 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLight 'em Up: Enabling Few-Shot Low-Light 3D Gaussian Splatting with Multi-Scale Explicit Retinex Illumination Decoupling
Apr 27, 2026Full 360$^\circ$ novel view synthesis under low-light conditions remains challenging. Insufficient illumination, noise amplification, and view-dependent photometric inconsistencies prevent existing methods from jointly preserving geometric consistency and photorealism. Unsupervised approaches often exhibit color drift under large viewpoint variations, while supervised low-light enhancement models, though effective for 2D tasks, struggle to generalize to new scenes and typically require retraining. To address this issue, we propose MERID-GS, a Multi-Scale Explicit Retinex Illumination-Decoupled Gaussian framework for low-light 360$^\circ$ synthesis. Based on Retinex theory, the method explicitly separates illumination and reflectance, and suppresses noise propagation while enhancing dark-region structures via a learnable gain and Illumination-State-Guided Frequency Gating. Combined with lightweight Reflection Head and 3D Gaussian Splatting, MERID-GS adapts to new scenes with only a few shots and enables stable low-light novel view synthesis from sparse-view observations. In addition, we construct a low-light multi-view dataset covering full 360$^\circ$ scenes for joint evaluation. Thorough experiments across multiple datasets in this area demonstrate that MERID-GS achieves SOTA performance, exhibiting superior cross-scene generalization and view consistency. The source code and pre-trained models are available at https://github.com/YhuoyuH/MERID-GS..
Beyond Shadows: A Large-Scale Benchmark and Multi-Stage Framework for High-Fidelity Facial Shadow Removal
Jan 27, 2026Facial shadows often degrade image quality and the performance of vision algorithms. Existing methods struggle to remove shadows while preserving texture, especially under complex lighting conditions, and they lack real-world paired datasets for training. We present the Augmented Shadow Face in the Wild (ASFW) dataset, the first large-scale real-world dataset for facial shadow removal, containing 1,081 paired shadow and shadow-free images created via a professional Photoshop workflow. ASFW offers photorealistic shadow variations and accurate ground truths, bridging the gap between synthetic and real domains. Deep models trained on ASFW demonstrate improved shadow removal in real-world conditions. We also introduce the Face Shadow Eraser (FSE) method to showcase the effectiveness of the dataset. Experiments demonstrate that ASFW enhances the performance of facial shadow removal models, setting new standards for this task.
LensNet: An End-to-End Learning Framework for Empirical Point Spread Function Modeling and Lensless Imaging Reconstruction
May 03, 2025


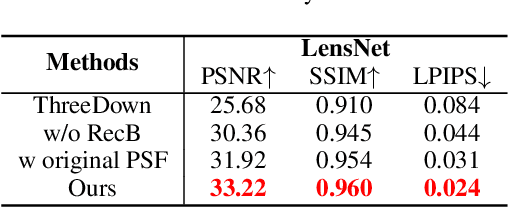
Lensless imaging stands out as a promising alternative to conventional lens-based systems, particularly in scenarios demanding ultracompact form factors and cost-effective architectures. However, such systems are fundamentally governed by the Point Spread Function (PSF), which dictates how a point source contributes to the final captured signal. Traditional lensless techniques often require explicit calibrations and extensive pre-processing, relying on static or approximate PSF models. These rigid strategies can result in limited adaptability to real-world challenges, including noise, system imperfections, and dynamic scene variations, thus impeding high-fidelity reconstruction. In this paper, we propose LensNet, an end-to-end deep learning framework that integrates spatial-domain and frequency-domain representations in a unified pipeline. Central to our approach is a learnable Coded Mask Simulator (CMS) that enables dynamic, data-driven estimation of the PSF during training, effectively mitigating the shortcomings of fixed or sparsely calibrated kernels. By embedding a Wiener filtering component, LensNet refines global structure and restores fine-scale details, thus alleviating the dependency on multiple handcrafted pre-processing steps. Extensive experiments demonstrate LensNet's robust performance and superior reconstruction quality compared to state-of-the-art methods, particularly in preserving high-frequency details and attenuating noise. The proposed framework establishes a novel convergence between physics-based modeling and data-driven learning, paving the way for more accurate, flexible, and practical lensless imaging solutions for applications ranging from miniature sensors to medical diagnostics. The link of code is https://github.com/baijiesong/Lensnet.
