 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable AI in Orthopedics: Challenges, Opportunities, and Prospects
Aug 09, 2023
While artificial intelligence (AI) has made many successful applications in various domains, its adoption in healthcare lags a little bit behind other high-stakes settings. Several factors contribute to this slower uptake, including regulatory frameworks, patient privacy concerns, and data heterogeneity. However, one significant challenge that impedes the implementation of AI in healthcare, particularly in orthopedics, is the lack of explainability and interpretability around AI models. Addressing the challenge of explainable AI (XAI) in orthopedics requires developing AI models and algorithms that prioritize transparency and interpretability, allowing clinicians, surgeons, and patients to understand the contributing factors behind any AI-powered predictive or descriptive models. The current contribution outlines several key challenges and opportunities that manifest in XAI in orthopedic practice. This work emphasizes the need for interdisciplinary collaborations between AI practitioners, orthopedic specialists, and regulatory entities to establish standards and guidelines for the adoption of XAI in orthopedics.
Learning Unbiased Image Segmentation: A Case Study with Plain Knee Radiographs
Aug 08, 2023Automatic segmentation of knee bony anatomy is essential in orthopedics, and it has been around for several years in both pre-operative and post-operative settings. While deep learning algorithms have demonstrated exceptional performance in medical image analysis, the assessment of fairness and potential biases within these models remains limited. This study aims to revisit deep learning-powered knee-bony anatomy segmentation using plain radiographs to uncover visible gender and racial biases. The current contribution offers the potential to advance our understanding of biases, and it provides practical insights for researchers and practitioners in medical imaging. The proposed mitigation strategies mitigate gender and racial biases, ensuring fair and unbiased segmentation results. Furthermore, this work promotes equal access to accurate diagnoses and treatment outcomes for diverse patient populations, fostering equitable and inclusive healthcare provision.
Word Embedding Neural Networks to Advance Knee Osteoarthritis Research
Dec 22, 2022Osteoarthritis (OA) is the most prevalent chronic joint disease worldwide, where knee OA takes more than 80% of commonly affected joints. Knee OA is not a curable disease yet, and it affects large columns of patients, making it costly to patients and healthcare systems. Etiology, diagnosis, and treatment of knee OA might be argued by variability in its clinical and physical manifestations. Although knee OA carries a list of well-known terminology aiming to standardize the nomenclature of the diagnosis, prognosis, treatment, and clinical outcomes of the chronic joint disease, in practice there is a wide range of terminology associated with knee OA across different data sources, including but not limited to biomedical literature, clinical notes, healthcare literacy, and health-related social media. Among these data sources, the scientific articles published in the biomedical literature usually make a principled pipeline to study disease. Rapid yet, accurate text mining on large-scale scientific literature may discover novel knowledge and terminology to better understand knee OA and to improve the quality of knee OA diagnosis, prevention, and treatment. The present works aim to utilize artificial neural network strategies to automatically extract vocabularies associated with knee OA diseases. Our finding indicates the feasibility of developing word embedding neural networks for autonomous keyword extraction and abstraction of knee OA.
An Integrated Approach for Video Captioning and Applications
Jan 23, 2022



Physical computing infrastructure, data gathering, and algorithms have recently had significant advances to extract information from images and videos. The growth has been especially outstanding in image captioning and video captioning. However, most of the advancements in video captioning still take place in short videos. In this research, we caption longer videos only by using the keyframes, which are a small subset of the total video frames. Instead of processing thousands of frames, only a few frames are processed depending on the number of keyframes. There is a trade-off between the computation of many frames and the speed of the captioning process. The approach in this research is to allow the user to specify the trade-off between execution time and accuracy. In addition, we argue that linking images, videos, and natural language offers many practical benefits and immediate practical applications. From the modeling perspective, instead of designing and staging explicit algorithms to process videos and generate captions in complex processing pipelines, our contribution lies in designing hybrid deep learning architectures to apply in long videos by captioning video keyframes. We consider the technology and the methodology that we have developed as steps toward the applications discussed in this research.
Generative Adversarial Network Applications in Creating a Meta-Universe
Jan 23, 2022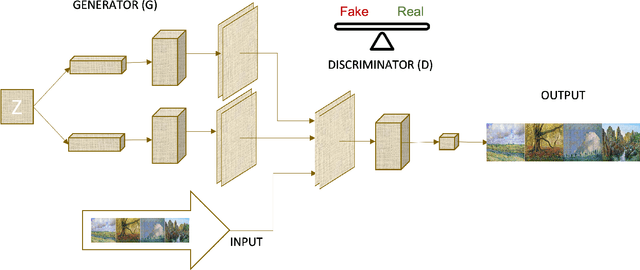


