 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCiwaGAN: Articulatory information exchange
Sep 14, 2023



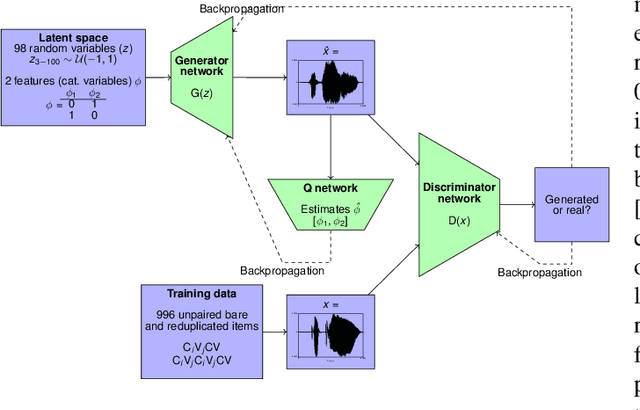
Humans encode information into sounds by controlling articulators and decode information from sounds using the auditory apparatus. This paper introduces CiwaGAN, a model of human spoken language acquisition that combines unsupervised articulatory modeling with an unsupervised model of information exchange through the auditory modality. While prior research includes unsupervised articulatory modeling and information exchange separately, our model is the first to combine the two components. The paper also proposes an improved articulatory model with more interpretable internal representations. The proposed CiwaGAN model is the most realistic approximation of human spoken language acquisition using deep learning. As such, it is useful for cognitively plausible simulations of the human speech act.
Articulation GAN: Unsupervised modeling of articulatory learning
Oct 27, 2022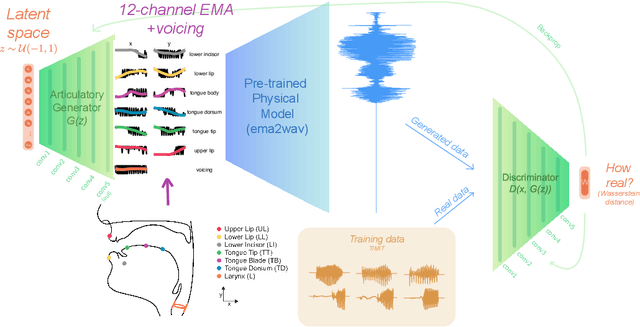

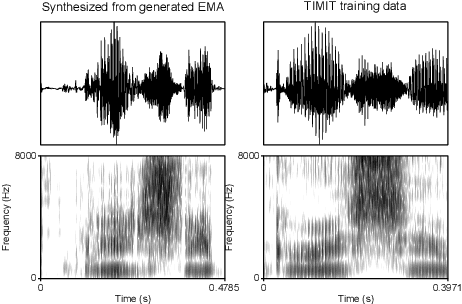
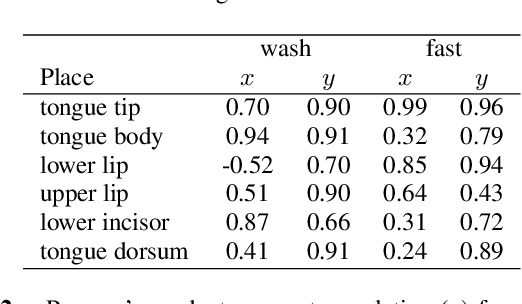
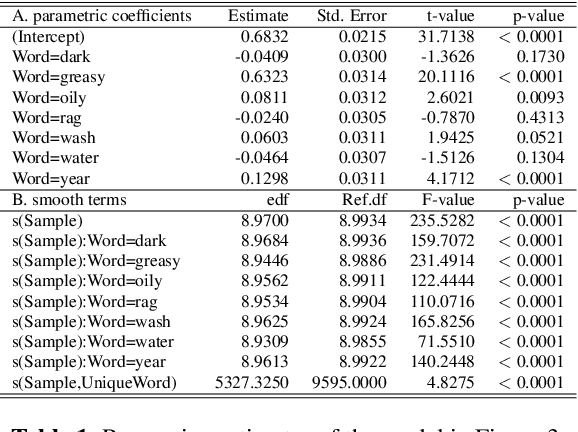
Generative deep neural networks are widely used for speech synthesis, but most existing models directly generate waveforms or spectral outputs. Humans, however, produce speech by controlling articulators, which results in the production of speech sounds through physical properties of sound propagation. We propose a new unsupervised generative model of speech production/synthesis that includes articulatory representations and thus more closely mimics human speech production. We introduce the Articulatory Generator to the Generative Adversarial Network paradigm. The Articulatory Generator needs to learn to generate articulatory representations (electromagnetic articulography or EMA) in a fully unsupervised manner without ever accessing EMA data. A separate pre-trained physical model (ema2wav) then transforms the generated EMA representations to speech waveforms, which get sent to the Discriminator for evaluation. Articulatory analysis of the generated EMA representations suggests that the network learns to control articulators in