DLEN: Dual Branch of Transformer for Low-Light Image Enhancement in Dual Domains
Jan 21, 2025



Low-light image enhancement (LLE) aims to improve the visual quality of images captured in poorly lit conditions, which often suffer from low brightness, low contrast, noise, and color distortions. These issues hinder the performance of computer vision tasks such as object detection, facial recognition, and autonomous driving.Traditional enhancement techniques, such as multi-scale fusion and histogram equalization, fail to preserve fine details and often struggle with maintaining the natural appearance of enhanced images under complex lighting conditions. Although the Retinex theory provides a foundation for image decomposition, it often amplifies noise, leading to suboptimal image quality. In this paper, we propose the Dual Light Enhance Network (DLEN), a novel architecture that incorporates two distinct attention mechanisms, considering both spatial and frequency domains. Our model introduces a learnable wavelet transform module in the illumination estimation phase, preserving high- and low-frequency components to enhance edge and texture details. Additionally, we design a dual-branch structure that leverages the power of the Transformer architecture to enhance both the illumination and structural components of the image.Through extensive experiments, our model outperforms state-of-the-art methods on standard benchmarks.Code is available here: https://github.com/LaLaLoXX/DLEN
Retinexmamba: Retinex-based Mamba for Low-light Image Enhancement
May 06, 2024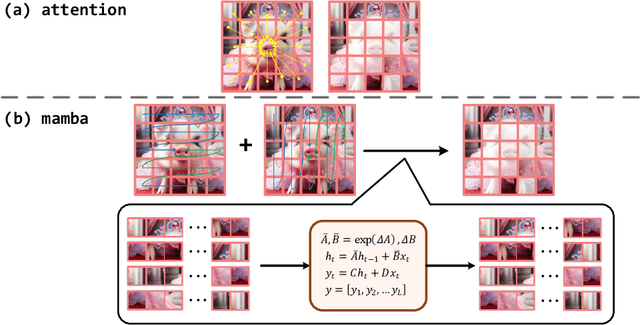
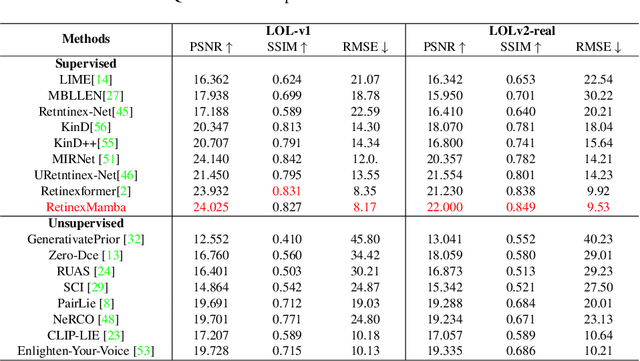
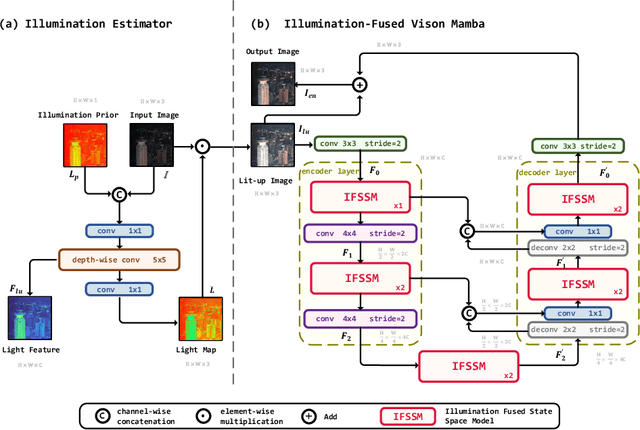
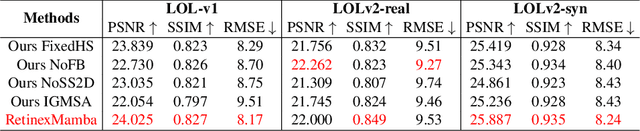
In the field of low-light image enhancement, both traditional Retinex methods and advanced deep learning techniques such as Retinexformer have shown distinct advantages and limitations. Traditional Retinex methods, designed to mimic the human eye's perception of brightness and color, decompose images into illumination and reflection components but struggle with noise management and detail preservation under low light conditions. Retinexformer enhances illumination estimation through traditional self-attention mechanisms, but faces challenges with insufficient interpretability and suboptimal enhancement effects. To overcome these limitations, this paper introduces the RetinexMamba architecture. RetinexMamba not only captures the physical intuitiveness of traditional Retinex methods but also integrates the deep learning framework of Retinexformer, leveraging the computational efficiency of State Space Models (SSMs) to enhance processing speed. This architecture features innovative illumination estimators and damage restorer mechanisms that maintain image quality during enhancement. Moreover, RetinexMamba replaces the IG-MSA (Illumination-Guided Multi-Head Attention) in Retinexformer with a Fused-Attention mechanism, improving the model's interpretability. Experimental evaluations on the LOL dataset show that RetinexMamba outperforms existing deep learning approaches based on Retinex theory in both quantitative and qualitative metrics, confirming its effectiveness and superiority in enhancing low-light images.