 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArticulation GAN: Unsupervised modeling of articulatory learning
Oct 27, 2022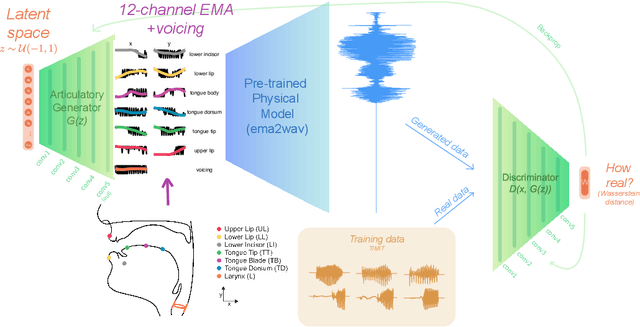

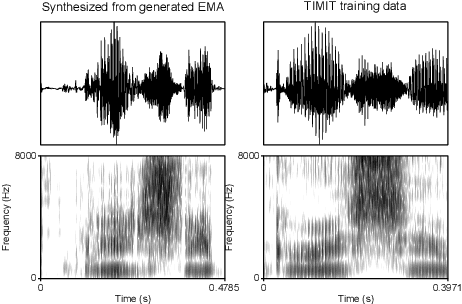
Generative deep neural networks are widely used for speech synthesis, but most existing models directly generate waveforms or spectral outputs. Humans, however, produce speech by controlling articulators, which results in the production of speech sounds through physical properties of sound propagation. We propose a new unsupervised generative model of speech production/synthesis that includes articulatory representations and thus more closely mimics human speech production. We introduce the Articulatory Generator to the Generative Adversarial Network paradigm. The Articulatory Generator needs to learn to generate articulatory representations (electromagnetic articulography or EMA) in a fully unsupervised manner without ever accessing EMA data. A separate pre-trained physical model (ema2wav) then transforms the generated EMA representations to speech waveforms, which get sent to the Discriminator for evaluation. Articulatory analysis of the generated EMA representations suggests that the network learns to control articulators in a manner that closely follows human articulators during speech production. Acoustic analysis of the outputs suggest that the network learns to generate words that are part of training data as well as novel innovative words that are absent from training data. Our proposed architecture thus allows modeling of articulatory learning with deep neural networks from raw audio inputs in a fully unsupervised manner. We additionally discuss implications of articulatory representations for cognitive models of human language and speech technology in general.