 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerMod: Perceptually Grounded Voice Modification with Latent Diffusion Models
Paper and Code



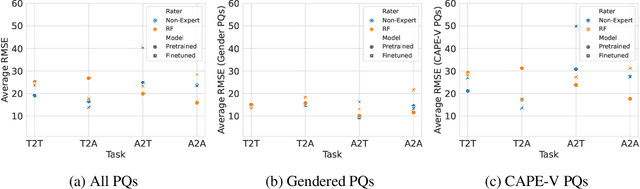
Perceptual modification of voice is an elusive goal. While non-experts can modify an image or sentence perceptually with available tools, it is not clear how to similarly modify speech along perceptual axes. Voice conversion does make it possible to convert one voice to another, but these modifications are handled by black box models, and the specifics of what perceptual qualities to modify and how to modify them are unclear. Towards allowing greater perceptual control over voice, we introduce PerMod, a conditional latent diffusion model that takes in an input voice and a perceptual qualities vector, and produces a voice with the matching perceptual qualities. Unlike prior work, PerMod generates a new voice corresponding to specific perceptual modifications. Evaluating perceptual quality vectors with RMSE from both human and predicted labels, we demonstrate that PerMod produces voices with the desired perceptual qualities for typical voices, but performs poorly on atypical voices.