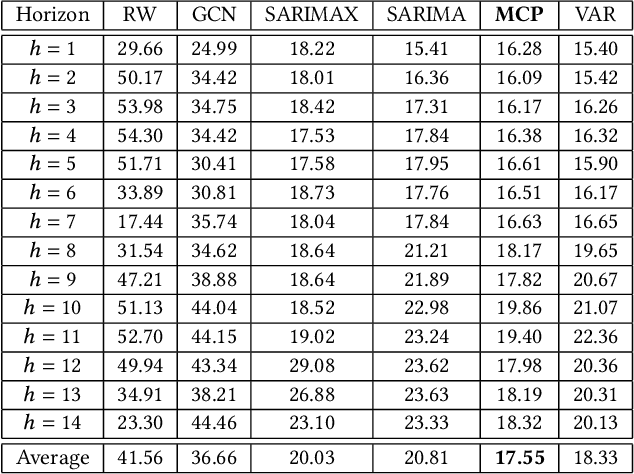
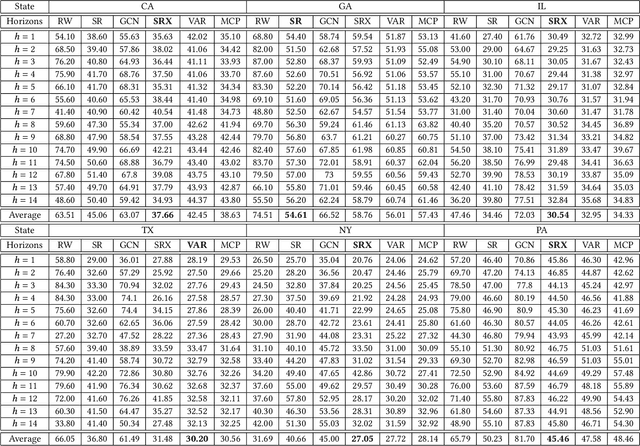
In this work, we study the pandemic course in the United States by considering national and state levels data. We propose and compare multiple time-series prediction techniques which incorporate auxiliary variables. One type of approach is based on spatio-temporal graph neural networks which forecast the pandemic course by utilizing a hybrid deep learning architecture and human mobility data. Nodes in this graph represent the state-level deaths due to COVID-19, edges represent the human mobility trend and temporal edges correspond to node attributes across time. The second approach is based on a statistical technique for COVID-19 mortality prediction in the United States that uses the SARIMA model and eXogenous variables. We evaluate these techniques on both state and national levels COVID-19 data in the United States and claim that the SARIMA and MCP models generated forecast values by the eXogenous variables can enrich the underlying model to capture complexity in respectively national and state levels data. We demonstrate significant enhancement in the forecasting accuracy for a COVID-19 dataset, with a maximum improvement in forecasting accuracy by 64.58% and 59.18% (on average) over the GCN-LSTM model in the national level data, and 58.79% and 52.40% (on average) over the GCN-LSTM model in the state level data. Additionally, our proposed model outperforms a parallel study (AUG-NN) by 27.35% improvement of accuracy on average.
Improving Neural Networks for Time Series Forecasting using Data Augmentation and AutoML
Mar 05, 2021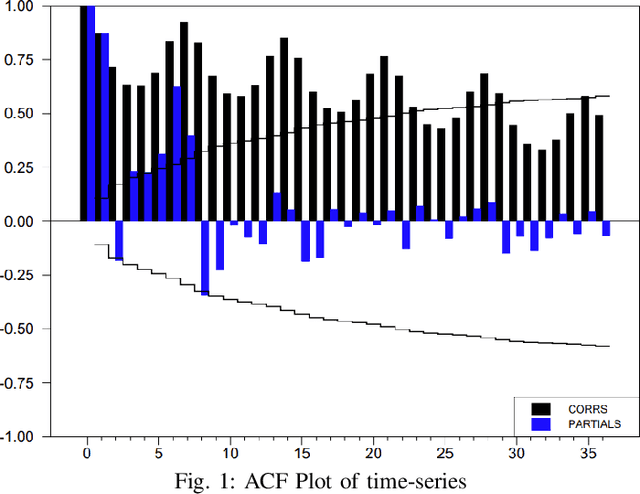
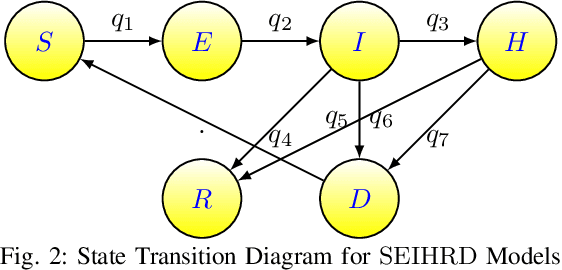
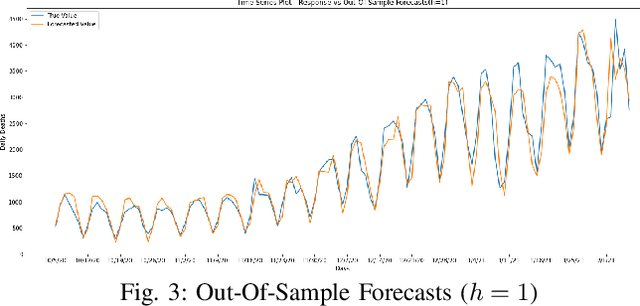
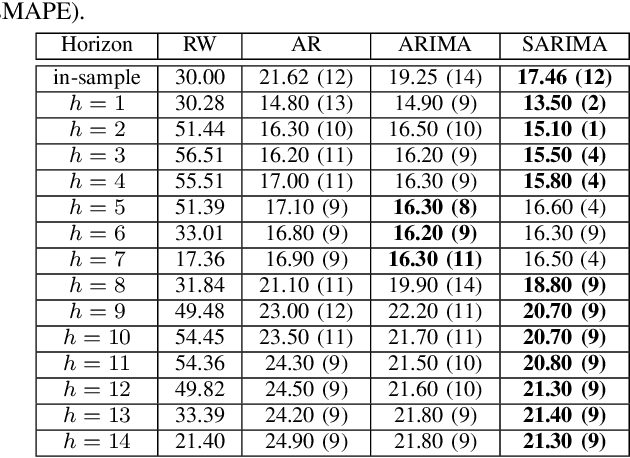
