 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Gap in Distilling StyleGANs
Aug 18, 2022
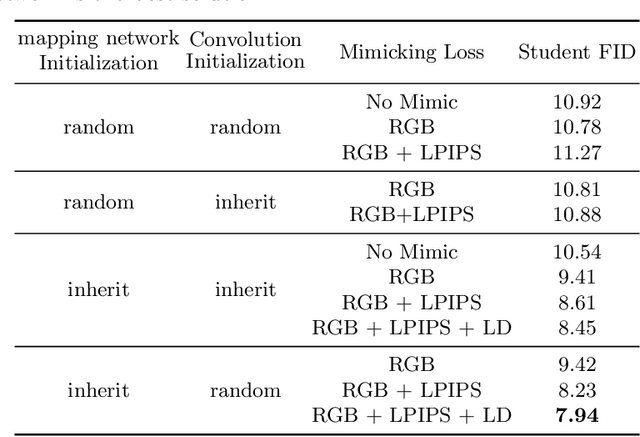
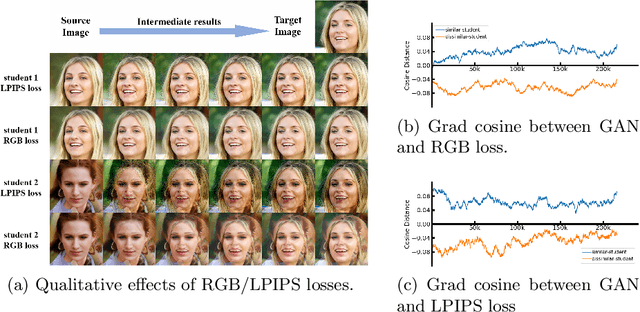
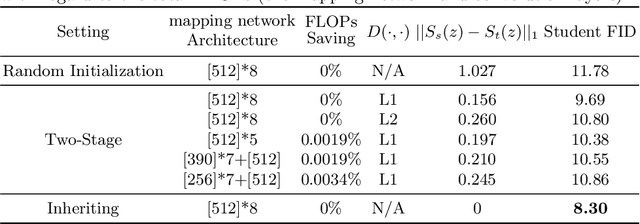
StyleGAN family is one of the most popular Generative Adversarial Networks (GANs) for unconditional generation. Despite its impressive performance, its high demand on storage and computation impedes their deployment on resource-constrained devices. This paper provides a comprehensive study of distilling from the popular StyleGAN-like architecture. Our key insight is that the main challenge of StyleGAN distillation lies in the output discrepancy issue, where the teacher and student model yield different outputs given the same input latent code. Standard knowledge distillation losses typically fail under this heterogeneous distillation scenario. We conduct thorough analysis about the reasons and effects of this discrepancy issue, and identify that the mapping network plays a vital role in determining semantic information of generated images. Based on this finding, we propose a novel initialization strategy for the student model, which can ensure the output consistency to the maximum extent. To further enhance the semantic consistency between the teacher and student model, we present a latent-direction-based distillation loss that preserves the semantic relations in latent space. Extensive experiments demonstrate the effectiveness of our approach in distilling StyleGAN2 and StyleGAN3, outperforming existing GAN distillation methods by a large margin.
