 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenSqueeze: Performance-Preserving Compression for Reasoning LLMs
Nov 17, 2025Emerging reasoning LLMs such as OpenAI-o1 and DeepSeek-R1 have achieved strong performance on complex reasoning tasks by generating long chain-of-thought (CoT) traces. However, these long CoTs result in increased token usage, leading to higher inference latency and memory consumption. As a result, balancing accuracy and reasoning efficiency has become essential for deploying reasoning LLMs in practical applications. Existing long-to-short (Long2Short) methods aim to reduce inference length but often sacrifice accuracy, revealing a need for an approach that maintains performance while lowering token costs. To address this efficiency-accuracy tradeoff, we propose TokenSqueeze, a novel Long2Short method that condenses reasoning paths while preserving performance and relying exclusively on self-generated data. First, to prevent performance degradation caused by excessive compression of reasoning depth, we propose to select self-generated samples whose reasoning depth is adaptively matched to the complexity of the problem. To further optimize the linguistic expression without altering the underlying reasoning paths, we introduce a distribution-aligned linguistic refinement method that enhances the clarity and conciseness of the reasoning path while preserving its logical integrity. Comprehensive experimental results demonstrate the effectiveness of TokenSqueeze in reducing token usage while maintaining accuracy. Notably, DeepSeek-R1-Distill-Qwen-7B fine-tuned using our proposed method achieved a 50\% average token reduction while preserving accuracy on the MATH500 benchmark. TokenSqueeze exclusively utilizes the model's self-generated data, enabling efficient and high-fidelity reasoning without relying on manually curated short-answer datasets across diverse applications. Our code is available at https://github.com/zhangyx1122/TokenSqueeze.
Lidar Point Cloud Guided Monocular 3D Object Detection
Apr 19, 2021
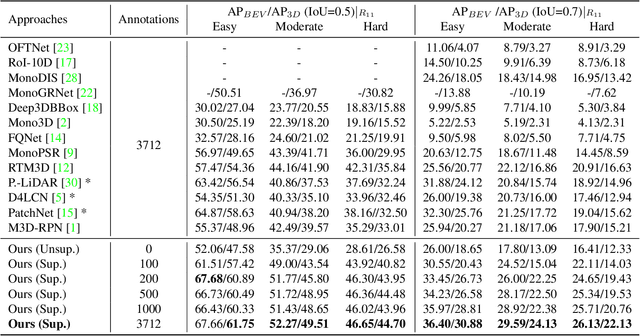
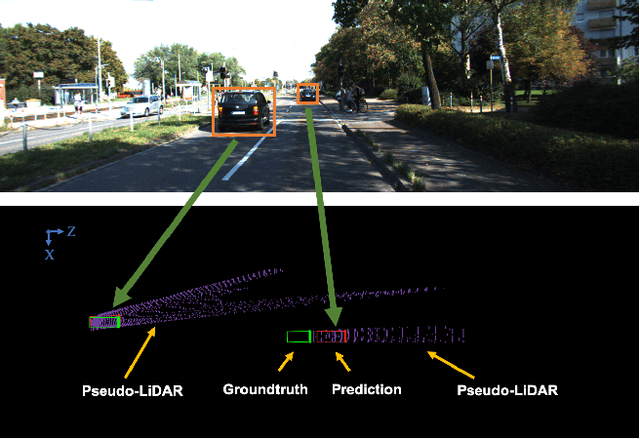
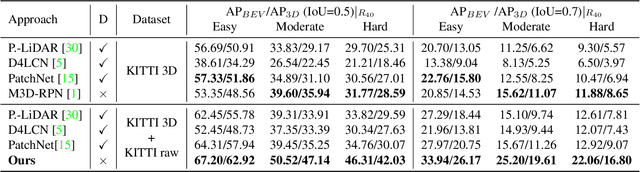
Monocular 3D object detection is drawing increasing attention from the community as it enables cars to perceive the world in 3D with a single camera. However, monocular 3D detection currently struggles with extremely lower detection rates compared to LiDAR-based methods, limiting its applications. The poor accuracy is mainly caused by the absence of accurate depth cues due to the ill-posed nature of monocular imagery. LiDAR point clouds, which provide accurate depth measurement, can offer beneficial information for the training of monocular methods. Prior works only use LiDAR point clouds to train a depth estimator. This implicit way does not fully utilize LiDAR point clouds, consequently leading to suboptimal performances. To effectively take advantage of LiDAR point clouds, in this paper we propose a general, simple yet effective framework for monocular methods. Specifically, we use LiDAR point clouds to directly guide the training of monocular 3D detectors, allowing them to learn desired objectives meanwhile eliminating the extra annotation cost. Thanks to the general design, our method can be plugged into any monocular 3D detection method, significantly boosting the performance. In conclusion, we take the first place on KITTI monocular 3D detection benchmark and increase the BEV/3D AP from 11.88/8.65 to 22.06/16.80 on the hard setting for the prior state-of-the-art method. The code will be made publicly available soon.