Statistical methods such as the Box-Jenkins method for time-series forecasting have been prominent since their development in 1970. Many researchers rely on such models as they can be efficiently estimated and also provide interpretability. However, advances in machine learning research indicate that neural networks can be powerful data modeling techniques, as they can give higher accuracy for a plethora of learning problems and datasets. In the past, they have been tried on time-series forecasting as well, but their overall results have not been significantly better than the statistical models especially for intermediate length times series data. Their modeling capacities are limited in cases where enough data may not be available to estimate the large number of parameters that these non-linear models require. This paper presents an easy to implement data augmentation method to significantly improve the performance of such networks. Our method, Augmented-Neural-Network, which involves using forecasts from statistical models, can help unlock the power of neural networks on intermediate length time-series and produces competitive results. It shows that data augmentation, when paired with Automated Machine Learning techniques such as Neural Architecture Search, can help to find the best neural architecture for a given time-series. Using the combination of these, demonstrates significant enhancement for two configurations of our technique for a COVID-19 dataset, improving forecasting accuracy by 19.90% and 11.43%, respectively, over the neural networks that do not use augmented data.
Occupancy Detection in Room Using Sensor Data
Jan 10, 2021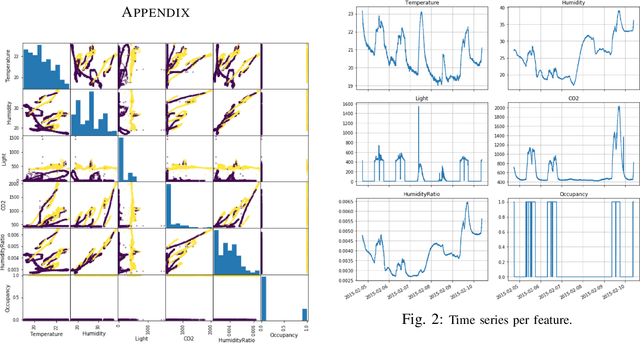
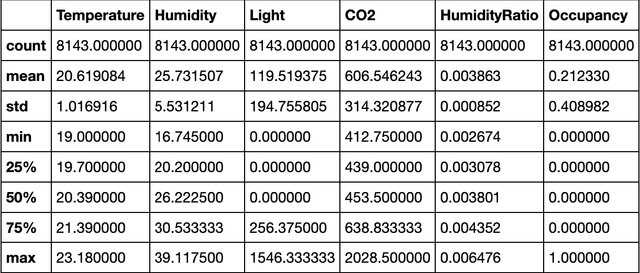
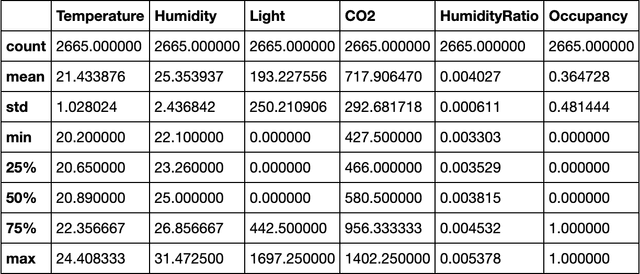
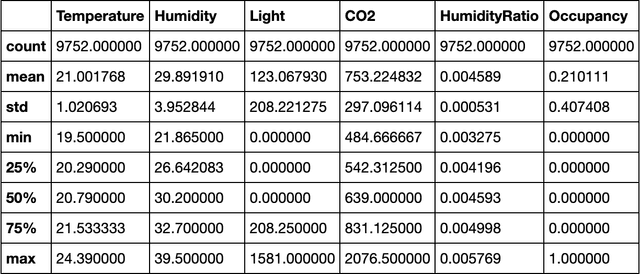
With the advent of Internet of Thing (IoT), and ubiquitous data collected every moment by either portable (smart phone) or fixed (sensor) devices, it is important to gain insights and meaningful information from the sensor data in context-aware computing environments. Many researches have been implemented by scientists in different fields, to analyze such data for the purpose of security, energy efficiency, building reliability and smart environments. One study, that many