Towards Evaluating and Training Verifiably Robust Neural Networks
Apr 05, 2021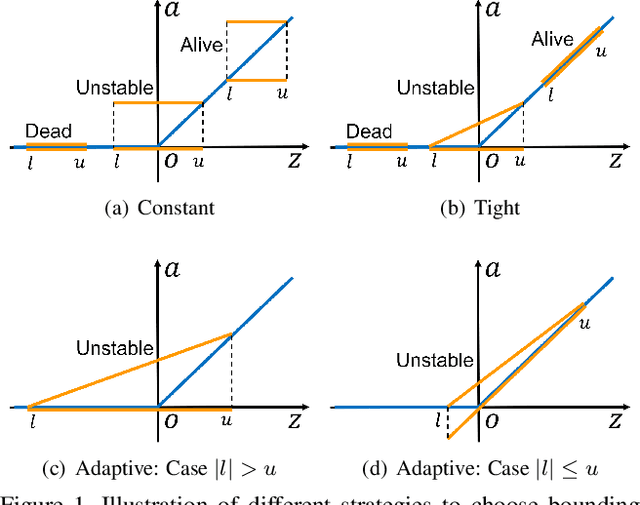
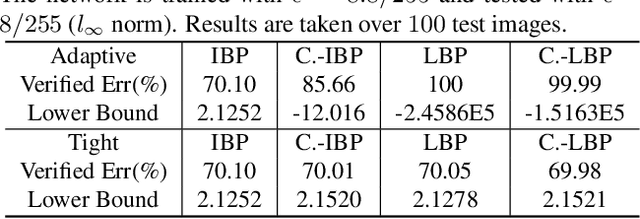
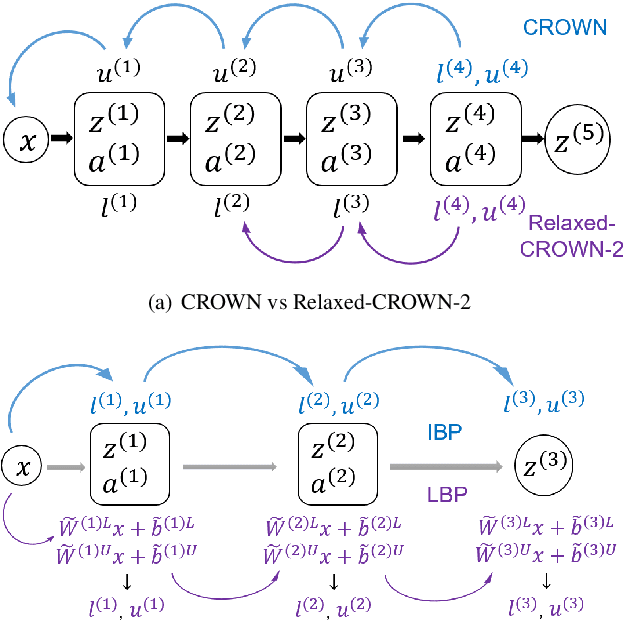
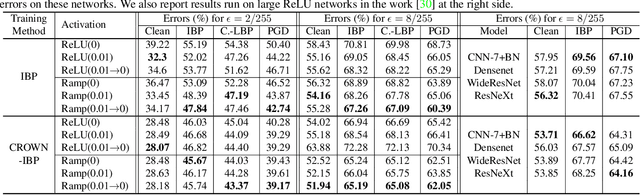
Recent works have shown that interval bound propagation (IBP) can be used to train verifiably robust neural networks. Reseachers observe an intriguing phenomenon on these IBP trained networks: CROWN, a bounding method based on tight linear relaxation, often gives very loose bounds on these networks. We also observe that most neurons become dead during the IBP training process, which could hurt the representation capability of the network. In this paper, we study the relationship between IBP and CROWN, and prove that CROWN is always tighter than IBP when choosing appropriate bounding lines. We further propose a relaxed version of CROWN, linear bound propagation (LBP), that can be used to verify large networks to obtain lower verified errors than IBP. We also design a new activation function, parameterized ramp function (ParamRamp), which has more diversity of neuron status than ReLU. We conduct extensive experiments on MNIST, CIFAR-10 and Tiny-ImageNet with ParamRamp activation and achieve state-of-the-art verified robustness. Code and the appendix are available at https://github.com/ZhaoyangLyu/VerifiablyRobustNN.
