 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Use of Video Captioning for Fostering Physical Activity
Apr 07, 2021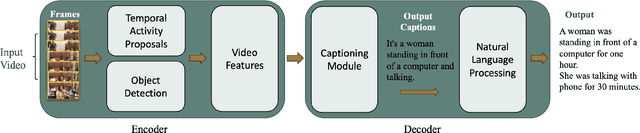
Video Captioning is considered to be one of the most challenging problems in the field of computer vision. Video Captioning involves the combination of different deep learning models to perform object detection, action detection, and localization by processing a sequence of image frames. It is crucial to consider the sequence of actions in a video in order to generate a meaningful description of the overall action event. A reliable, accurate, and real-time video captioning method can be used in many applications. However, this paper focuses on one application: video captioning for fostering and facilitating physical activities. In broad terms, the work can be considered to be assistive technology. Lack of physical activity appears to be increasingly widespread in many nations due to many factors, the most important being the convenience that technology has provided in workplaces. The adopted sedentary lifestyle is becoming a significant public health issue. Therefore, it is essential to incorporate more physical movements into our daily lives. Tracking one's daily physical activities would offer a base for comparison with activities performed in subsequent days. With the above in mind, this paper proposes a video captioning framework that aims to describe the activities in a video and estimate a person's daily physical activity level. This framework could potentially help people trace their daily movements to reduce an inactive lifestyle's health risks. The work presented in this paper is still in its infancy. The initial steps of the application are outlined in this paper. Based on our preliminary research, this project has great merit.
A Concise Review of Transfer Learning
Apr 05, 2021The availability of abundant labeled data in recent years led the researchers to introduce a methodology called transfer learning, which utilizes existing data in situations where there are difficulties in collecting new annotated data. Transfer learning aims to boost the performance of a target learner by applying another related source data. In contrast to the traditional machine learning and data mining techniques, which assume that the training and testing data lie from the same feature space and distribution, transfer learning can handle situations where there is a discrepancy between domains and distributions. These characteristics give the model the potential to utilize the available related source data and extend the underlying knowledge to the target task achieving better performance. This survey paper aims to give a concise review of traditional and current transfer learning settings, existing challenges, and related approaches.
A Brief Review of Domain Adaptation
Oct 07, 2020Classical machine learning assumes that the training and test sets come from the same distributions. Therefore, a model learned from the labeled training data is expected to perform well on the test data. However, This assumption may not always hold in real-world applications where the training and the test data fall from different distributions, due to many factors, e.g., collecting the training and test sets from different sources, or having an out-dated training set due to the change of data over time. In this case, there would be a discrepancy across domain distributions, and naively applying the trained model on the new dataset may cause degradation in the performance. Domain adaptation is a sub-field within machine learning that aims to cope with these types of problems by aligning the disparity between domains such that the trained model can be generalized into the domain of interest. This paper focuses on unsupervised domain adaptation, where the labels are only available in the source domain. It addresses the categorization of domain adaptation from different viewpoints. Besides, It presents some successful shallow and deep domain adaptation approaches that aim to deal with domain adaptation problems.
Video Contents Understanding using Deep Neural Networks
Apr 29, 2020
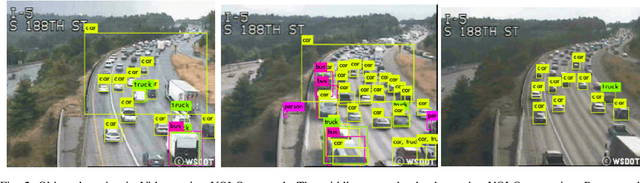

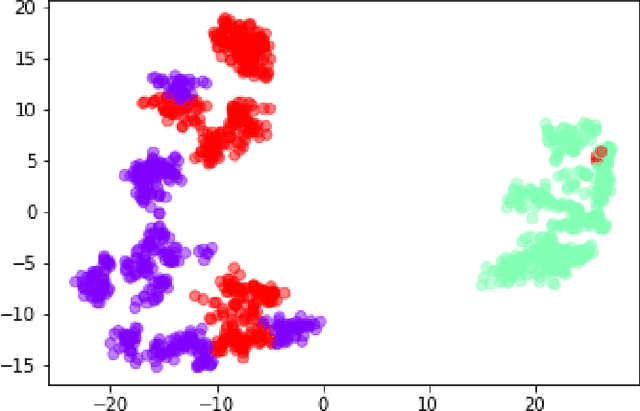
We propose a novel application of Transfer Learning to classify video-frame sequences over multiple classes. This is a pre-weighted model that does not require to train a fresh CNN. This representation is achieved with the advent of "deep neural network" (DNN), which is being studied these days by many researchers. We utilize the classical approaches for video classification task using object detection techniques for comparison, such as "Google Video Intelligence API" and this study will run experiments as to how those architectures would perform in foggy or rainy weather conditions. Experimental evaluation on video collections shows that the new proposed classifier achieves superior performance over existing solutions.