 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting from Predictions
Paper and Code
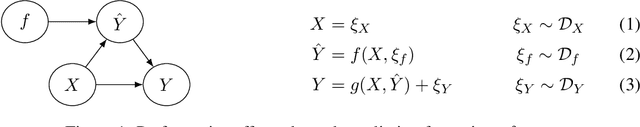
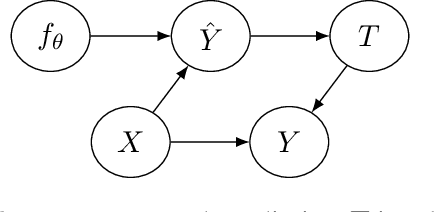
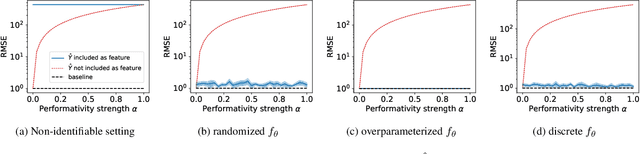
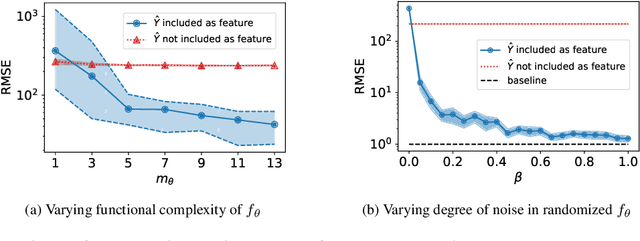
Predictions about people, such as their expected educational achievement or their credit risk, can be performative and shape the outcome that they aim to predict. Understanding the causal effect of these predictions on the eventual outcomes is crucial for foreseeing the implications of future predictive models and selecting which models to deploy. However, this causal estimation task poses unique challenges: model predictions are usually deterministic functions of input features and highly correlated with outcomes, which can make the causal effects of predictions impossible to disentangle from the direct effect of the covariates. We study this problem through the lens of causal identifiability, and despite the hardness of this problem in full generality, we highlight three natural scenarios where the causal effect of predictions on outcomes can be identified from observational data: randomization in predictions or prediction-based decisions, overparameterization of the predictive model deployed during data collection, and discrete prediction outputs. We show empirically that, under suitable identifiability conditions, standard variants of supervised learning that predict from predictions can find transferable functional relationships between features, predictions, and outcomes, allowing for conclusions about newly deployed prediction models. Our positive results fundamentally rely on model predictions being recorded during data collection, bringing forward the importance of rethinking standard data collection practices to enable progress towards a better understanding of social outcomes and performative feedback loops.