X-view: Non-egocentric Multi-View 3D Object Detector
Mar 24, 2021
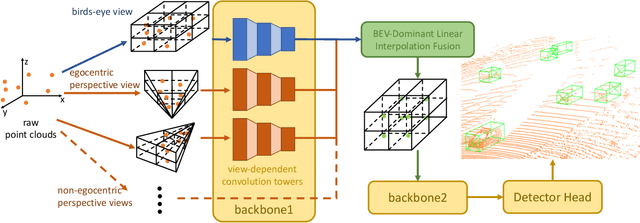

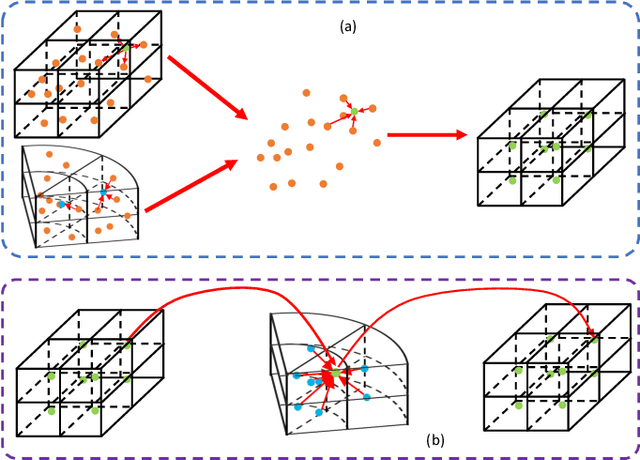
3D object detection algorithms for autonomous driving reason about 3D obstacles either from 3D birds-eye view or perspective view or both. Recent works attempt to improve the detection performance via mining and fusing from multiple egocentric views. Although the egocentric perspective view alleviates some weaknesses of the birds-eye view, the sectored grid partition becomes so coarse in the distance that the targets and surrounding context mix together, which makes the features less discriminative. In this paper, we generalize the research on 3D multi-view learning and propose a novel multi-view-based 3D detection method, named X-view, to overcome the drawbacks of the multi-view methods. Specifically, X-view breaks through the traditional limitation about the perspective view whose original point must be consistent with the 3D Cartesian coordinate. X-view is designed as a general paradigm that can be applied on almost any 3D detectors based on LiDAR with only little increment of running time, no matter it is voxel/grid-based or raw-point-based. We conduct experiments on KITTI and NuScenes datasets to demonstrate the robustness and effectiveness of our proposed X-view. The results show that X-view obtains consistent improvements when combined with four mainstream state-of-the-art 3D methods: SECOND, PointRCNN, Part-A^2, and PV-RCNN.
SparsePoint: Fully End-to-End Sparse 3D Object Detector
Mar 18, 2021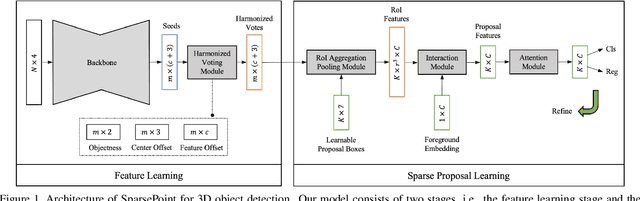
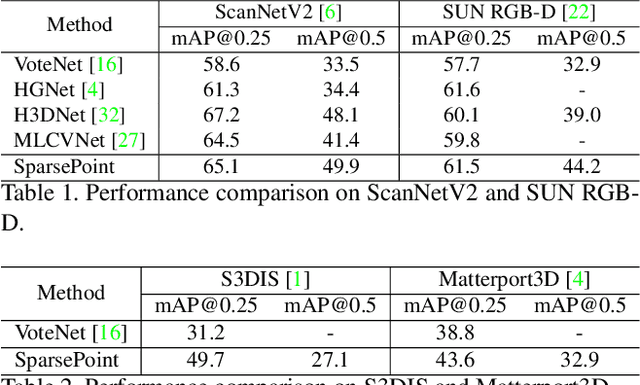
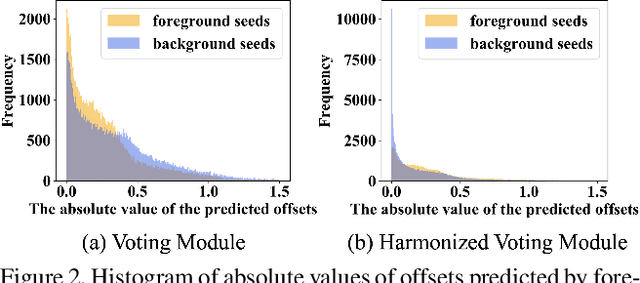
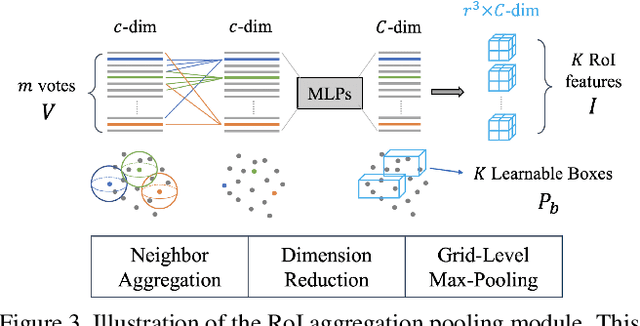
Object detectors based on sparse object proposals have recently been proven to be successful in the 2D domain, which makes it possible to establish a fully end-to-end detector without time-consuming post-processing. This development is also attractive for 3D object detectors. However, considering the remarkably