 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingAug: Data Augmentation for Singing Voice Synthesis with Cycle-consistent Training Strategy
Paper and Code
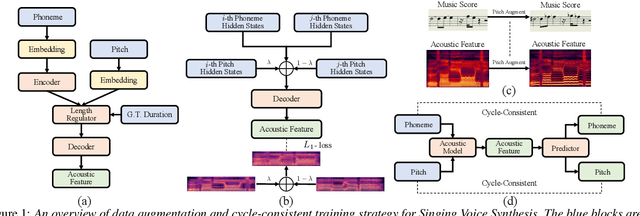
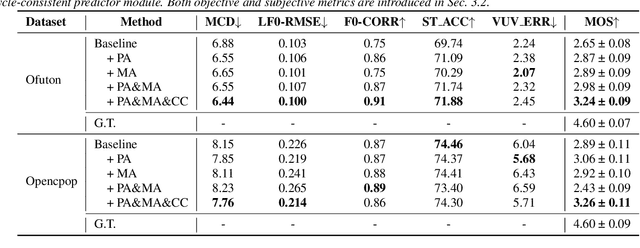
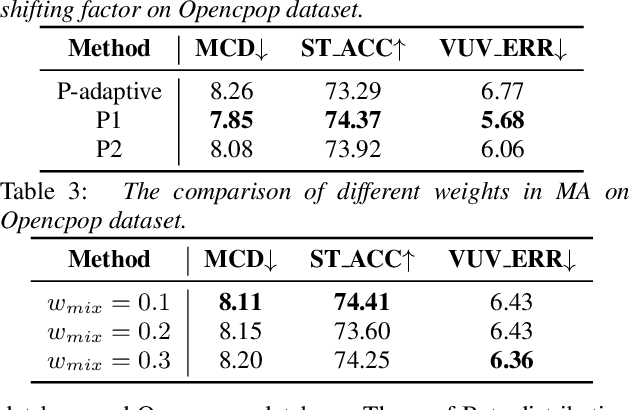
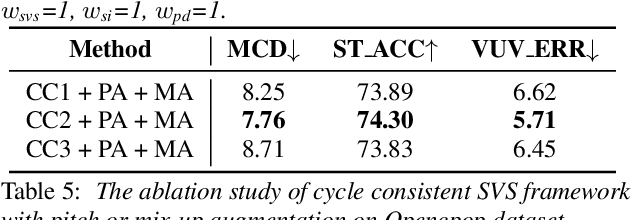
Deep learning based singing voice synthesis (SVS) systems have been demonstrated to flexibly generate singing with better qualities, compared to conventional statistical parametric based methods. However, neural systems are generally data-hungry and have difficulty to reach reasonable singing quality with limited public available training data. In this work, we explore different data augmentation methods to boost the training of SVS systems, including several strategies customized to SVS based on pitch augmentation and mix-up augmentation. To further stabilize the training, we introduce the cycle-consistent training strategy. Extensive experiments on two public singing databases demonstrate that our proposed augmentation methods and the stabilizing training strategy can significantly improve the performance on both objective and subjective evaluations.