a manner that closely follows human articulators during speech production. Acoustic analysis of the outputs suggest that the network learns to generate words that are part of training data as well as novel innovative words that are absent from training data. Our proposed architecture thus allows modeling of articulatory learning with deep neural networks from raw audio inputs in a fully unsupervised manner. We additionally discuss implications of articulatory representations for cognitive models of human language and speech technology in general.
Modeling speech recognition and synthesis simultaneously: Encoding and decoding lexical and sublexical semantic information into speech with no direct access to speech data
Mar 29, 2022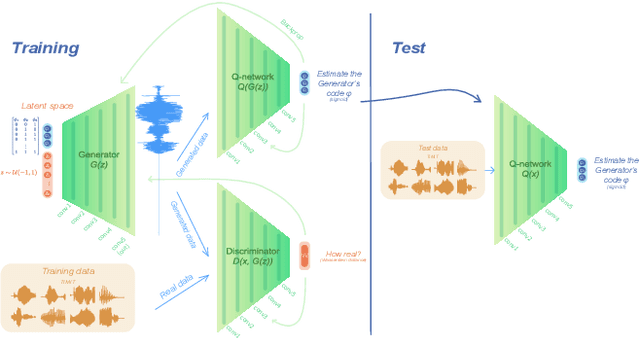
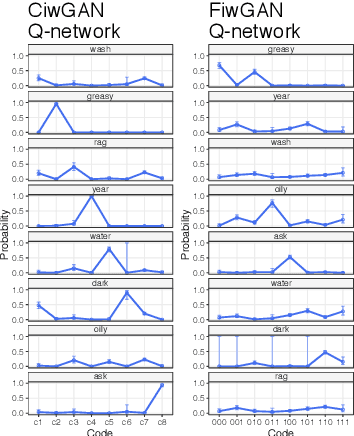
Human speakers encode information into raw speech which is then decoded by the listeners. This complex relationship between encoding (production) and decoding (perception) is often modeled separately. Here, we test how encoding and decoding of lexical semantic information can emerge automatically from raw speech in unsupervised generative deep convolutional networks that combine the production and perception principles of speech. We introduce, to our knowledge, the most challenging objective in unsupervised lexical learning: a network that must learn unique representations for lexical items with no direct access to training data. We train several models (ciwGAN and fiwGAN arXiv:2006.02951) and test how the networks classify acoustic lexical items in unobserved test data. Strong evidence in favor of lexical learning and a causal relationship between latent codes and meaningful sublexical units emerge. The architecture that combines the production and perception principles is thus able to learn to decode unique information from raw acoustic data without accessing real training data directly. We propose a technique to explore lexical (holistic) and sublexical (featural) learned representations in the classifier network. The results bear implications for unsupervised speech technology, as well as for unsupervised semantic modeling as language models increasingly bypass text and operate from raw acoustics.
