 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Generation of Descriptive Titles for Video Clips Using Deep Learning
Paper and Code



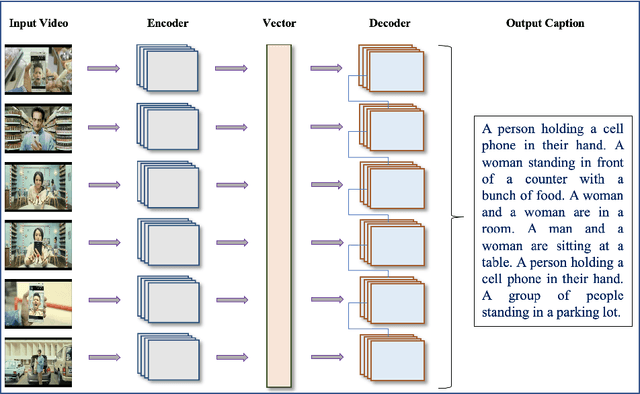
Over the last decade, the use of Deep Learning in many applications produced results that are comparable to and in some cases surpassing human expert performance. The application domains include diagnosing diseases, finance, agriculture, search engines, robot vision, and many others. In this paper, we are proposing an architecture that utilizes image/video captioning methods and Natural Language Processing systems to generate a title and a concise abstract for a video. Such a system can potentially be utilized in many application domains, including, the cinema industry, video search engines, security surveillance, video databases/warehouses, data centers, and others. The proposed system functions and operates as followed: it reads a video; representative image frames are identified and selected; the image frames are captioned; NLP is applied to all generated captions together with text summarization; and finally, a title and an abstract are generated for the video. All functions are performed automatically. Preliminary results are provided in this paper using publicly available datasets. This paper is not concerned about the efficiency of the system at the execution time. We hope to be able to address execution efficiency issues in our subsequent publications.