 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetinexmamba: Retinex-based Mamba for Low-light Image Enhancement
Paper and Code
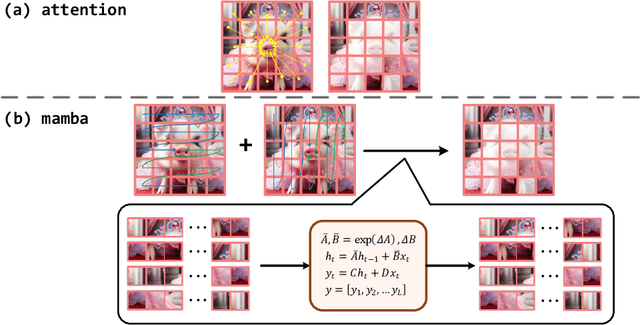
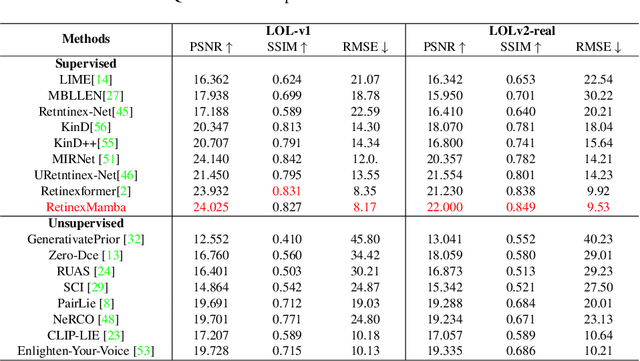
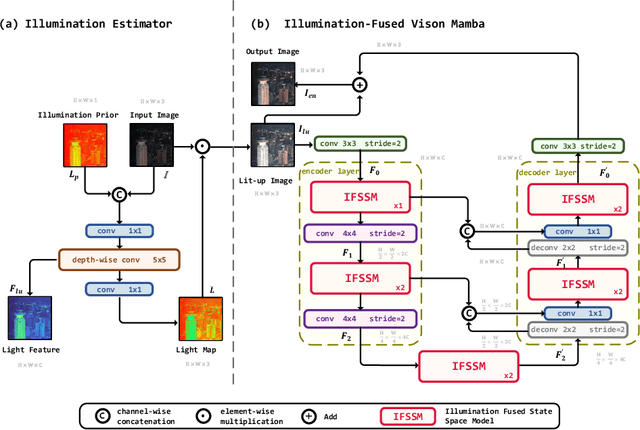
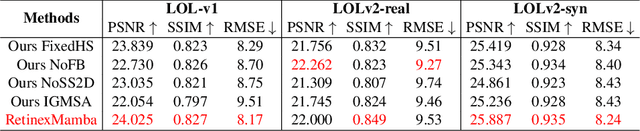
In the field of low-light image enhancement, both traditional Retinex methods and advanced deep learning techniques such as Retinexformer have shown distinct advantages and limitations. Traditional Retinex methods, designed to mimic the human eye's perception of brightness and color, decompose images into illumination and reflection components but struggle with noise management and detail preservation under low light conditions. Retinexformer enhances illumination estimation through traditional self-attention mechanisms, but faces challenges with insufficient interpretability and suboptimal enhancement effects. To overcome these limitations, this paper introduces the RetinexMamba architecture. RetinexMamba not only captures the physical intuitiveness of traditional Retinex methods but also integrates the deep learning framework of Retinexformer, leveraging the computational efficiency of State Space Models (SSMs) to enhance processing speed. This architecture features innovative illumination estimators and damage restorer mechanisms that maintain image quality during enhancement. Moreover, RetinexMamba replaces the IG-MSA (Illumination-Guided Multi-Head Attention) in Retinexformer with a Fused-Attention mechanism, improving the model's interpretability. Experimental evaluations on the LOL dataset show that RetinexMamba outperforms existing deep learning approaches based on Retinex theory in both quantitative and qualitative metrics, confirming its effectiveness and superiority in enhancing low-light images.