larger search space in the 3D domain, whether it is feasible to adopt the sparse method in the 3D object detection setting is still an open question. In this paper, we propose SparsePoint, the first sparse method for 3D object detection. Our SparsePoint adopts a number of learnable proposals to encode most likely potential positions of 3D objects and a foreground embedding to encode shared semantic features of all objects. Besides, with the attention module to provide object-level interaction for redundant proposal removal and Hungarian algorithm to supply one-one label assignment, our method can produce sparse and accurate predictions. SparsePoint sets a new state-of-the-art on four public datasets, including ScanNetV2, SUN RGB-D, S3DIS, and Matterport3D. Our code will be publicly available soon.
Computation-Efficient Knowledge Distillation via Uncertainty-Aware Mixup
Dec 17, 2020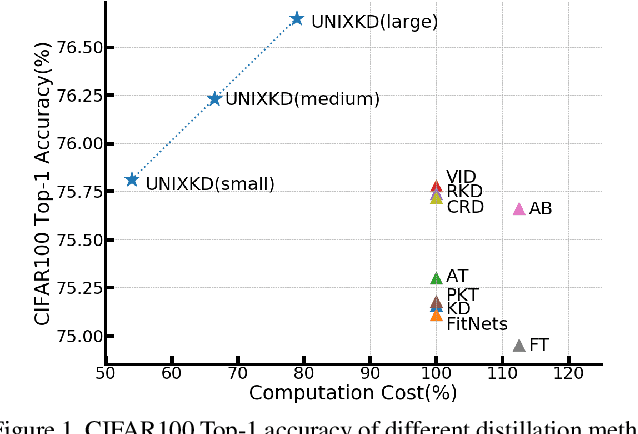
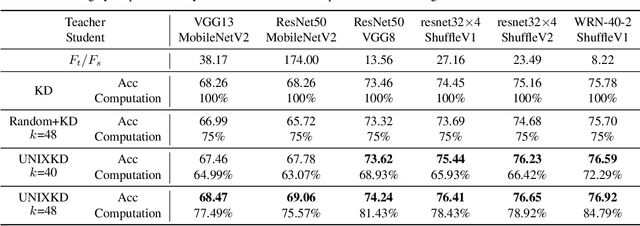
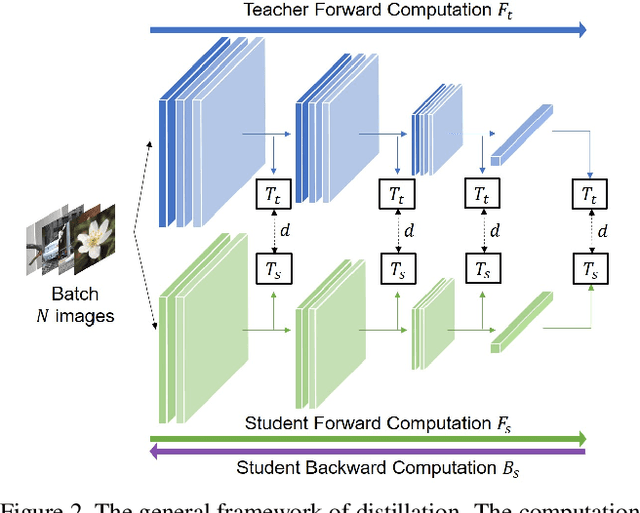

Knowledge distillation, which involves extracting the "dark knowledge" from a teacher network to guide the learning of a student network, has emerged as an essential technique for model compression and transfer learning. Unlike previous works that focus on the accuracy of student network, here we study a little-explored but important question, i.e., knowledge distillation efficiency. Our goal is to achieve a performance comparable to conventional knowledge distillation with a lower computation cost during training. We show that the UNcertainty-aware mIXup (UNIX) can serve as a clean yet effective solution. The uncertainty sampling strategy is used to evaluate the informativeness of each training sample. Adaptive mixup is applied to uncertain samples to compact knowledge. We further show that the redundancy of conventional knowledge distillation lies in the excessive learning of easy samples. By combining uncertainty and mixup, our approach reduces the redundancy and makes better use of each query to the teacher network. We validate our approach on CIFAR100 and ImageNet. Notably, with only 79% computation cost, we outperform conventional knowledge distillation on CIFAR100 and achieve a comparable result on ImageNet.
