 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable Learning via Causality-based Feature Rectification
Paper and Code
Jul 30, 2020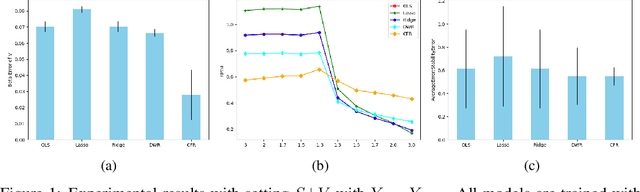
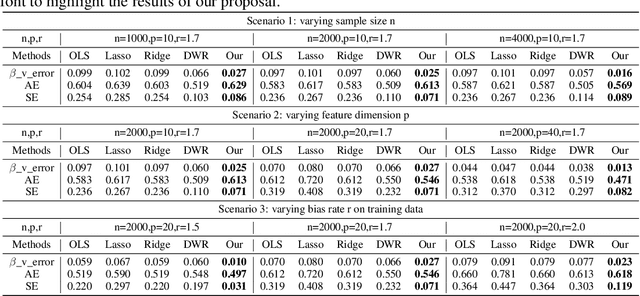
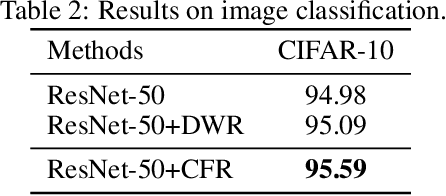
How to learn a stable model under agnostic distribution shift between training and testing datasets is an essential problem in machine learning tasks. The agnostic distribution shift caused by data generation bias can lead to model misspecification and unstable performance across different test datasets. Most of the recently proposed methods are causality-based sample reweighting methods, whose performance is affected by sample size. Moreover, these works are restricted to linear models, not to deep-learning based nonlinear models. In this work, we propose a novel Causality-based Feature Rectification (CFR) method to address the model misspecification problem under agnostic distribution shift by using a weight matrix to rectify features. Our proposal based on the fact that the causality between stable features and the ground truth is consistent under agnostic distribution shift, but is partly omitted and statistically correlated with other features. We propose the feature rectification weight matrix to reconstruct the omitted causality by using other features as proxy variables. We further propose an algorithm that jointly optimizes the weight matrix and the regressor (or classifier). Our proposal can not only improve the stability of linear models, but also deep-learning based models. Extensive experiments on both synthetic and real-world datasets demonstrate that our proposal outperforms previous state-of-the-art stable learning methods. The code will be released later on.