Accelerate Your CNN from Three Dimensions: A Comprehensive Pruning Framework
Oct 10, 2020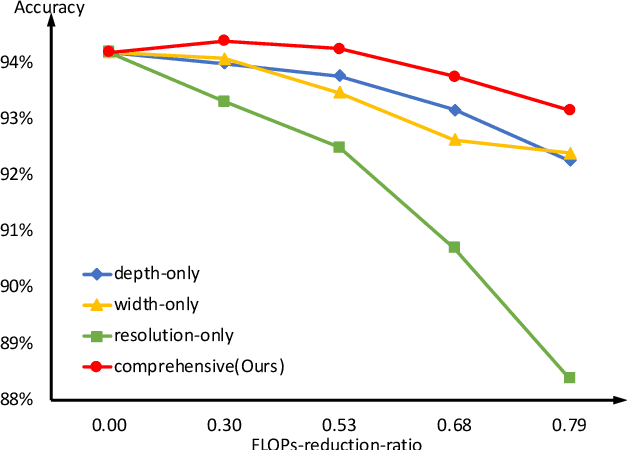
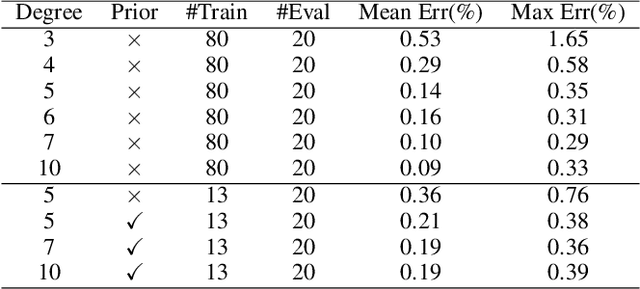

To deploy a pre-trained deep CNN on resource-constrained mobile devices, neural network pruning is often used to cut down the model's computational cost. For example, filter-level pruning (reducing the model's width) or layer-level pruning (reducing the model's depth) can both save computations with some sacrifice of accuracy. Besides, reducing the resolution of input images can also reach the same goal. Most previous methods focus on reducing one or two of these dimensions (i.e., depth, width, and image resolution) for acceleration. However, excessive reduction of any single dimension will lead to unacceptable accuracy loss, and we have to prune these three dimensions comprehensively to yield the best result. In this paper, a simple yet effective pruning framework is proposed to comprehensively consider these three dimensions. Our framework falls into two steps: 1) Determining the optimal depth (d*), width (w*), and image resolution (r) for the model. 2) Pruning the model in terms of (d*, w*, r*). Specifically, at the first step, we formulate model acceleration as an optimization problem. It takes depth (d), width (w) and image resolution (r) as variables and the model's accuracy as the optimization objective. Although it is hard to determine the expression of the objective function, approximating it with polynomials is still feasible, during which several properties of the objective function are utilized to ease and speedup the fitting process. Then the optimal d*, w* and r* are attained by maximizing the objective function with Lagrange multiplier theorem and KKT conditions. Extensive experiments are done on several popular architectures and datasets. The results show that we have outperformd the state-of-the-art pruning methods. The code will be published soon.
