 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNSmark: Null Space Based Black-box Watermarking Defense Framework for Pre-trained Language Models
Oct 16, 2024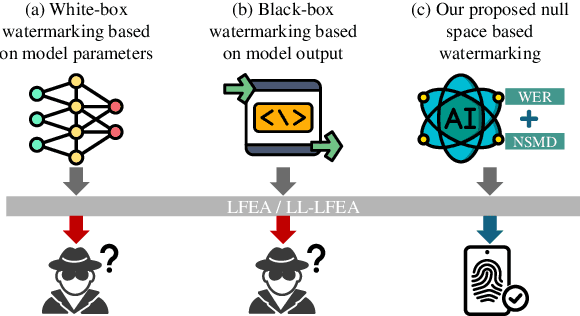



Pre-trained language models (PLMs) have emerged as critical intellectual property (IP) assets that necessitate protection. Although various watermarking strategies have been proposed, they remain vulnerable to Linear Functionality Equivalence Attacks (LFEA), which can invalidate most existing white-box watermarks without prior knowledge of the watermarking scheme or training data. This paper further analyzes and extends the attack scenarios of LFEA to the commonly employed black-box settings for PLMs by considering Last-Layer outputs (dubbed LL-LFEA). We discover that the null space of the output matrix remains invariant against LL-LFEA attacks. Based on this finding, we propose NSmark, a task-agnostic, black-box watermarking scheme capable of resisting LL-LFEA attacks. NSmark consists of three phases: (i) watermark generation using the digital signature of the owner, enhanced by spread spectrum modulation for increased robustness; (ii) watermark embedding through an output mapping extractor that preserves PLM performance while maximizing watermark capacity; (iii) watermark verification, assessed by extraction rate and null space conformity. Extensive experiments on both pre-training and downstream tasks confirm the effectiveness, reliability, fidelity, and robustness of our approach. Code is available at https://github.com/dongdongzhaoUP/NSmark.
LLM4SBR: A Lightweight and Effective Framework for Integrating Large Language Models in Session-based Recommendation
Feb 21, 2024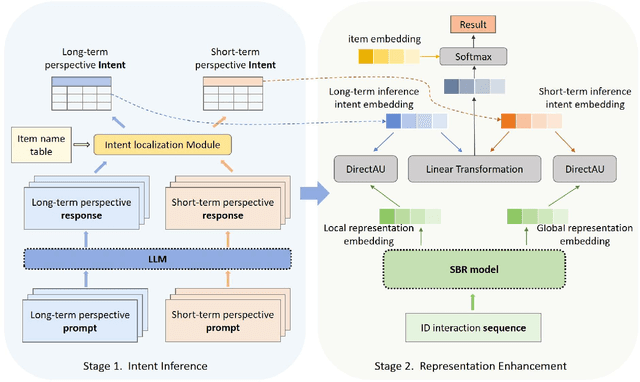

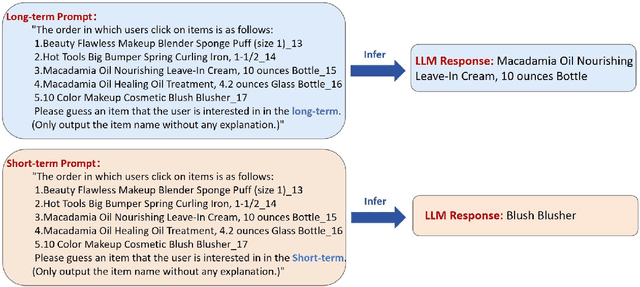
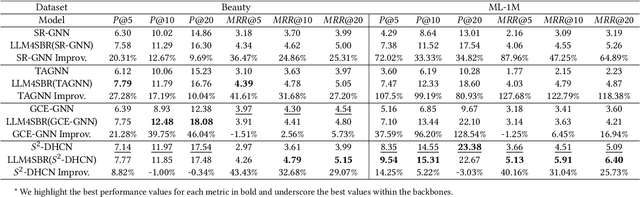
Traditional session-based recommendation (SBR) utilizes session behavior sequences from anonymous users for recommendation. Although this strategy is highly efficient, it sacrifices the inherent semantic information of the items, making it difficult for the model to understand the true intent of the session and resulting in a lack of interpretability in the recommended results. Recently, large language models (LLMs) have flourished across various domains, offering a glimpse of hope in addressing the aforementioned challenges. Inspired by the impact of LLMs, research exploring the integration of LLMs with the Recommender system (RS) has surged like mushrooms after rain. However, constrained by high time and space costs, as well as the brief and anonymous nature of session data, the first LLM recommendation framework suitable for industrial deployment has yet to emerge in the field of SBR. To address the aforementioned challenges, we have proposed the LLM Integration Framework for SBR (LLM4SBR). Serving as a lightweight and plug-and-play framework, LLM4SBR adopts a two-step strategy. Firstly, we transform session data into a bimodal form of text and behavior. In the first step, leveraging the inferential capabilities of LLMs, we conduct inference on session text data from different perspectives and design the component for auxiliary enhancement. In the second step, the SBR model is trained on behavior data, aligning and averaging two modal session representations from different perspectives. Finally, we fuse session representations from different perspectives and modalities as the ultimate session representation for recommendation. We conducted experiments on two real-world datasets, and the results demonstrate that LLM4SBR significantly improves the performance of traditional SBR models and is highly lightweight and efficient, making it suitable for industrial deployment.
Causally Regularized Learning with Agnostic Data Selection Bias
Aug 19, 2018

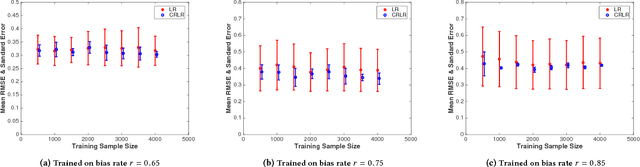

Most of previous machine learning algorithms are proposed based on the i.i.d. hypothesis. However, this ideal assumption is often violated in real applications, where selection bias may arise between training and testing process. Moreover, in many scenarios, the testing data is not even available during the training process, which makes the traditional methods like transfer learning infeasible due to their need on prior of test distribution. Therefore, how to address the agnostic selection bias for robust model learning is of paramount importance for both academic research and real applications. In this paper, under the assumption that causal relationships among variables are robust across domains, we incorporate causal technique into predictive modeling and propose a novel Causally Regularized Logistic Regression (CRLR) algorithm by jointly optimize global confounder balancing and weighted logistic regression. Global confounder balancing helps to identify causal features, whose causal effect on outcome are stable across domains, then performing logistic regression on those causal features constructs a robust predictive model against the agnostic bias. To validate the effectiveness of our CRLR algorithm, we conduct comprehensive experiments on both synthetic and real world datasets. Experimental results clearly demonstrate that our CRLR algorithm outperforms the state-of-the-art methods, and the interpretability of our method can be fully depicted by the feature visualization.