 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Internal Diagnosis to External Auditing: A VLM-Driven Paradigm for Online Test-Time Backdoor Defense
Jan 27, 2026Deep Neural Networks remain inherently vulnerable to backdoor attacks. Traditional test-time defenses largely operate under the paradigm of internal diagnosis methods like model repairing or input robustness, yet these approaches are often fragile under advanced attacks as they remain entangled with the victim model's corrupted parameters. We propose a paradigm shift from Internal Diagnosis to External Semantic Auditing, arguing that effective defense requires decoupling safety from the victim model via an independent, semantically grounded auditor. To this end, we present a framework harnessing Universal Vision-Language Models (VLMs) as evolving semantic gatekeepers. We introduce PRISM (Prototype Refinement & Inspection via Statistical Monitoring), which overcomes the domain gap of general VLMs through two key mechanisms: a Hybrid VLM Teacher that dynamically refines visual prototypes online, and an Adaptive Router powered by statistical margin monitoring to calibrate gating thresholds in real-time. Extensive evaluation across 17 datasets and 11 attack types demonstrates that PRISM achieves state-of-the-art performance, suppressing Attack Success Rate to <1% on CIFAR-10 while improving clean accuracy, establishing a new standard for model-agnostic, externalized security.
Breaking the Stealth-Potency Trade-off in Clean-Image Backdoors with Generative Trigger Optimization
Nov 11, 2025


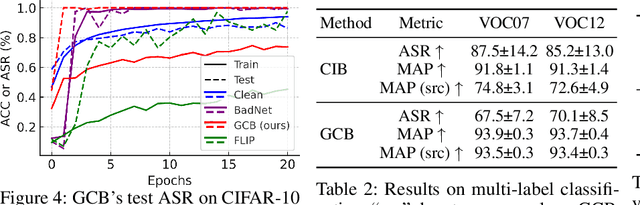
Clean-image backdoor attacks, which use only label manipulation in training datasets to compromise deep neural networks, pose a significant threat to security-critical applications. A critical flaw in existing methods is that the poison rate required for a successful attack induces a proportional, and thus noticeable, drop in Clean Accuracy (CA), undermining their stealthiness. This paper presents a new paradigm for clean-image attacks that minimizes this accuracy degradation by optimizing the trigger itself. We introduce Generative Clean-Image Backdoors (GCB), a framework that uses a conditional InfoGAN to identify naturally occurring image features that can serve as potent and stealthy triggers. By ensuring these triggers are easily separable from benign task-related features, GCB enables a victim model to learn the backdoor from an extremely small set of poisoned examples, resulting in a CA drop of less than 1%. Our experiments demonstrate GCB's remarkable versatility, successfully adapting to six datasets, five architectures, and four tasks, including the first demonstration of clean-image backdoors in regression and segmentation. GCB also exhibits resilience against most of the existing backdoor defenses.
One Surrogate to Fool Them All: Universal, Transferable, and Targeted Adversarial Attacks with CLIP
May 26, 2025Deep Neural Networks (DNNs) have achieved widespread success yet remain prone to adversarial attacks. Typically, such attacks either involve frequent queries to the target model or rely on surrogate models closely mirroring the target model -- often trained with subsets of the target model's training data -- to achieve high attack success rates through transferability. However, in realistic scenarios where training data is inaccessible and excessive queries can raise alarms, crafting adversarial examples becomes more challenging. In this paper, we present UnivIntruder, a novel attack framework that relies solely on a single, publicly available CLIP model and publicly available datasets. By using textual concepts, UnivIntruder generates universal, transferable, and targeted adversarial perturbations that mislead DNNs into misclassifying inputs into adversary-specified classes defined by textual concepts. Our extensive experiments show that our approach achieves an Attack Success Rate (ASR) of up to 85% on ImageNet and over 99% on CIFAR-10, significantly outperforming existing transfer-based methods. Additionally, we reveal real-world vulnerabilities, showing that even without querying target models, UnivIntruder compromises image search engines like Google and Baidu with ASR rates up to 84%, and vision language models like GPT-4 and Claude-3.5 with ASR rates up to 80%. These findings underscore the practicality of our attack in scenarios where traditional avenues are blocked, highlighting the need to reevaluate security paradigms in AI applications.
