 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Prototypical Part Networks with Reward Reweighing, Reselection, and Retraining
Paper and Code
Jul 08, 2023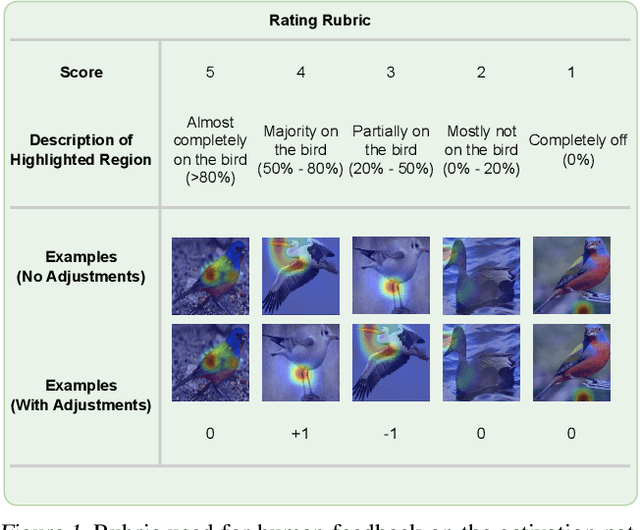
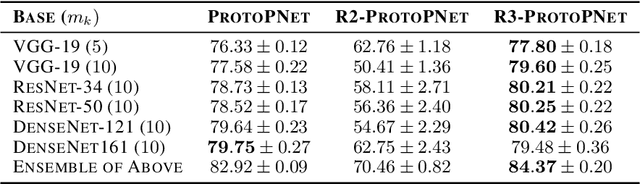

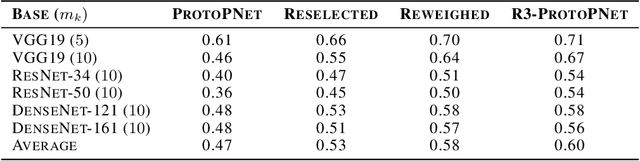
In recent years, work has gone into developing deep interpretable methods for image classification that clearly attributes a model's output to specific features of the data. One such of these methods is the prototypical part network (ProtoPNet), which attempts to classify images based on meaningful parts of the input. While this method results in interpretable classifications, this method often learns to classify from spurious or inconsistent parts of the image. Hoping to remedy this, we take inspiration from the recent developments in Reinforcement Learning with Human Feedback (RLHF) to fine-tune these prototypes. By collecting human annotations of prototypes quality via a 1-5 scale on the CUB-200-2011 dataset, we construct a reward model that learns to identify non-spurious prototypes. In place of a full RL update, we propose the reweighted, reselected, and retrained prototypical part network (R3-ProtoPNet), which adds an additional three steps to the ProtoPNet training loop. The first two steps are reward-based reweighting and reselection, which align prototypes with human feedback. The final step is retraining to realign the model's features with the updated prototypes. We find that R3-ProtoPNet improves the overall consistency and meaningfulness of the prototypes, but lower the test predictive accuracy when used independently. When multiple R3-ProtoPNets are incorporated into an ensemble, we find an increase in test predictive performance while maintaining interpretability.