researchers are interested in, is to utilize Machine Learning techniques for occupancy detection where the aforementioned sensors gather information about the environment. This paper provides a solution to detect occupancy using sensor data by using and testing several variables. Additionally we show the analysis performed over the gathered data using Machine Learning and pattern recognition mechanisms is possible to determine the occupancy of indoor environments. Seven famous algorithms in Machine Learning, namely as Decision Tree, Random Forest, Gradient Boosting Machine, Logistic Regression, Naive Bayes, Kernelized SVM and K-Nearest Neighbors are tested and compared in this study.
Gaussian Function On Response Surface Estimation
Jan 04, 2021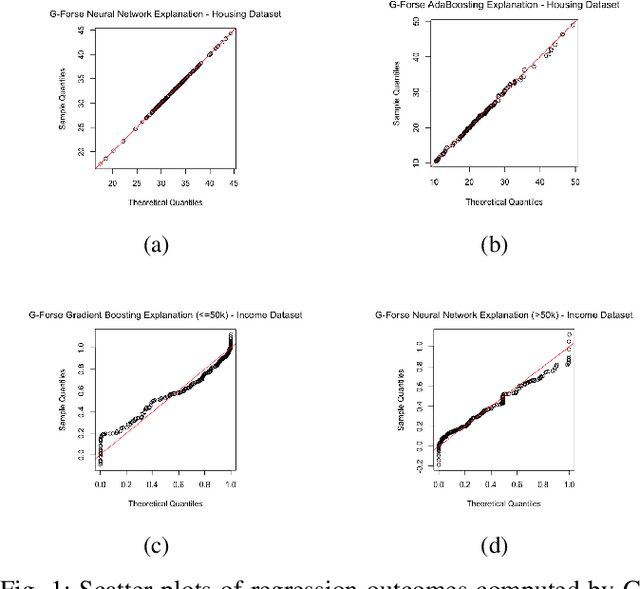
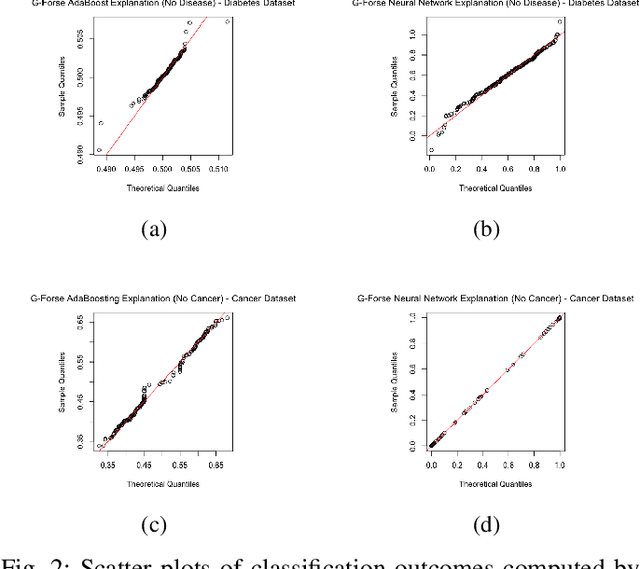
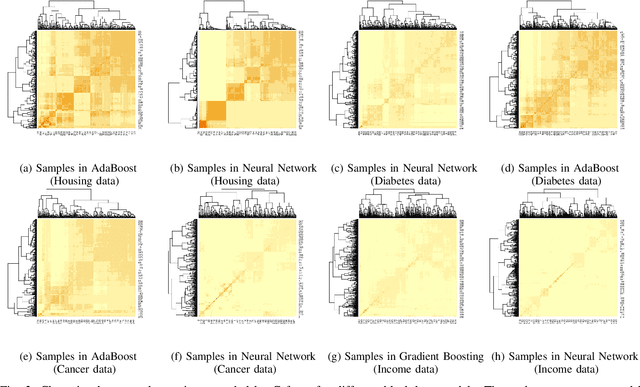
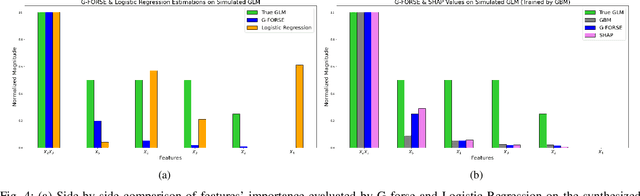
We propose a new framework for 2-D interpreting (features and samples) black-box machine learning models via a metamodeling technique, by which we study the output and input relationships of the underlying machine learning model. The metamodel can be estimated from data generated via a trained complex model by running the computer experiment on samples of data in the region of interest. We utilize a Gaussian process as a surrogate to capture the response surface of a complex model, in which we incorporate two parts in the process: interpolated values that are modeled by a stationary Gaussian process Z governed by a prior covariance function, and a mean function mu that captures the known trends in the underlying model. The optimization procedure for the variable importance parameter theta is to maximize the likelihood function. This theta corresponds to the correlation of individual variables with the target response. There is no need for any pre-assumed models since it depends on empirical observations. Experiments demonstrate the potential of the interpretable model through quantitative assessment of the predicted samples.