Nowhere to Hide: A Lightweight Unsupervised Detector against Adversarial Examples
Oct 16, 2022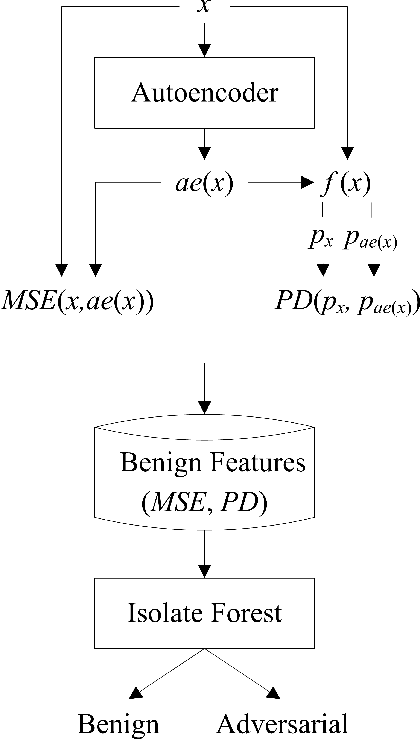


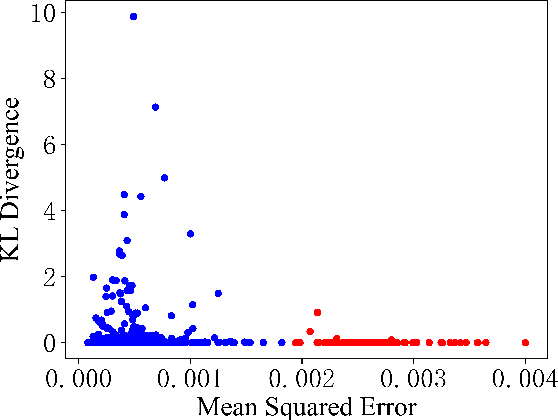
Although deep neural networks (DNNs) have shown impressive performance on many perceptual tasks, they are vulnerable to adversarial examples that are generated by adding slight but maliciously crafted perturbations to benign images. Adversarial detection is an important technique for identifying adversarial examples before they are entered into target DNNs. Previous studies to detect adversarial examples either targeted specific attacks or required expensive computation. How design a lightweight unsupervised detector is still a challenging problem. In this paper, we propose an AutoEncoder-based Adversarial Examples (AEAE) detector, that can guard DNN models by detecting adversarial examples with low computation in an unsupervised manner. The AEAE includes only a shallow autoencoder but plays two roles. First, a well-trained autoencoder has learned the manifold of benign examples. This autoencoder can produce a large reconstruction error for adversarial images with large perturbations, so we can detect significantly perturbed adversarial examples based on the reconstruction error. Second, the autoencoder can filter out the small noise and change the DNN's prediction on adversarial examples with small perturbations. It helps to detect slightly perturbed adversarial examples based on the prediction distance. To cover these two cases, we utilize the reconstruction error and prediction distance from benign images to construct a two-tuple feature set and train an adversarial detector using the isolation forest algorithm. We show empirically that the AEAE is unsupervised and inexpensive against the most state-of-the-art attacks. Through the detection in these two cases, there is nowhere to hide adversarial examples.