Generative Adversarial Networks (GANs) are machine learning methods that are used in many important and novel applications. For example, in imaging science, GANs are effectively utilized in generating image datasets, photographs of human faces, image and video captioning, image-to-image translation, text-to-image translation, video prediction, and 3D object generation to name a few. In this paper, we discuss how GANs can be used to create an artificial world. More specifically, we discuss how GANs help to describe an image utilizing image/video captioning methods and how to translate the image to a new image using image-to-image translation frameworks in a theme we desire. We articulate how GANs impact creating a customized world.
Automatic Generation of Descriptive Titles for Video Clips Using Deep Learning
Apr 07, 2021


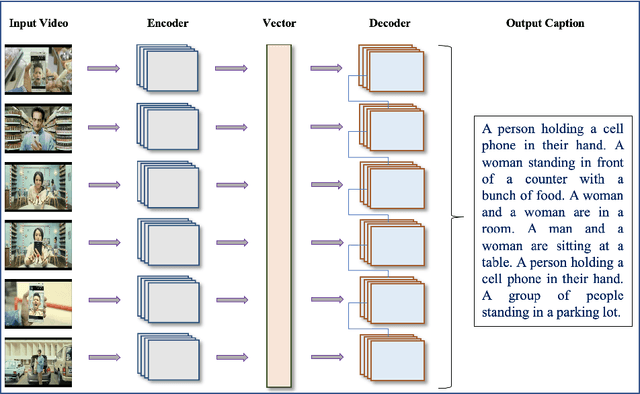
Over the last decade, the use of Deep Learning in many applications produced results that are comparable to and in some cases surpassing human expert performance. The application domains include diagnosing diseases, finance, agriculture, search engines, robot vision, and many others. In this paper, we are proposing an architecture that utilizes image/video captioning methods and Natural Language Processing systems to generate a title and a concise abstract for a video. Such a system can potentially be utilized in many application domains, including, the cinema industry, video search engines, security surveillance, video databases/warehouses, data centers, and others. The proposed system functions and operates as followed: it reads a video; representative image frames are identified and selected; the image frames are captioned; NLP is applied to all generated captions together with text summarization; and finally, a title and an abstract are generated for the video. All functions are performed automatically. Preliminary results are provided in this paper using publicly available datasets. This paper is not concerned about the efficiency of the system at the execution time. We hope to be able to address execution efficiency issues in our subsequent publications.
The Use of Video Captioning for Fostering Physical Activity
Apr 07, 2021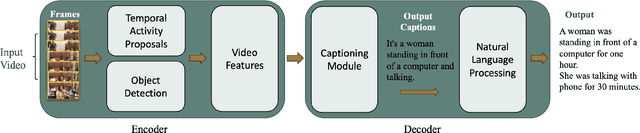
Video Captioning is considered to be one of the most challenging problems in the field of computer vision. Video Captioning involves the combination of different deep learning models to perform object detection, action detection, and localization by processing a sequence of image frames. It is crucial to consider the sequence of actions in a video in order to generate a meaningful description of the overall action event. A reliable, accurate, and real-time video captioning method can be used in many applications. However, this paper focuses on one application: video captioning for fostering and facilitating physical activities. In broad terms, the work can be considered to be assistive technology. Lack of physical activity appears to be increasingly widespread in many nations due to many factors, the most important being the convenience that technology has provided in workplaces. The adopted sedentary lifestyle is becoming a significant public health issue. Therefore, it is essential to incorporate more physical movements into our daily lives. Tracking one's daily physical activities would offer a base for comparison with activities performed in subsequent days. With the above in mind, this paper proposes a video captioning framework that aims to describe the activities in a video and estimate a person's daily physical activity level. This framework could potentially help people trace their daily movements to reduce an inactive lifestyle's health risks. The work presented in this paper is still in its infancy. The initial steps of the application are outlined in this paper. Based on our preliminary research, this project has great merit.
Stereotype-Free Classification of Fictitious Faces
Apr 29, 2020

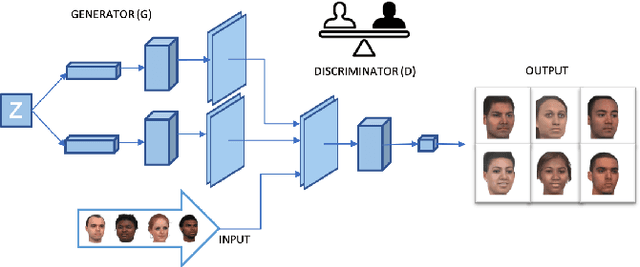
Equal Opportunity and Fairness are receiving increasing attention in artificial intelligence. Stereotyping is another source of discrimination, which yet has been unstudied in literature. GAN-made faces would be exposed to such discrimination, if they are classified by human perception. It is possible to eliminate the human impact on fictitious faces classification task by the use of statistical approaches. We present a novel approach through penalized regression to label stereotype-free GAN-generated synthetic unlabeled images. The proposed approach aids labeling new data (fictitious output images) by minimizing a penalized version of the least squares cost function between realistic pictures and target pictures.