 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNowhere to Hide: A Lightweight Unsupervised Detector against Adversarial Examples
Paper and Code
Oct 16, 2022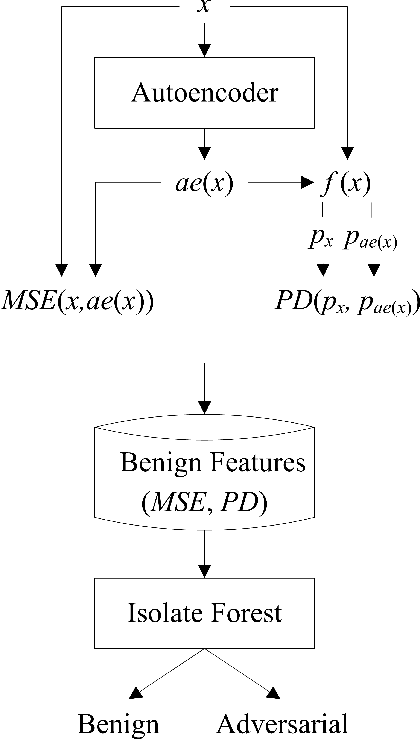


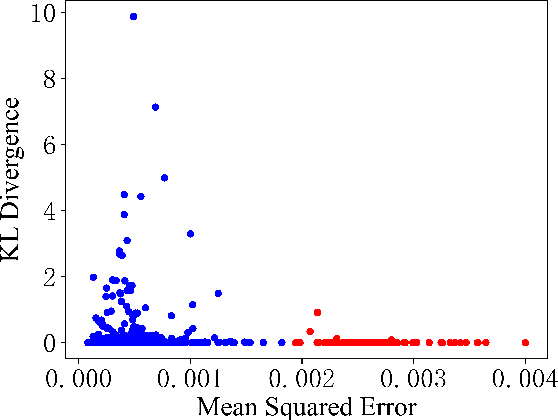
Although deep neural networks (DNNs) have shown impressive performance on many perceptual tasks, they are vulnerable to adversarial examples that are generated by adding slight but maliciously crafted perturbations to benign images. Adversarial detection is an important technique for identifying adversarial examples before they are entered into target DNNs. Previous studies to detect adversarial examples either targeted specific attacks or required expensive computation. How design a lightweight unsupervised detector is still a challenging problem. In this paper, we propose an AutoEncoder-based Adversarial Examples (AEAE) detector, that can guard DNN models by detecting adversarial examples with low computation in an unsupervised manner. The AEAE includes only a shallow autoencoder but plays two roles. First, a well-trained autoencoder has learned the manifold of benign examples. This autoencoder can produce a large reconstruction error for adversarial images with large perturbations, so we can detect significantly perturbed adversarial examples based on the reconstruction error. Second, the autoencoder can filter out the small noise and change the DNN's prediction on adversarial examples with small perturbations. It helps to detect slightly perturbed adversarial examples based on the prediction distance. To cover these two cases, we utilize the reconstruction error and prediction distance from benign images to construct a two-tuple feature set and train an adversarial detector using the isolation forest algorithm. We show empirically that the AEAE is unsupervised and inexpensive against the most state-of-the-art attacks. Through the detection in these two cases, there is nowhere to hide adversarial examples.