Knowledge Distillation Meets Self-Supervision
Jul 13, 2020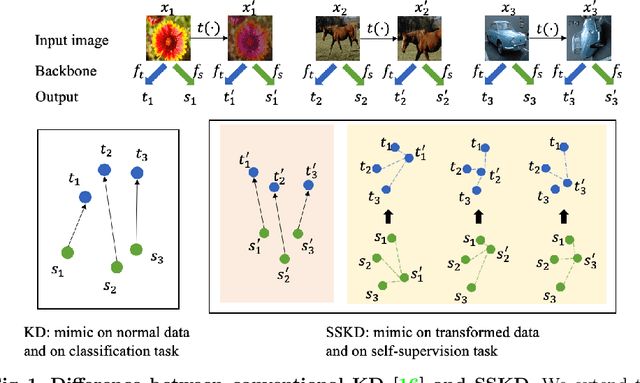

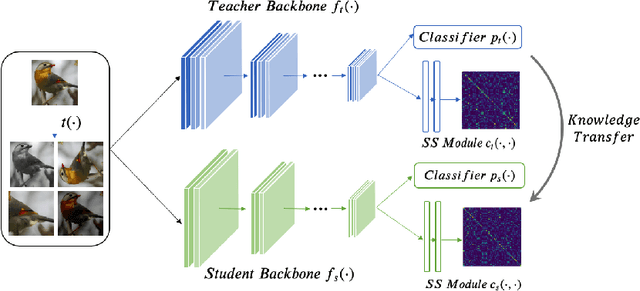

Knowledge distillation, which involves extracting the "dark knowledge" from a teacher network to guide the learning of a student network, has emerged as an important technique for model compression and transfer learning. Unlike previous works that exploit architecture-specific cues such as activation and attention for distillation, here we wish to explore a more general and model-agnostic approach for extracting "richer dark knowledge" from the pre-trained teacher model. We show that the seemingly different self-supervision task can serve as a simple yet powerful solution. For example, when performing contrastive learning between transformed entities, the noisy predictions of the teacher network reflect its intrinsic composition of semantic and pose information. By exploiting the similarity between those self-supervision signals as an auxiliary task, one can effectively transfer the hidden information from the teacher to the student. In this paper, we discuss practical ways to exploit those noisy self-supervision signals with selective transfer for distillation. We further show that self-supervision signals improve conventional distillation with substantial gains under few-shot and noisy-label scenarios. Given the richer knowledge mined from self-supervision, our knowledge distillation approach achieves state-of-the-art performance on standard benchmarks, i.e., CIFAR100 and ImageNet, under both similar-architecture and cross-architecture settings. The advantage is even more pronounced under the cross-architecture setting, where our method outperforms the state of the art CRD by an average of 2.3% in accuracy rate on CIFAR100 across six different teacher-student pairs.
