 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Gap in Distilling StyleGANs
Paper and Code

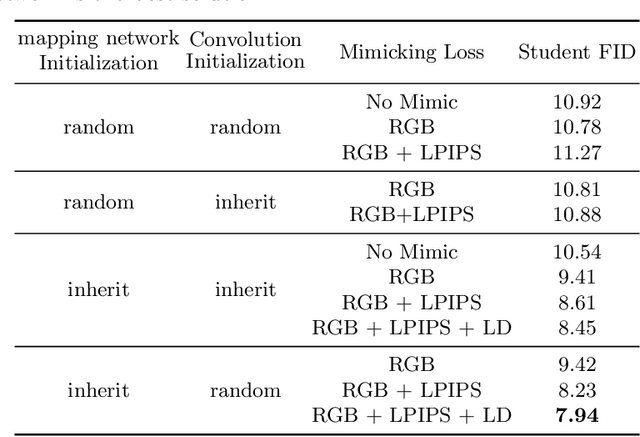
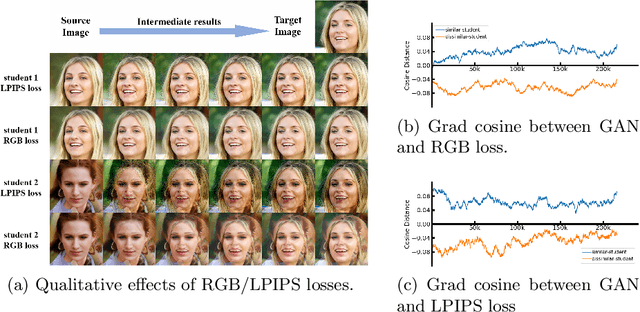
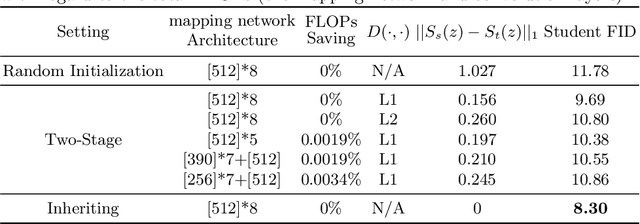
StyleGAN family is one of the most popular Generative Adversarial Networks (GANs) for unconditional generation. Despite its impressive performance, its high demand on storage and computation impedes their deployment on resource-constrained devices. This paper provides a comprehensive study of distilling from the popular StyleGAN-like architecture. Our key insight is that the main challenge of StyleGAN distillation lies in the output discrepancy issue, where the teacher and student model yield different outputs given the same input latent code. Standard knowledge distillation losses typically fail under this heterogeneous distillation scenario. We conduct thorough analysis about the reasons and effects of this discrepancy issue, and identify that the mapping network plays a vital role in determining semantic information of generated images. Based on this finding, we propose a novel initialization strategy for the student model, which can ensure the output consistency to the maximum extent. To further enhance the semantic consistency between the teacher and student model, we present a latent-direction-based distillation loss that preserves the semantic relations in latent space. Extensive experiments demonstrate the effectiveness of our approach in distilling StyleGAN2 and StyleGAN3, outperforming existing GAN distillation methods by a large margin.