Interpreting intermediate convolutional layers in unsupervised acoustic word classification
Oct 05, 2021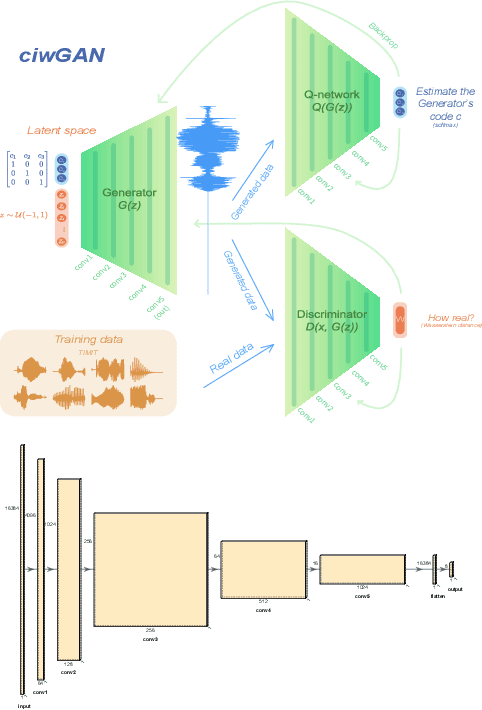
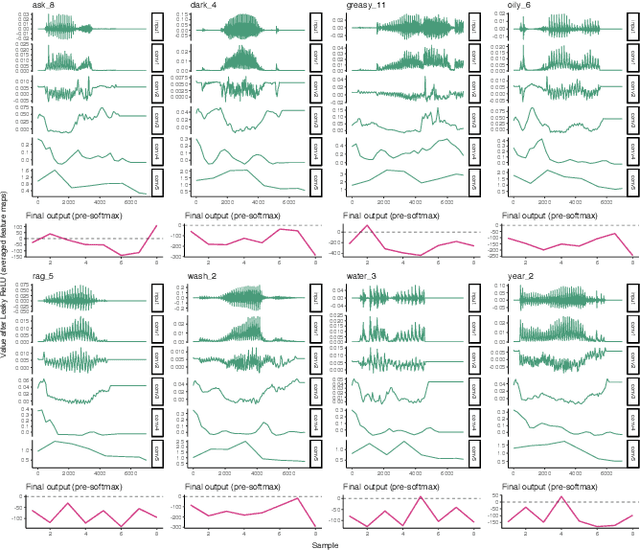
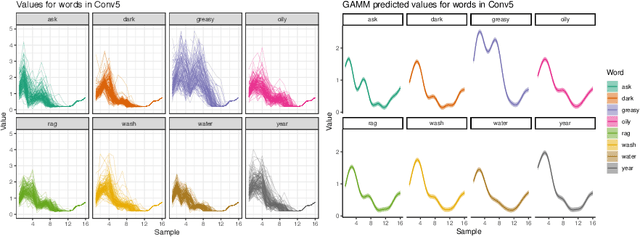
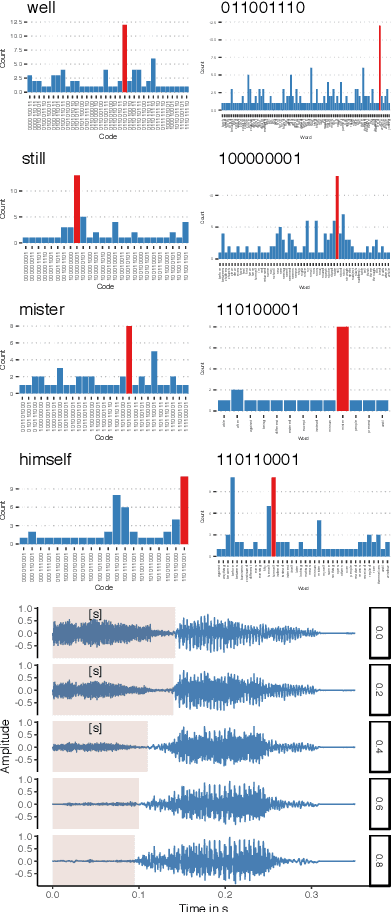
Understanding how deep convolutional neural networks classify data has been subject to extensive research. This paper proposes a technique to visualize and interpret intermediate layers of unsupervised deep convolutional neural networks by averaging over individual feature maps in each convolutional layer and inferring underlying distributions of words with non-linear regression techniques. A GAN-based architecture (ciwGAN arXiv:2006.02951) that includes three convolutional networks (a Generator, a Discriminator, and a classifier) was trained on unlabeled sliced lexical items from TIMIT. The training results in a deep convolutional network that learns to classify words into discrete classes only from the requirement of the Generator to output informative data. The classifier network has no access to the training data -- only to the generated data -- which means lexical learning needs to emerge in a fully unsupervised manner. We propose a technique to visualize individual convolutional layers in the classifier that yields highly informative time-series data for each convolutional layer and apply it to unobserved test data. Using non-linear regression, we infer underlying distributions for each word which allows us to analyze both absolute values and shapes of individual words at different convolutional layers as well as perform hypothesis testing on their acoustic properties. The technique also allows us to tests individual phone contrasts and how they are represented at each layer.