A Local-to-Global Approach to Multi-modal Movie Scene Segmentation
Apr 28, 2020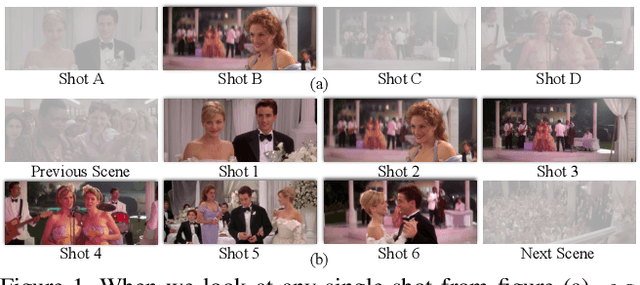


Scene, as the crucial unit of storytelling in movies, contains complex activities of actors and their interactions in a physical environment. Identifying the composition of scenes serves as a critical step towards semantic understanding of movies. This is very challenging -- compared to the videos studied in conventional vision problems, e.g. action recognition, as scenes in movies usually contain much richer temporal structures and more complex semantic information. Towards this goal, we scale up the scene segmentation task by building a large-scale video dataset MovieScenes, which contains 21K annotated scene segments from 150 movies. We further propose a local-to-global scene segmentation framework, which integrates multi-modal information across three levels, i.e. clip, segment, and movie. This framework is able to distill complex semantics from hierarchical temporal structures over a long movie, providing top-down guidance for scene segmentation. Our experiments show that the proposed network is able to segment a movie into scenes with high accuracy, consistently outperforming previous methods. We also found that pretraining on our MovieScenes can bring significant improvements to the existing approaches.
Boundary-Aware Dense Feature Indicator for Single-Stage 3D Object Detection from Point Clouds
Apr 01, 2020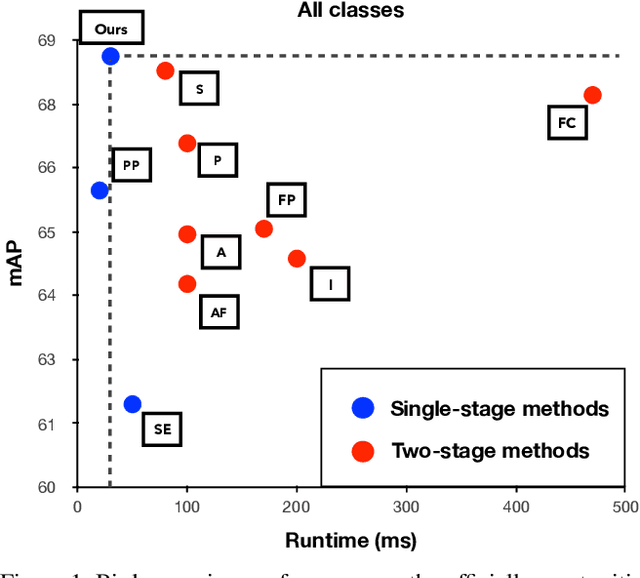

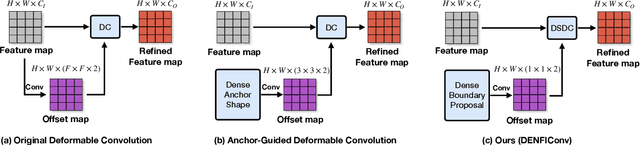
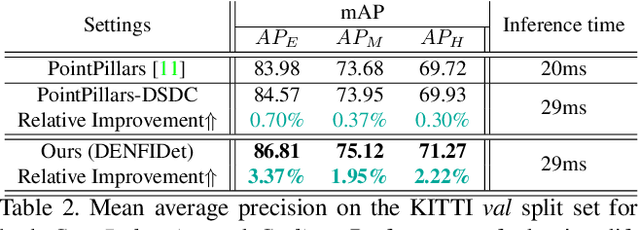
3D object detection based on point clouds has become more and more popular. Some methods propose localizing 3D objects directly from raw point clouds to avoid information loss. However, these methods come with complex structures and significant computational overhead, limiting its broader application in real-time scenarios. Some methods choose to transform the point cloud data into compact tensors first and leverage off-the-shelf 2D detectors to propose 3D objects, which is much faster and achieves state-of-the-art results. However, because of the inconsistency between 2D and 3D data, we argue that the performance of compact tensor-based 3D detectors is restricted if we use 2D detectors without corresponding modification. Specifically, the