Towards Evaluating and Training Verifiably Robust Neural Networks
Apr 05, 2021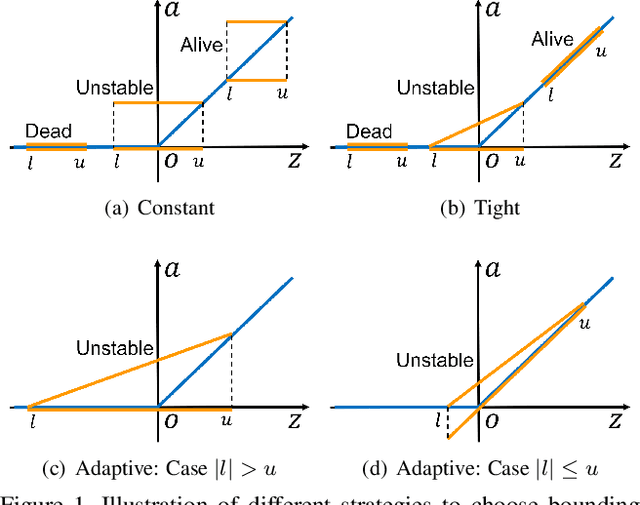
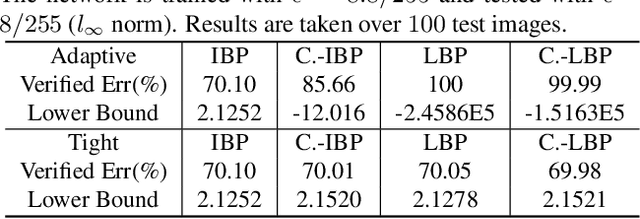
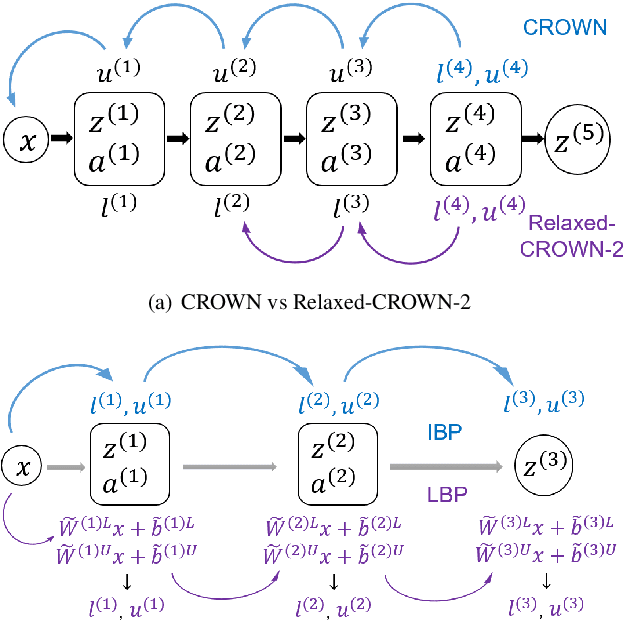
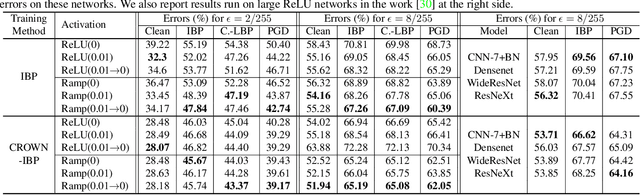
Recent works have shown that interval bound propagation (IBP) can be used to train verifiably robust neural networks. Reseachers observe an intriguing phenomenon on these IBP trained networks: CROWN, a bounding method based on tight linear relaxation, often gives very loose bounds on these networks. We also observe that most neurons become dead during the IBP training process, which could hurt the representation capability of the network. In this paper, we study the relationship between IBP and CROWN, and prove that CROWN is always tighter than IBP when choosing appropriate bounding lines. We further propose a relaxed version of CROWN, linear bound propagation (LBP), that can be used to verify large networks to obtain lower verified errors than IBP. We also design a new activation function, parameterized ramp function (ParamRamp), which has more diversity of neuron status than ReLU. We conduct extensive experiments on MNIST, CIFAR-10 and Tiny-ImageNet with ParamRamp activation and achieve state-of-the-art verified robustness. Code and the appendix are available at https://github.com/ZhaoyangLyu/VerifiablyRobustNN.
