 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLidar Point Cloud Guided Monocular 3D Object Detection
Paper and Code

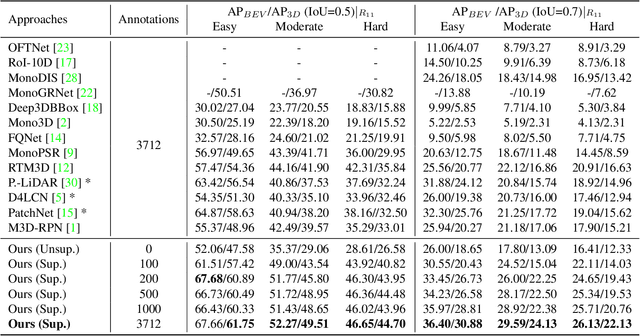
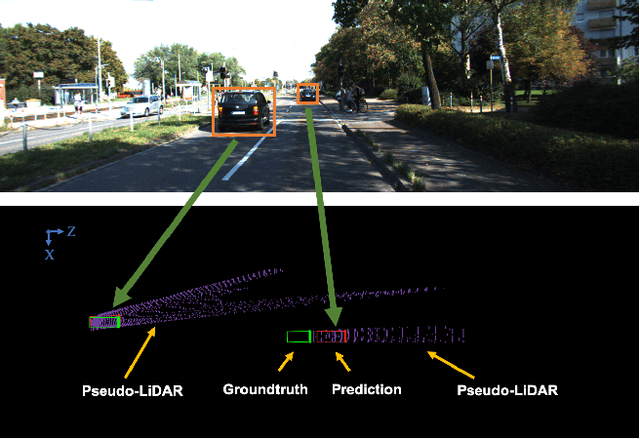
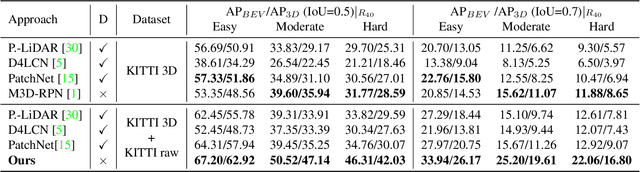
Monocular 3D object detection is drawing increasing attention from the community as it enables cars to perceive the world in 3D with a single camera. However, monocular 3D detection currently struggles with extremely lower detection rates compared to LiDAR-based methods, limiting its applications. The poor accuracy is mainly caused by the absence of accurate depth cues due to the ill-posed nature of monocular imagery. LiDAR point clouds, which provide accurate depth measurement, can offer beneficial information for the training of monocular methods. Prior works only use LiDAR point clouds to train a depth estimator. This implicit way does not fully utilize LiDAR point clouds, consequently leading to suboptimal performances. To effectively take advantage of LiDAR point clouds, in this paper we propose a general, simple yet effective framework for monocular methods. Specifically, we use LiDAR point clouds to directly guide the training of monocular 3D detectors, allowing them to learn desired objectives meanwhile eliminating the extra annotation cost. Thanks to the general design, our method can be plugged into any monocular 3D detection method, significantly boosting the performance. In conclusion, we take the first place on KITTI monocular 3D detection benchmark and increase the BEV/3D AP from 11.88/8.65 to 22.06/16.80 on the hard setting for the prior state-of-the-art method. The code will be made publicly available soon.