 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegulating Intermediate 3D Features for Vision-Centric Autonomous Driving
Dec 19, 2023



Multi-camera perception tasks have gained significant attention in the field of autonomous driving. However, existing frameworks based on Lift-Splat-Shoot (LSS) in the multi-camera setting cannot produce suitable dense 3D features due to the projection nature and uncontrollable densification process. To resolve this problem, we propose to regulate intermediate dense 3D features with the help of volume rendering. Specifically, we employ volume rendering to process the dense 3D features to obtain corresponding 2D features (e.g., depth maps, semantic maps), which are supervised by associated labels in the training. This manner regulates the generation of dense 3D features on the feature level, providing appropriate dense and unified features for multiple perception tasks. Therefore, our approach is termed Vampire, stands for "Volume rendering As Multi-camera Perception Intermediate feature REgulator". Experimental results on the Occ3D and nuScenes datasets demonstrate that Vampire facilitates fine-grained and appropriate extraction of dense 3D features, and is competitive with existing SOTA methods across diverse downstream perception tasks like 3D occupancy prediction, LiDAR segmentation and 3D objection detection, while utilizing moderate GPU resources. We provide a video demonstration in the supplementary materials and Codes are available at github.com/cskkxjk/Vampire.
Lidar Point Cloud Guided Monocular 3D Object Detection
Apr 19, 2021
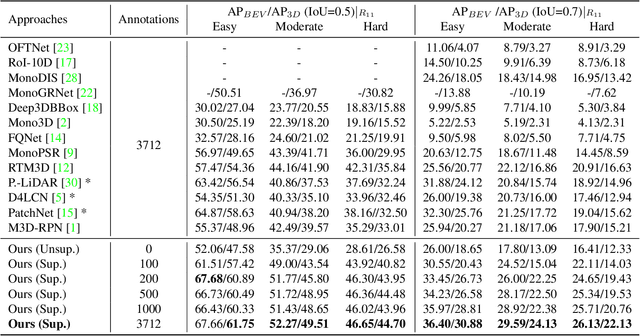
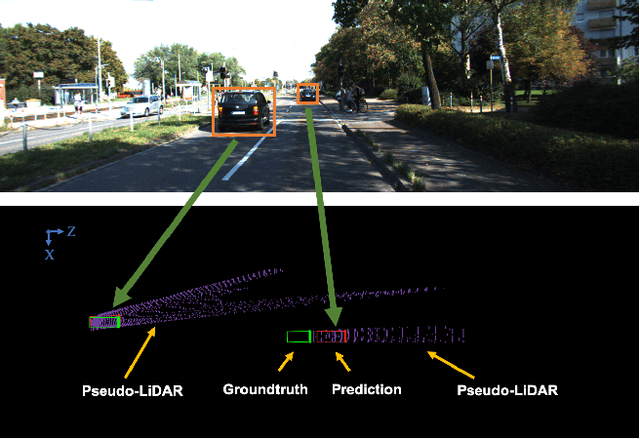
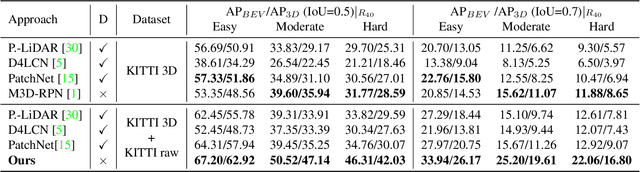
Monocular 3D object detection is drawing increasing attention from the community as it enables cars to perceive the world in 3D with a single camera. However, monocular 3D detection currently struggles with extremely lower detection rates compared to LiDAR-based methods, limiting its applications. The poor accuracy is mainly caused by the absence of accurate depth cues due to the ill-posed nature of monocular imagery. LiDAR point clouds, which provide accurate depth measurement, can offer beneficial information for the training of monocular methods. Prior works only use LiDAR point clouds to train a depth estimator. This implicit way does not fully utilize LiDAR point clouds, consequently leading to suboptimal performances. To effectively take advantage of LiDAR point clouds, in this paper we propose a general, simple yet effective framework for monocular methods. Specifically, we use LiDAR point clouds to directly guide the training of monocular 3D detectors, allowing them to learn desired objectives meanwhile eliminating the extra annotation cost. Thanks to the general design, our method can be plugged into any monocular 3D detection method, significantly boosting the performance. In conclusion, we take the first place on KITTI monocular 3D detection benchmark and increase the BEV/3D AP from 11.88/8.65 to 22.06/16.80 on the hard setting for the prior state-of-the-art method. The code will be made publicly available soon.