Interpreting intermediate convolutional layers of CNNs trained on raw speech
Apr 21, 2021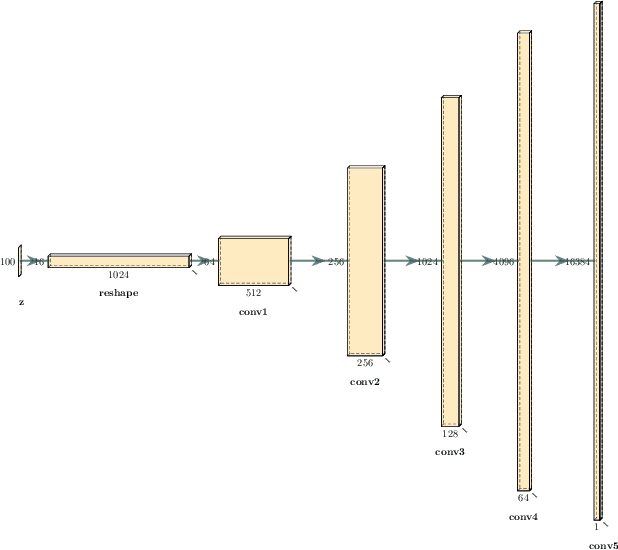
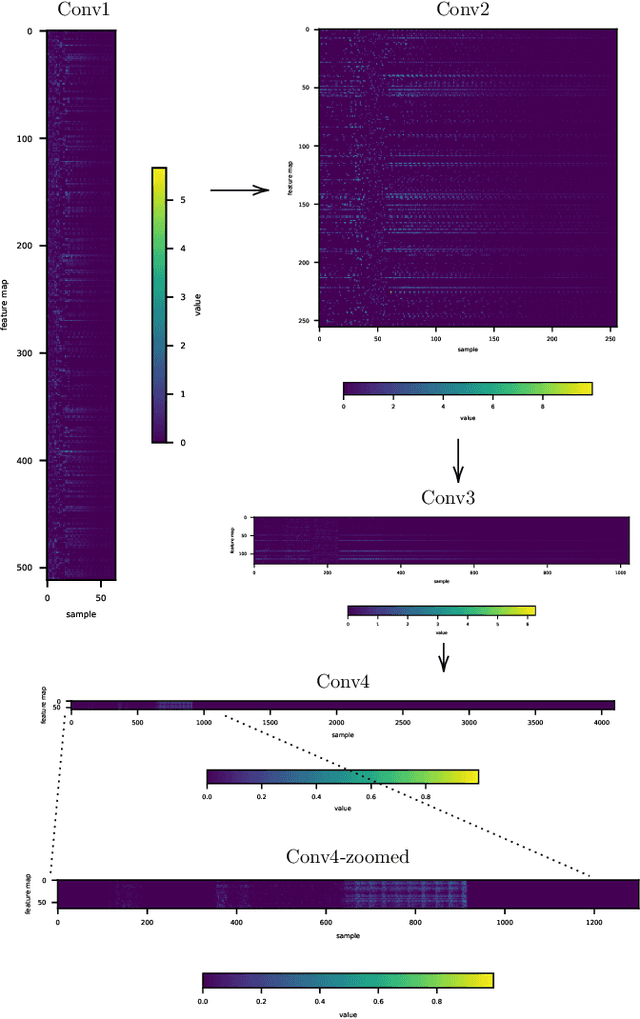
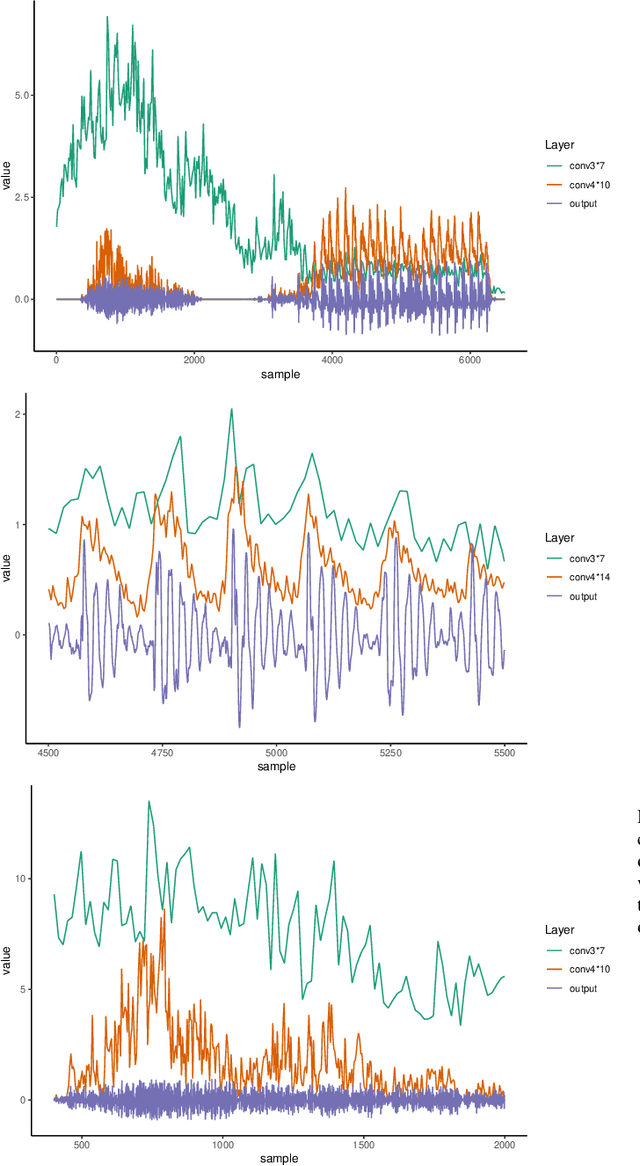
This paper presents a technique to interpret and visualize intermediate layers in CNNs trained on raw speech data in an unsupervised manner. We show that averaging over feature maps after ReLU activation in each convolutional layer yields interpretable time-series data. The proposed technique enables acoustic analysis of intermediate convolutional layers. To uncover how meaningful representation in speech gets encoded in intermediate layers of CNNs, we manipulate individual latent variables to marginal levels outside of the training range. We train and probe internal representations on two models -- a bare WaveGAN architecture and a ciwGAN extension which forces the Generator to output informative data and results in emergence of linguistically meaningful representations. Interpretation and visualization is performed for three basic acoustic properties of speech: periodic vibration (corresponding to vowels), aperiodic noise vibration (corresponding to fricatives), and silence (corresponding to stops). We also argue that the proposed technique allows acoustic analysis of intermediate layers that parallels the acoustic analysis of human speech data: we can extract F0, intensity, duration, formants, and other acoustic properties from intermediate layers in order to test where and how CNNs encode various types of information. The models are trained on two speech processes with different degrees of complexity: a simple presence of [s] and a computationally complex presence of reduplication (copied material). Observing the causal effect between interpolation and the resulting changes in intermediate layers can reveal how individual variables get transformed into spikes in activation in intermediate layers. Using the proposed technique, we can analyze how linguistically meaningful units in speech get encoded in different convolutional layers.