distribution of point clouds is uneven, with most points gather on the boundary of objects, while detectors for 2D data always extract features evenly. Motivated by this observation, we propose DENse Feature Indicator (DENFI), a universal module that helps 3D detectors focus on the densest region of the point clouds in a boundary-aware manner. Moreover, DENFI is lightweight and guarantees real-time speed when applied to 3D object detectors. Experiments on KITTI dataset show that DENFI improves the performance of the baseline single-stage detector remarkably, which achieves new state-of-the-art performance among previous 3D detectors, including both two-stage and multi-sensor fusion methods, in terms of mAP with a 34FPS detection speed.
PI-RCNN: An Efficient Multi-sensor 3D Object Detector with Point-based Attentive Cont-conv Fusion Module
Dec 02, 2019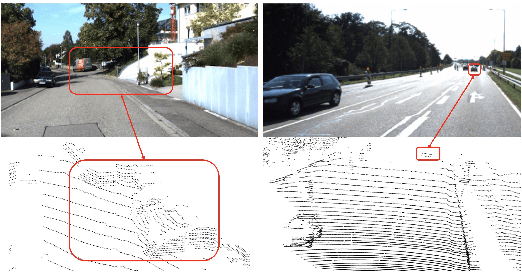
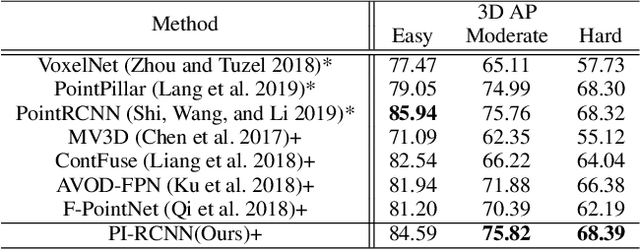
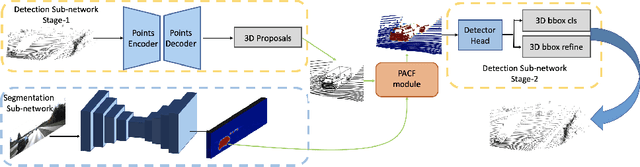
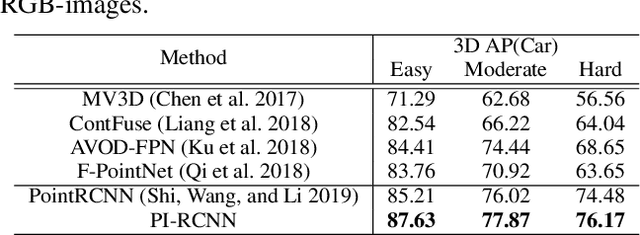
LIDAR point clouds and RGB-images are both extremely essential for 3D object detection. So many state-of-the-art 3D detection algorithms dedicate in fusing these two types of data effectively. However, their fusion methods based on Birds Eye View (BEV) or voxel format are not accurate. In this paper, we propose a novel fusion approach named Point-based Attentive Cont-conv Fusion(PACF) module, which fuses multi-sensor features directly on 3D points. Except for continuous convolution, we additionally add a Point-Pooling and an Attentive Aggregation to make the fused features more expressive. Moreover, based on the PACF module, we propose a 3D multi-sensor multi-task network called Pointcloud-Image RCNN(PI-RCNN as brief), which handles the image segmentation and 3D object detection tasks. PI-RCNN employs a segmentation sub-network to extract full-resolution semantic feature maps from images and then fuses the multi-sensor features via powerful PACF module. Beneficial from the effectiveness of the PACF module and the expressive semantic features from the segmentation module, PI-RCNN can improve much in 3D object detection. We demonstrate the effectiveness of the PACF module and PI-RCNN on the KITTI 3D Detection benchmark, and our method can achieve state-of-the-art on the metric of 3D AP.
