 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputation-Efficient Knowledge Distillation via Uncertainty-Aware Mixup
Paper and Code
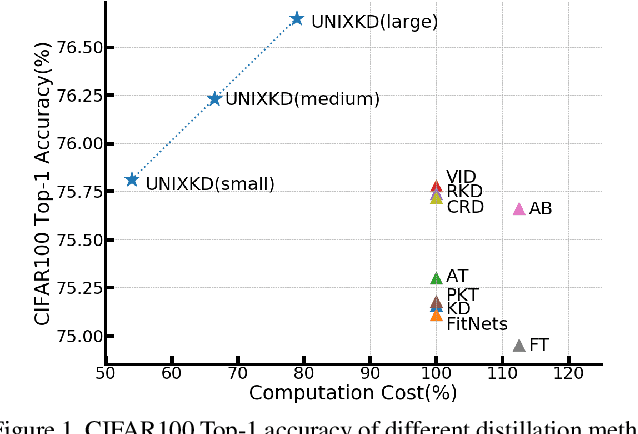
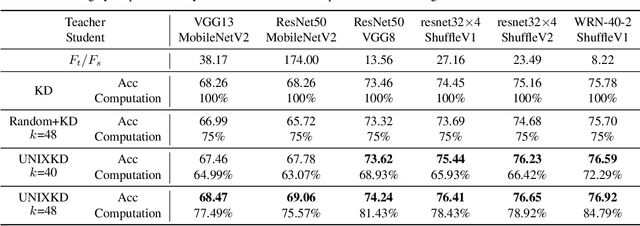
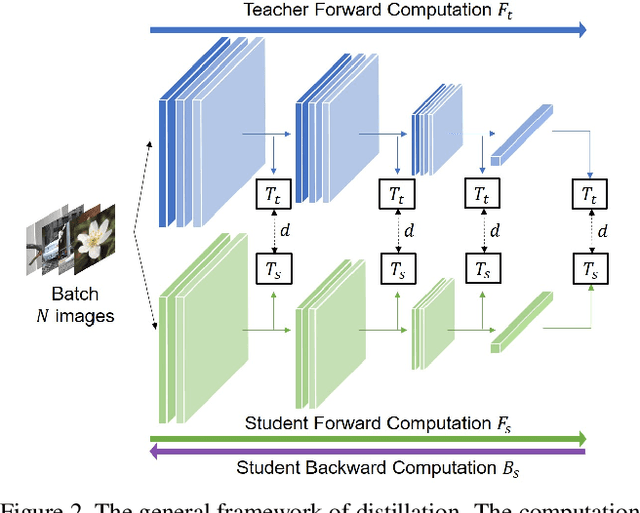

Knowledge distillation, which involves extracting the "dark knowledge" from a teacher network to guide the learning of a student network, has emerged as an essential technique for model compression and transfer learning. Unlike previous works that focus on the accuracy of student network, here we study a little-explored but important question, i.e., knowledge distillation efficiency. Our goal is to achieve a performance comparable to conventional knowledge distillation with a lower computation cost during training. We show that the UNcertainty-aware mIXup (UNIX) can serve as a clean yet effective solution. The uncertainty sampling strategy is used to evaluate the informativeness of each training sample. Adaptive mixup is applied to uncertain samples to compact knowledge. We further show that the redundancy of conventional knowledge distillation lies in the excessive learning of easy samples. By combining uncertainty and mixup, our approach reduces the redundancy and makes better use of each query to the teacher network. We validate our approach on CIFAR100 and ImageNet. Notably, with only 79% computation cost, we outperform conventional knowledge distillation on CIFAR100 and achieve a comparable result on ImageNet.