Apparel-invariant Feature Learning for Apparel-changed Person Re-identification
Aug 17, 2020
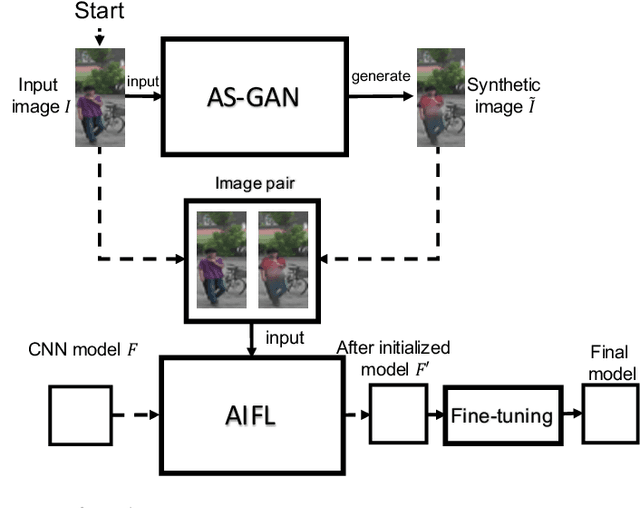
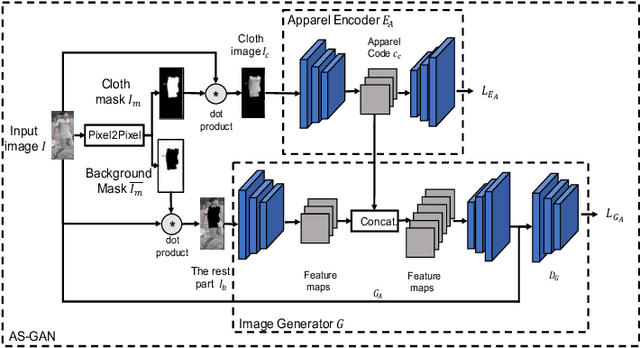

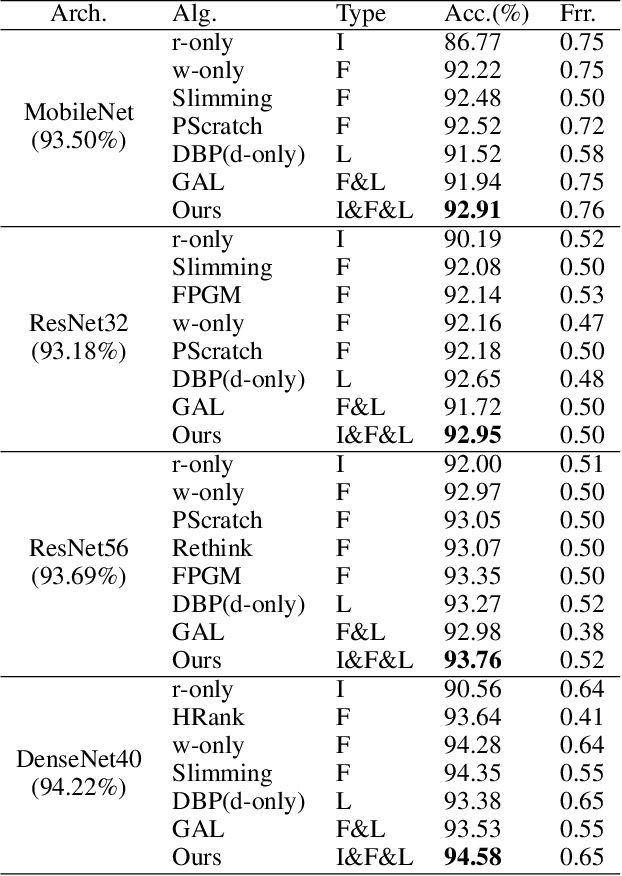
With the rise of deep learning methods, person Re-Identification (ReID) performance has been improved tremendously in many public datasets. However, most public ReID datasets are collected in a short time window in which persons' appearance rarely changes. In real-world applications such as in a shopping mall, the same person's clothing may change, and different persons may wearing similar clothes. All these cases can result in an inconsistent ReID performance, revealing a critical problem that current ReID models heavily rely on person's apparels. Therefore, it is critical to learn an apparel-invariant person representation under cases like cloth changing or several persons wearing similar clothes. In this work, we tackle this problem from the viewpoint of invariant feature representation learning. The main contributions of this work are as follows. (1) We propose the semi-supervised Apparel-invariant Feature Learning (AIFL) framework to learn an apparel-invariant pedestrian representation using images of the same person wearing different clothes. (2) To obtain images of the same person wearing different clothes, we propose an unsupervised apparel-simulation GAN (AS-GAN) to synthesize cloth changing images according to the target cloth embedding. It's worth noting that the images used in ReID tasks were cropped from real-world low-quality CCTV videos, making it more challenging to synthesize cloth changing images. We conduct extensive experiments on several datasets comparing with several baselines. Experimental results demonstrate that our proposal can improve the ReID performance of the baseline models.
