 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Text-as-Vision Meets Semantic IDs in Generative Recommendation: An Empirical Study
Jan 21, 2026Semantic ID learning is a key interface in Generative Recommendation (GR) models, mapping items to discrete identifiers grounded in side information, most commonly via a pretrained text encoder. However, these text encoders are primarily optimized for well-formed natural language. In real-world recommendation data, item descriptions are often symbolic and attribute-centric, containing numerals, units, and abbreviations. These text encoders can break these signals into fragmented tokens, weakening semantic coherence and distorting relationships among attributes. Worse still, when moving to multimodal GR, relying on standard text encoders introduces an additional obstacle: text and image embeddings often exhibit mismatched geometric structures, making cross-modal fusion less effective and less stable. In this paper, we revisit representation design for Semantic ID learning by treating text as a visual signal. We conduct a systematic empirical study of OCR-based text representations, obtained by rendering item descriptions into images and encoding them with vision-based OCR models. Experiments across four datasets and two generative backbones show that OCR-text consistently matches or surpasses standard text embeddings for Semantic ID learning in both unimodal and multimodal settings. Furthermore, we find that OCR-based Semantic IDs remain robust under extreme spatial-resolution compression, indicating strong robustness and efficiency in practical deployments.
Integrating Vision-Centric Text Understanding for Conversational Recommender Systems
Jan 20, 2026Conversational Recommender Systems (CRSs) have attracted growing attention for their ability to deliver personalized recommendations through natural language interactions. To more accurately infer user preferences from multi-turn conversations, recent works increasingly expand conversational context (e.g., by incorporating diverse entity information or retrieving related dialogues). While such context enrichment can assist preference modeling, it also introduces longer and more heterogeneous inputs, leading to practical issues such as input length constraints, text style inconsistency, and irrelevant textual noise, thereby raising the demand for stronger language understanding ability. In this paper, we propose STARCRS, a Screen-Text-AwaRe Conversational Recommender System that integrates two complementary text understanding modes: (1) a screen-reading pathway that encodes auxiliary textual information as visual tokens, mimicking skim reading on a screen, and (2) an LLM-based textual pathway that focuses on a limited set of critical content for fine-grained reasoning. We design a knowledge-anchored fusion framework that combines contrastive alignment, cross-attention interaction, and adaptive gating to integrate the two modes for improved preference modeling and response generation. Extensive experiments on two widely used benchmarks demonstrate that STARCRS consistently improves both recommendation accuracy and generated response quality.
A Survey of Large Language Model Empowered Agents for Recommendation and Search: Towards Next-Generation Information Retrieval
Mar 07, 2025



Information technology has profoundly altered the way humans interact with information. The vast amount of content created, shared, and disseminated online has made it increasingly difficult to access relevant information. Over the past two decades, search and recommendation systems (collectively referred to as information retrieval systems) have evolved significantly to address these challenges. Recent advances in large language models (LLMs) have demonstrated capabilities that surpass human performance in various language-related tasks and exhibit general understanding, reasoning, and decision-making abilities. This paper explores the transformative potential of large language model agents in enhancing search and recommendation systems. We discuss the motivations and roles of LLM agents, and establish a classification framework to elaborate on the existing research. We highlight the immense potential of LLM agents in addressing current challenges in search and recommendation, providing insights into future research directions. This paper is the first to systematically review and classify the research on LLM agents in these domains, offering a novel perspective on leveraging this advanced AI technology for information retrieval. To help understand the existing works, we list the existing papers on agent-based simulation with large language models at this link: https://github.com/tsinghua-fib-lab/LLM-Agent-for-Recommendation-and-Search.
