 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruning Long Chain-of-Thought of Large Reasoning Models via Small-Scale Preference Optimization
Aug 13, 2025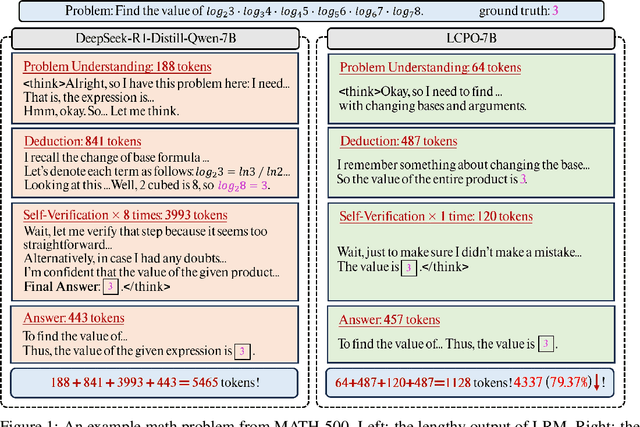
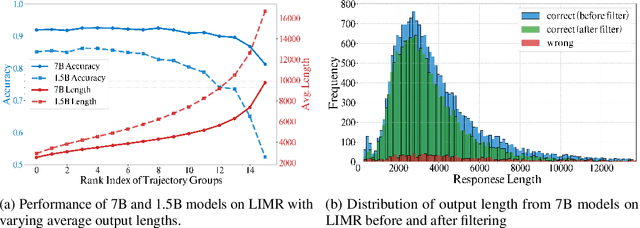
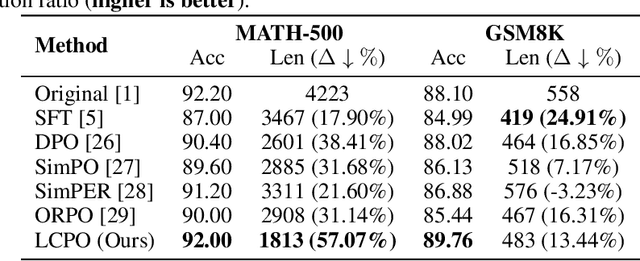
Recent advances in Large Reasoning Models (LRMs) have demonstrated strong performance on complex tasks through long Chain-of-Thought (CoT) reasoning. However, their lengthy outputs increase computational costs and may lead to overthinking, raising challenges in balancing reasoning effectiveness and efficiency. Current methods for efficient reasoning often compromise reasoning quality or require extensive resources. This paper investigates efficient methods to reduce the generation length of LRMs. We analyze generation path distributions and filter generated trajectories through difficulty estimation. Subsequently, we analyze the convergence behaviors of the objectives of various preference optimization methods under a Bradley-Terry loss based framework. Based on the analysis, we propose Length Controlled Preference Optimization (LCPO) that directly balances the implicit reward related to NLL loss. LCPO can effectively learn length preference with limited data and training. Extensive experiments demonstrate that our approach significantly reduces the average output length by over 50\% across multiple benchmarks while maintaining the reasoning performance. Our work highlights the potential for computationally efficient approaches in guiding LRMs toward efficient reasoning.
Apparel-invariant Feature Learning for Apparel-changed Person Re-identification
Aug 17, 2020
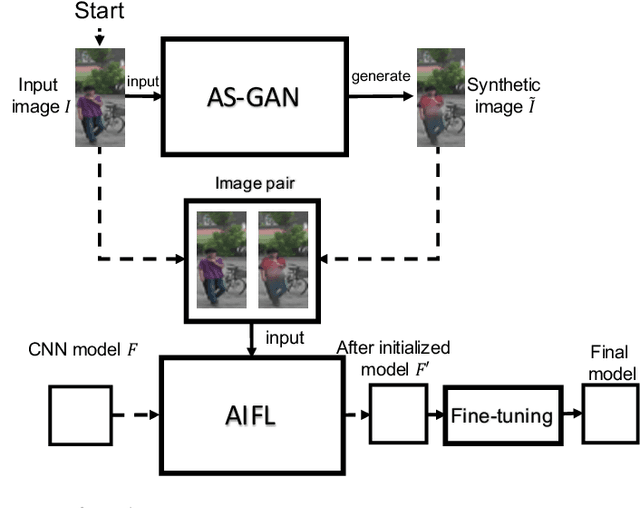
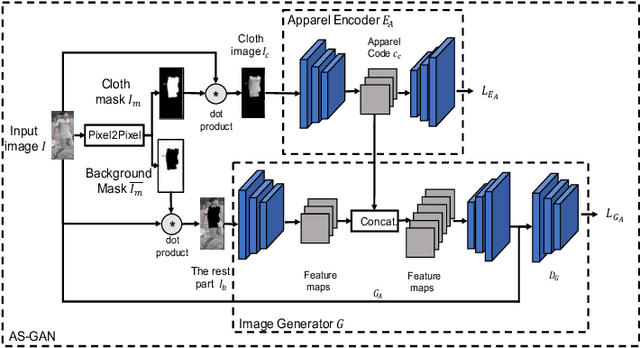

With the rise of deep learning methods, person Re-Identification (ReID) performance has been improved tremendously in many public datasets. However, most public ReID datasets are collected in a short time window in which persons' appearance rarely changes. In real-world applications such as in a shopping mall, the same person's clothing may change, and different persons may wearing similar clothes. All these cases can result in an inconsistent ReID performance, revealing a critical problem that current ReID models heavily rely on person's apparels. Therefore, it is critical to learn an apparel-invariant person representation under cases like cloth changing or several persons wearing similar clothes. In this