Stable Learning via Causality-based Feature Rectification
Jul 30, 2020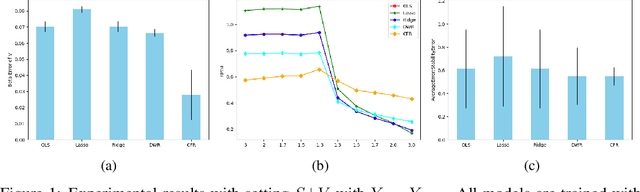
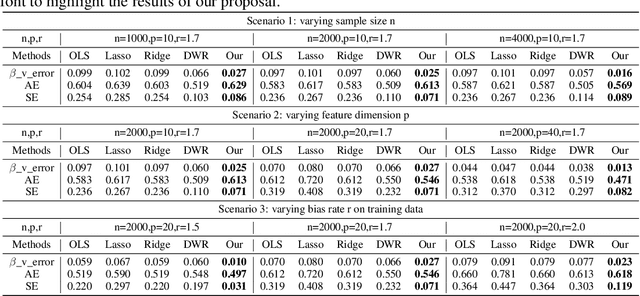
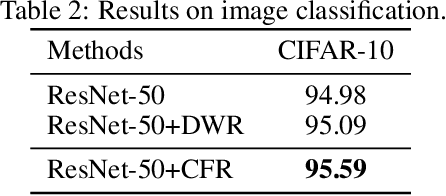
How to learn a stable model under agnostic distribution shift between training and testing datasets is an essential problem in machine learning tasks. The agnostic distribution shift caused by data generation bias can lead to model misspecification and unstable performance across different test datasets. Most of the recently proposed methods are causality-based sample reweighting methods, whose performance is affected by sample size. Moreover, these works are restricted to linear models, not to deep-learning based nonlinear models. In this work, we propose a novel Causality-based Feature Rectification (CFR) method to address the model misspecification problem under agnostic distribution shift by using a weight matrix to rectify features. Our proposal based on the fact that the causality between stable features and the ground truth is consistent under agnostic distribution shift, but is partly omitted and statistically correlated with other features. We propose the feature rectification weight matrix to reconstruct the omitted causality by using other features as proxy variables. We further propose an algorithm that jointly optimizes the weight matrix and the regressor (or classifier). Our proposal can not only improve the stability of linear models, but also deep-learning based models. Extensive experiments on both synthetic and real-world datasets demonstrate that our proposal outperforms previous state-of-the-art stable learning methods. The code will be released later on.
PI-RCNN: An Efficient Multi-sensor 3D Object Detector with Point-based Attentive Cont-conv Fusion Module
Dec 02, 2019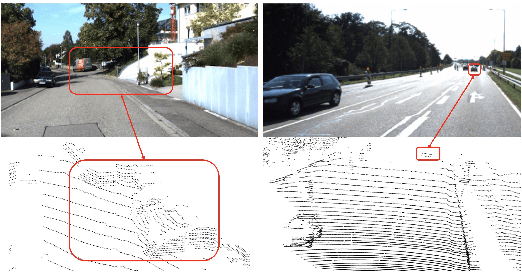
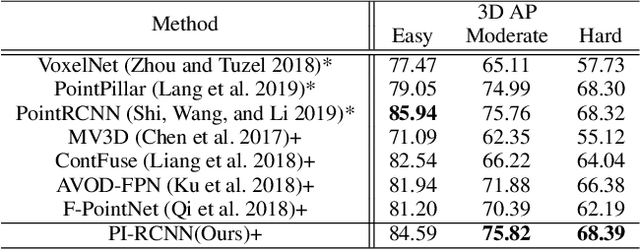
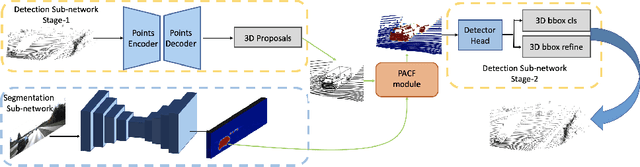
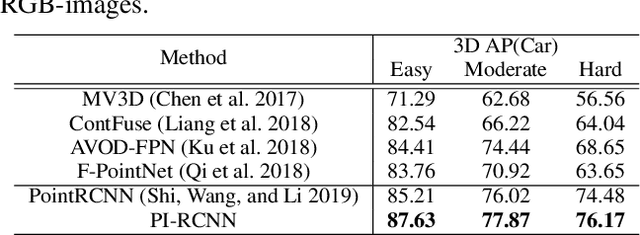
LIDAR point clouds and RGB-images are both extremely essential for 3D object detection. So many state-of-the-art 3D detection algorithms dedicate in fusing these two types of data effectively. However, their fusion methods based on Birds Eye View (BEV) or voxel format are not accurate. In this paper, we propose a novel fusion approach named Point-based Attentive Cont-conv Fusion(PACF) module, which fuses multi-sensor features directly on 3D points. Except for continuous convolution, we additionally add a Point-Pooling and an Attentive Aggregation to make the fused features more expressive. Moreover, based on the PACF module, we propose a 3D multi-sensor multi-task network called Pointcloud-Image RCNN(PI-RCNN as brief), which handles the image segmentation and 3D object detection tasks. PI-RCNN employs a segmentation sub-network to extract full-resolution semantic feature maps from images and then fuses the multi-sensor features via powerful PACF module. Beneficial from the effectiveness of the PACF module and the expressive semantic features from the segmentation module, PI-RCNN can improve much in 3D object detection. We demonstrate the effectiveness of the PACF module and PI-RCNN on the KITTI 3D Detection benchmark, and our method can achieve state-of-the-art on the metric of 3D AP.