Geometry-based Occlusion-Aware Unsupervised Stereo Matching for Autonomous Driving
Oct 21, 2020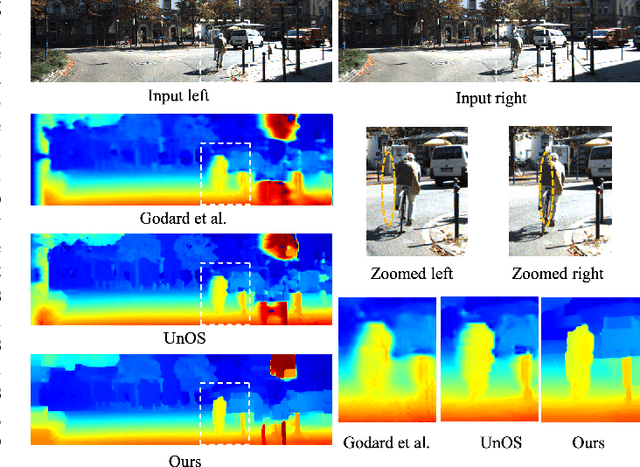
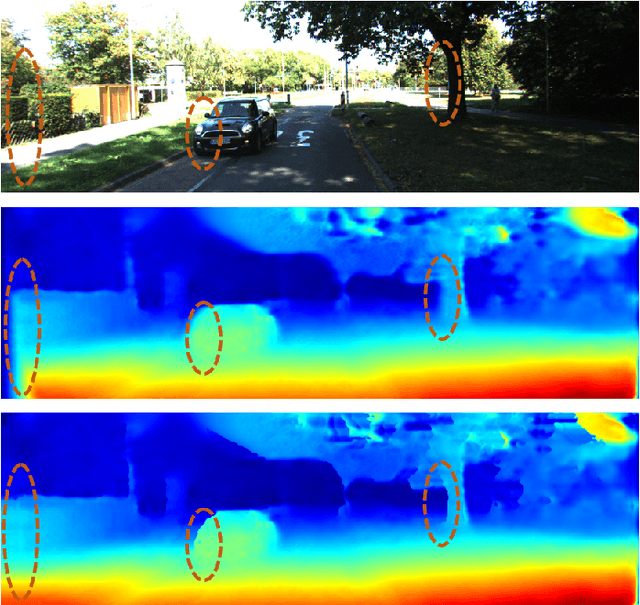
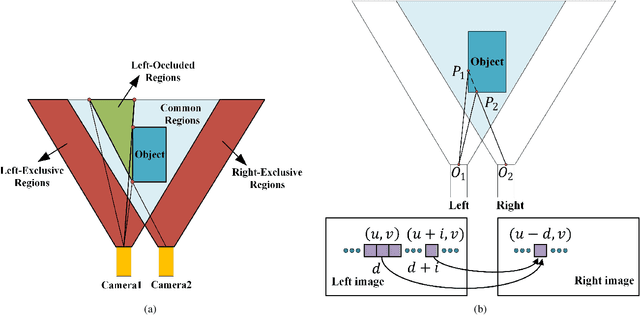

Recently, there are emerging many stereo matching methods for autonomous driving based on unsupervised learning. Most of them take advantage of reconstruction losses to remove dependency on disparity groundtruth. Occlusion handling is a challenging problem in stereo matching, especially for unsupervised methods. Previous unsupervised methods failed to take full advantage of geometry properties in occlusion handling. In this paper, we introduce an effective way to detect occlusion regions and propose a novel unsupervised training strategy to deal with occlusion that only uses the predicted left disparity map, by making use of its geometry features in an iterative way. In the training process, we regard the predicted left disparity map as pseudo groundtruth and infer occluded regions using geometry features. The resulting occlusion mask is then used in either training, post-processing, or both of them as guidance. Experiments show that our method could deal with the occlusion problem effectively and significantly outperforms the other unsupervised methods for stereo matching. Moreover, our occlusion-aware strategies can be extended to the other stereo methods conveniently and improve their performances.
PixelLink: Detecting Scene Text via Instance Segmentation
Jan 04, 2018
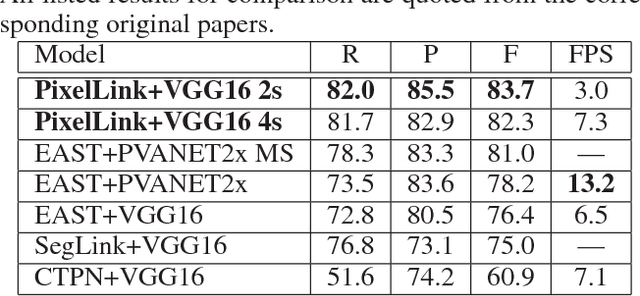
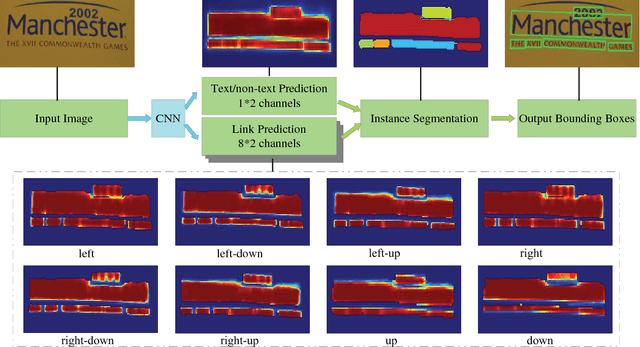
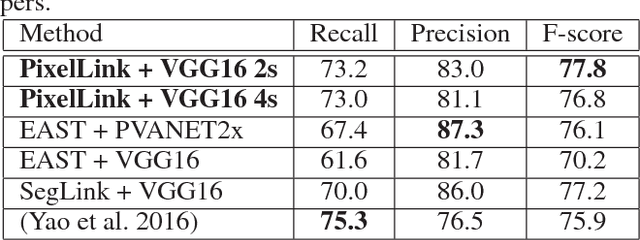
Most state-of-the-art scene text detection algorithms are deep learning based methods that depend on bounding box regression and perform at least two kinds of predictions: text/non-text classification and location regression. Regression plays a key role in the acquisition of bounding boxes in these methods, but it is not indispensable because text/non-text prediction can also be considered as a kind of semantic segmentation that contains full location information in itself. However, text instances in scene images often lie very close to each other, making them very difficult to separate via semantic segmentation. Therefore, instance segmentation is needed to address this problem. In this paper, PixelLink, a novel scene text detection algorithm based on instance segmentation, is proposed. Text instances are first segmented out by linking pixels within the same instance together. Text bounding boxes are then extracted directly from the segmentation result without location regression. Experiments show that, compared with regression-based methods, PixelLink can achieve better or comparable performance on several benchmarks, while requiring many fewer training iterations and less training data.