work, we tackle this problem from the viewpoint of invariant feature representation learning. The main contributions of this work are as follows. (1) We propose the semi-supervised Apparel-invariant Feature Learning (AIFL) framework to learn an apparel-invariant pedestrian representation using images of the same person wearing different clothes. (2) To obtain images of the same person wearing different clothes, we propose an unsupervised apparel-simulation GAN (AS-GAN) to synthesize cloth changing images according to the target cloth embedding. It's worth noting that the images used in ReID tasks were cropped from real-world low-quality CCTV videos, making it more challenging to synthesize cloth changing images. We conduct extensive experiments on several datasets comparing with several baselines. Experimental results demonstrate that our proposal can improve the ReID performance of the baseline models.
Safe Element Screening for Submodular Function Minimization
Jun 07, 2018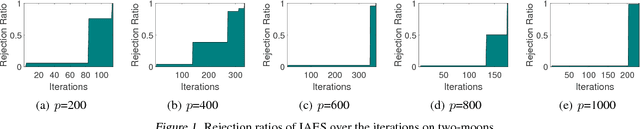
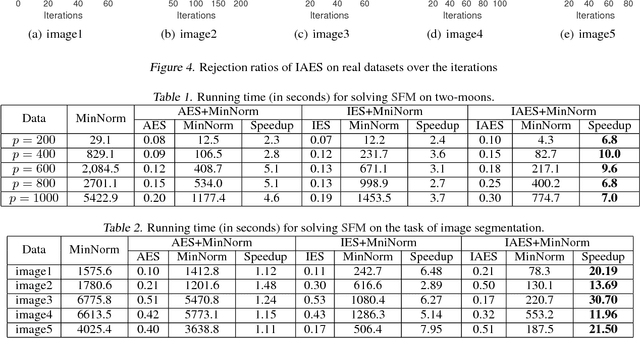

Submodular functions are discrete analogs of convex functions, which have applications in various fields, including machine learning and computer vision. However, in large-scale applications, solving Submodular Function Minimization (SFM) problems remains challenging. In this paper, we make the first attempt to extend the emerging technique named screening in large-scale sparse learning to SFM for accelerating its optimization process. We first conduct a careful studying of the relationships between SFM and the corresponding convex proximal problems, as well as the accurate primal optimum estimation of the proximal problems. Relying on this study, we subsequently propose a novel safe screening method to quickly identify the elements guaranteed to be included (we refer to them as active) or excluded (inactive) in the final optimal solution of SFM during the optimization process. By removing the inactive elements and fixing the active ones, the problem size can be dramatically reduced, leading to great savings in the computational cost without sacrificing any accuracy. To the best of our knowledge, the proposed method is the first screening method in the fields of SFM and even combinatorial optimization, thus pointing out a new direction for accelerating SFM algorithms. Experiment results on both synthetic and real datasets demonstrate the significant speedups gained by our approach.