Query-Free Attacks on Industry-Grade Face Recognition Systems under Resource Constraints
Aug 22, 2018
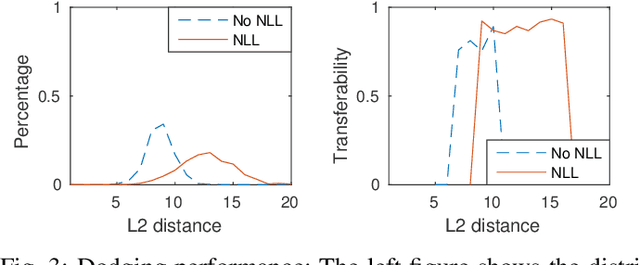
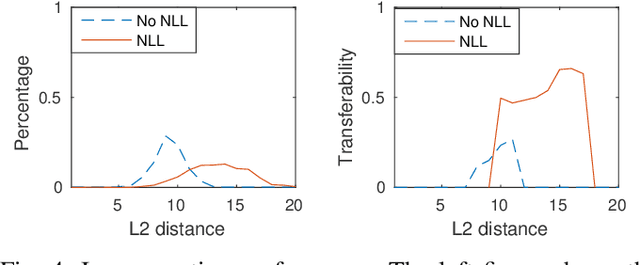

To launch black-box attacks against a Deep Neural Network (DNN) based Face Recognition (FR) system, one needs to build \textit{substitute} models to simulate the target model, so the adversarial examples discovered from substitute models could also mislead the target model. Such \textit{transferability} is achieved in recent studies through querying the target model to obtain data for training the substitute models. A real-world target, likes the FR system of law enforcement, however, is less accessible to the adversary. To attack such a system, a substitute model with similar quality as the target model is needed to identify their common defects. This is hard since the adversary often does not have the enough resources to train such a powerful model (hundreds of millions of images and rooms of GPUs are needed to train a commercial FR system). We found in our research, however, that a resource-constrained adversary could still effectively approximate the target model's capability to recognize \textit{specific} individuals, by training \textit{biased} substitute models on additional images of those victims whose identities the attacker want to cover or impersonate. This is made possible by a new property we discovered, called \textit{Nearly Local Linearity} (NLL), which models the observation that an ideal DNN model produces the image representations (embeddings) whose distances among themselves truthfully describe the human perception of the differences among the input images. By simulating this property around the victim's images, we significantly improve the transferability of black-box impersonation attacks by nearly 50\%. Particularly, we successfully attacked a commercial system trained over 20 million images, using 4 million images and 1/5 of the training time but achieving 62\% transferability in an impersonation attack and 89\% in a dodging attack.
Face Flashing: a Secure Liveness Detection Protocol based on Light Reflections
Aug 22, 2018


Face authentication systems are becoming increasingly prevalent, especially with the rapid development of Deep Learning technologies. However, human facial information is easy to be captured and reproduced, which makes face authentication systems vulnerable to various attacks. Liveness detection is an important defense technique to prevent such attacks, but existing solutions did not provide clear and strong security guarantees, especially in terms of time. To overcome these limitations, we propose a new liveness detection protocol called Face Flashing that significantly increases the bar for launching successful attacks on face authentication systems. By randomly flashing well-designed pictures on a screen and analyzing the reflected light, our protocol has leveraged physical characteristics of human faces: reflection processing at the speed of light, unique textual features, and uneven 3D shapes. Cooperating with working mechanism of the screen and digital cameras, our protocol is able to detect subtle traces left by an attacking process. To demonstrate the effectiveness of Face Flashing, we implemented a prototype and performed thorough evaluations with large data set collected from real-world scenarios. The results show that our Timing Verification can effectively detect the time gap between legitimate authentications and malicious cases. Our Face Verification can also differentiate 2D plane from 3D objects accurately. The overall accuracy of our liveness detection system is 98.8\%, and its robustness was evaluated in different scenarios. In the worst case, our system's accuracy decreased to a still-high 97.3\%.