Video Contents Understanding using Deep Neural Networks
Apr 29, 2020
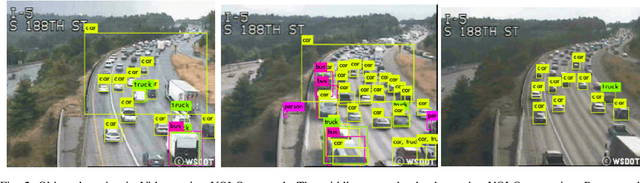

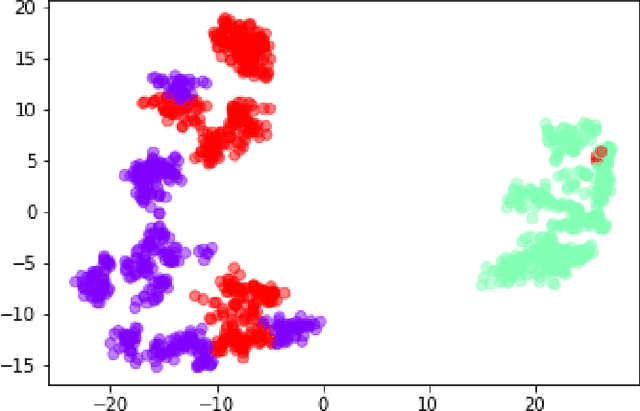
We propose a novel application of Transfer Learning to classify video-frame sequences over multiple classes. This is a pre-weighted model that does not require to train a fresh CNN. This representation is achieved with the advent of "deep neural network" (DNN), which is being studied these days by many researchers. We utilize the classical approaches for video classification task using object detection techniques for comparison, such as "Google Video Intelligence API" and this study will run experiments as to how those architectures would perform in foggy or rainy weather conditions. Experimental evaluation on video collections shows that the new proposed classifier achieves superior performance over existing solutions.
Stereotype-Free Classification of Fictitious Faces
Apr 29, 2020

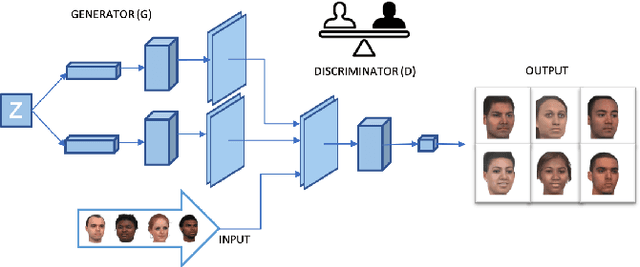
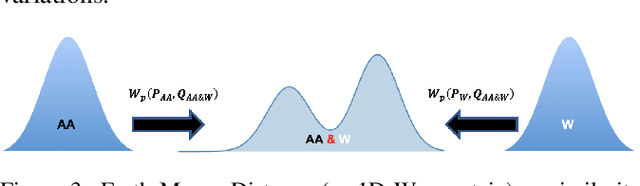
Equal Opportunity and Fairness are receiving increasing attention in artificial intelligence. Stereotyping is another source of discrimination, which yet has been unstudied in literature. GAN-made faces would be exposed to such discrimination, if they are classified by human perception. It is possible to eliminate the human impact on fictitious faces classification task by the use of statistical approaches. We present a novel approach through penalized regression to label stereotype-free GAN-generated synthetic unlabeled images. The proposed approach aids labeling new data (fictitious output images) by minimizing a penalized version of the least squares cost function between realistic pictures and target pictures.