The Second Order Linear Model
Jun 23, 2017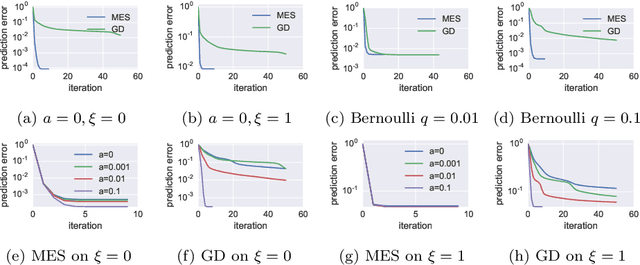
We study a fundamental class of regression models called the second order linear model (SLM). The SLM extends the linear model to high order functional space and has attracted considerable research interest recently. Yet how to efficiently learn the SLM under full generality using nonconvex solver still remains an open question due to several fundamental limitations of the conventional gradient descent learning framework. In this study, we try to attack this problem from a gradient-free approach which we call the moment-estimation-sequence (MES) method. We show that the conventional gradient descent heuristic is biased by the skewness of the distribution therefore is no longer the best practice of learning the SLM. Based on the MES framework, we design a nonconvex alternating iteration process to train a $d$-dimension rank-$k$ SLM within $O(kd)$ memory and one-pass of the dataset. The proposed method converges globally and linearly, achieves $\epsilon$ recovery error after retrieving $O[k^{2}d\cdot\mathrm{polylog}(kd/\epsilon)]$ samples. Furthermore, our theoretical analysis reveals that not all SLMs can be learned on every sub-gaussian distribution. When the instances are sampled from a so-called $\tau$-MIP distribution, the SLM can be learned by $O(p/\tau^{2})$ samples where $p$ and $\tau$ are positive constants depending on the skewness and kurtosis of the distribution. For non-MIP distribution, an addition diagonal-free oracle is necessary and sufficient to guarantee the learnability of the SLM. Numerical simulations verify the sharpness of our bounds on the sampling complexity and the linear convergence rate of our algorithm.
Scaling Up Sparse Support Vector Machines by Simultaneous Feature and Sample Reduction
Jun 23, 2017
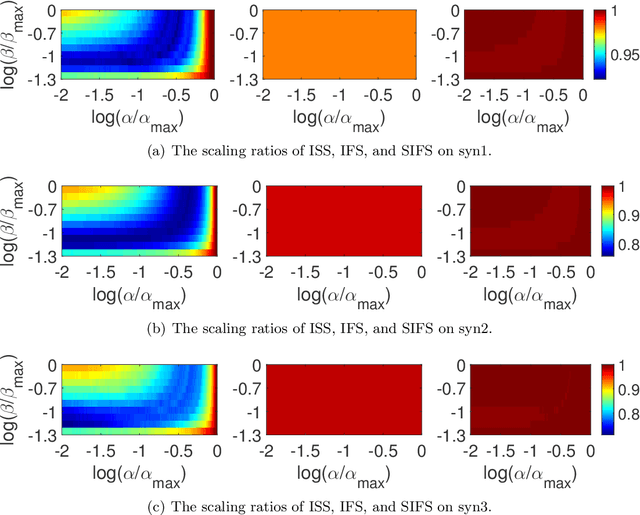
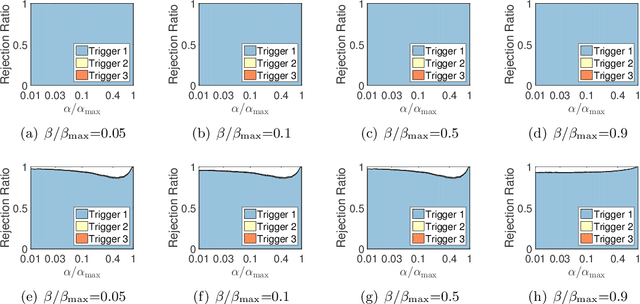
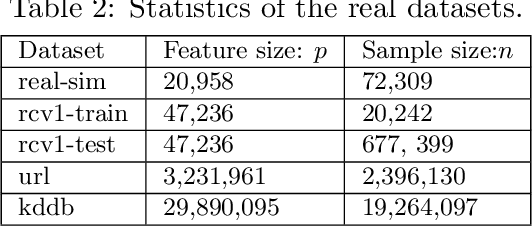
Sparse support vector machine (SVM) is a popular classification technique that can simultaneously learn a small set of the most interpretable features and identify the support vectors. It has achieved great successes in many real-world applications. However, for large-scale problems involving a huge number of samples and extremely high-dimensional features, solving sparse SVMs remains challenging. By noting that sparse SVMs induce sparsities in both feature and sample spaces, we propose a novel approach, which is based on accurate estimations of the primal and dual optima of sparse SVMs, to simultaneously identify the features and samples that are guaranteed to be irrelevant to the outputs. Thus, we can remove the identified inactive samples and features from the training phase, leading to substantial savings in both the memory usage and computational cost without sacrificing accuracy. To the best of our knowledge, the proposed method is the \emph{first} \emph{static} feature and sample reduction method for sparse SVM. Experiments on both synthetic and real datasets (e.g., the kddb dataset with about 20 million samples and 30 million features) demonstrate that our approach significantly outperforms state-of-the-art methods and the speedup gained by our approach can be orders of magnitude.