Progressive Transfer Learning for Person Re-identification
Aug 08, 2019
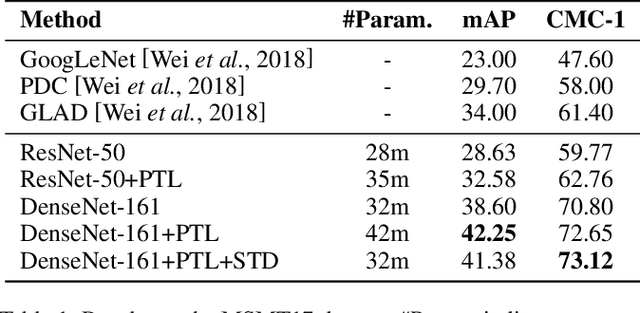
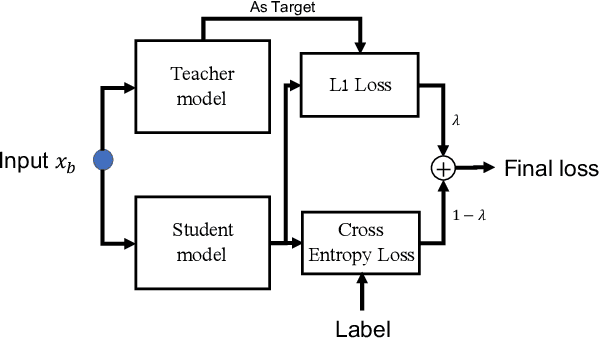
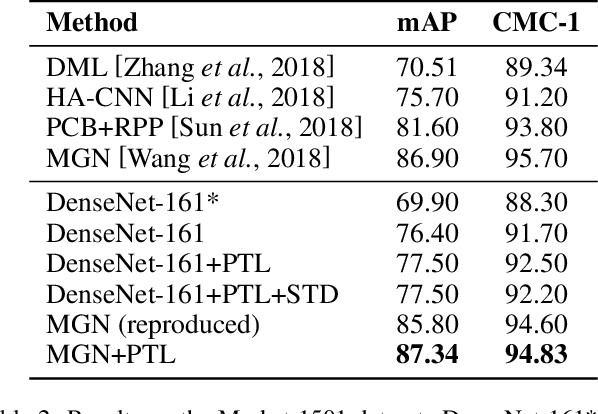
Model fine-tuning is a widely used transfer learning approach in person Re-identification (ReID) applications, which fine-tuning a pre-trained feature extraction model into the target scenario instead of training a model from scratch. It is challenging due to the significant variations inside the target scenario, e.g., different camera viewpoint, illumination changes, and occlusion. These variations result in a gap between the distribution of each mini-batch and the distribution of the whole dataset when using mini-batch training. In this paper, we study model fine-tuning from the perspective of the aggregation and utilization of the global information of the dataset when using mini-batch training. Specifically, we introduce a novel network structure called Batch-related Convolutional Cell (BConv-Cell), which progressively collects the global information of the dataset into a latent state and uses this latent state to rectify the extracted feature. Based on BConv-Cells, we further proposed the Progressive Transfer Learning (PTL) method to facilitate the model fine-tuning process by joint training the BConv-Cells and the pre-trained ReID model. Empirical experiments show that our proposal can improve the performance of the ReID model greatly on MSMT17, Market-1501, CUHK03 and DukeMTMC-reID datasets. The code will be released later on at \url{https://github.com/ZJULearning/PTL}