 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYOLO-Stutter: End-to-end Region-Wise Speech Dysfluency Detection
Sep 09, 2024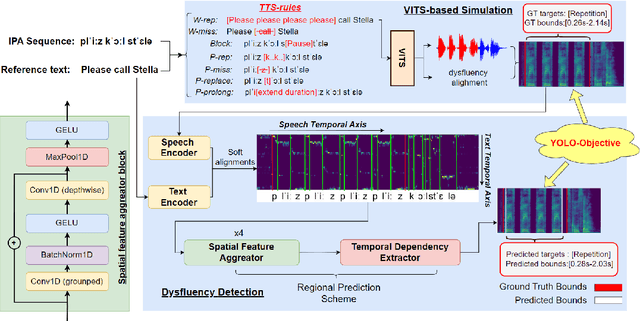
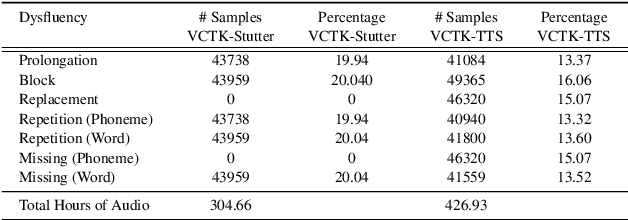
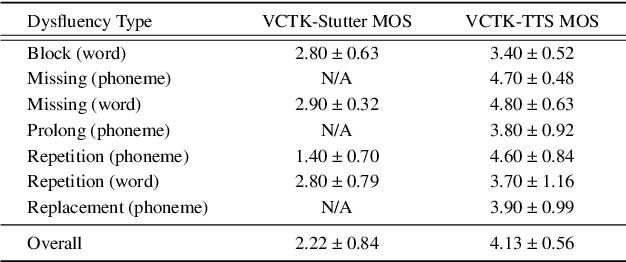

Dysfluent speech detection is the bottleneck for disordered speech analysis and spoken language learning. Current state-of-the-art models are governed by rule-based systems which lack efficiency and robustness, and are sensitive to template design. In this paper, we propose YOLO-Stutter: a first end-to-end method that detects dysfluencies in a time-accurate manner. YOLO-Stutter takes imperfect speech-text alignment as input, followed by a spatial feature aggregator, and a temporal dependency extractor to perform region-wise boundary and class predictions. We also introduce two dysfluency corpus, VCTK-Stutter and VCTK-TTS, that simulate natural spoken dysfluencies including repetition, block, missing, replacement, and prolongation. Our end-to-end method achieves state-of-the-art performance with a minimum number of trainable parameters for on both simulated data and real aphasia speech. Code and datasets are open-sourced at https://github.com/rorizzz/YOLO-Stutter
Unconstrained Dysfluency Modeling for Dysfluent Speech Transcription and Detection
Dec 20, 2023Dysfluent speech modeling requires time-accurate and silence-aware transcription at both the word-level and phonetic-level. However, current research in dysfluency modeling primarily focuses on either transcription or detection, and the performance of each aspect remains limited. In this work, we present an unconstrained dysfluency modeling (UDM) approach that addresses both transcription and detection in an automatic and hierarchical manner. UDM eliminates the need for extensive manual annotation by providing a comprehensive solution. Furthermore, we introduce a simulated dysfluent dataset called VCTK++ to enhance the capabilities of UDM in phonetic transcription. Our experimental results demonstrate the effectiveness and robustness of our proposed methods in both transcription and detection tasks.