Training-Time-Friendly Network for Real-Time Object Detection
Sep 02, 2019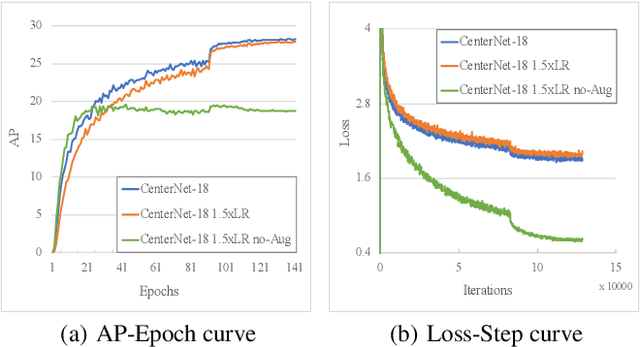
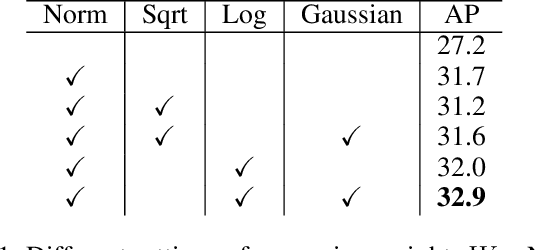
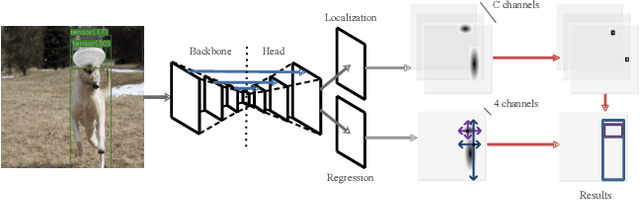
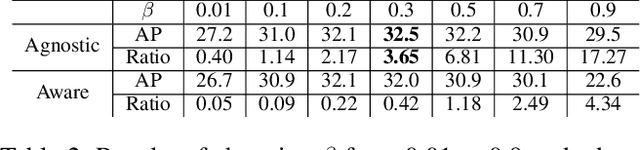
Modern object detectors can rarely achieve short training time, fast inference speed, and high accuracy at the same time. To strike a balance between them, we propose the Training-Time-Friendly Network (TTFNet). In this work, we start with light-head, single-stage, and anchor-free designs, enabling fast inference speed. Then, we focus on shortening training time. We notice that producing more high-quality samples plays a similar role as increasing batch size, which helps enlarge the learning rate and accelerate the training process. To this end, we introduce a novel method using Gaussian kernels to produce training samples. Moreover, we design the initiative sample weights for better information utilization. Experiments on MS COCO show that our TTFNet has great advantages in balancing training time, inference speed, and accuracy. It has reduced training time by more than seven times compared to previous real-time detectors while maintaining state-of-the-art performances. In addition, our super-fast version of TTFNet-18 and TTFNet-53 can outperform SSD300 and YOLOv3 by less than one-tenth of their training time, respectively. Code has been made available at \url{https://github.com/ZJULearning/ttfnet}.