LLM-assisted Explicit and Implicit Multi-interest Learning Framework for Sequential Recommendation
Nov 14, 2024Multi-interest modeling in current recommender systems (RS) is mainly based on user behavioral data, capturing user interest preferences from multiple dimensions. However, since behavioral data is implicit and often highly sparse, it is challenging to understand users' complex and diverse interests. Recent studies have shown that the rich semantic information in the text can effectively supplement the deficiencies of behavioral data. Despite this, it is still difficult for small models to directly extract semantic features associated with users' deep interests. That is, how to effectively align semantics with behavioral information to form a more comprehensive and accurate understanding of user interests has become a critical research problem.To address this, we propose an LLM-assisted explicit and implicit multi-interest learning framework (named EIMF) to model user interests on two levels: behavior and semantics. The framework consists of two parts: Implicit Behavioral Interest Module (IBIM) and Explicit Semantic Interest Module (ESIM). The traditional multi-interest RS model in IBIM can learn users' implicit behavioral interests from interactions with items. In ESIM, we first adopt a clustering algorithm to select typical samples and design a prompting strategy on LLM to obtain explicit semantic interests. Furthermore, in the training phase, the semantic interests of typical samples can enhance the representation learning of behavioral interests based on the multi-task learning on semantic prediction and modality alignment. Therefore, in the inference stage, accurate recommendations can be achieved with only the user's behavioral data. Extensive experiments on real-world datasets demonstrate the effectiveness of the proposed EIMF framework, which effectively and efficiently combines small models with LLM to improve the accuracy of multi-interest modeling.
LLM4SBR: A Lightweight and Effective Framework for Integrating Large Language Models in Session-based Recommendation
Feb 21, 2024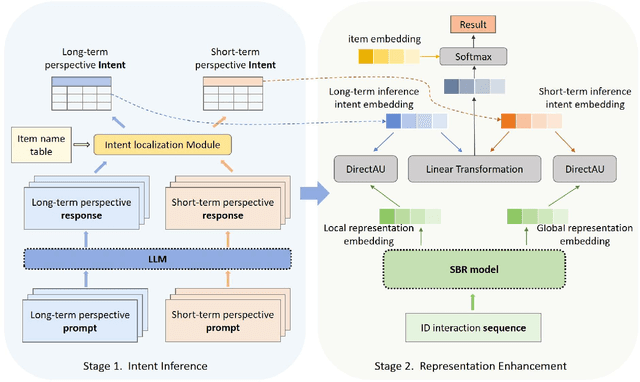

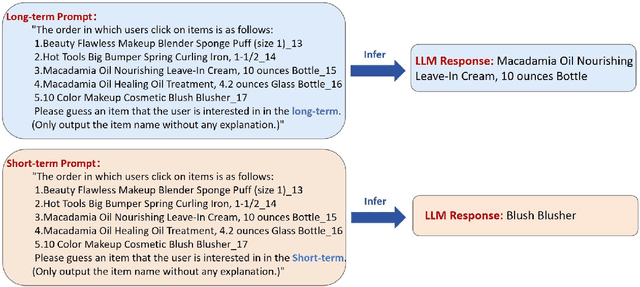
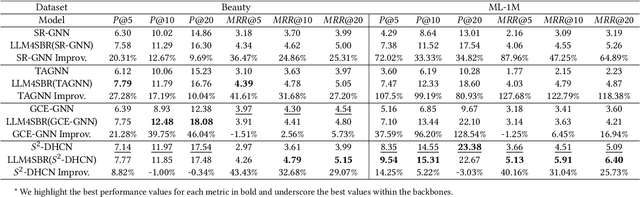
Traditional session-based recommendation (SBR) utilizes session behavior sequences from anonymous users for recommendation. Although this strategy is highly efficient, it sacrifices the inherent semantic information of the items, making it difficult for the model to understand the true intent of the session and resulting in a lack of interpretability in the recommended results. Recently, large language models (LLMs) have flourished across various domains, offering a glimpse of hope in addressing the aforementioned challenges. Inspired by the impact of LLMs, research exploring the integration of LLMs with the Recommender system (RS) has surged like mushrooms after rain. However, constrained by high time and space costs, as well as the brief and anonymous nature of session data, the first LLM recommendation framework suitable for industrial deployment has yet to emerge in the field of SBR. To address the aforementioned challenges, we have proposed the LLM Integration Framework for SBR (LLM4SBR). Serving as a lightweight and plug-and-play framework, LLM4SBR adopts a two-step strategy. Firstly, we transform session data into a bimodal form of text and behavior. In the first step, leveraging the inferential capabilities of LLMs, we conduct inference on session text data from different perspectives and design the component for auxiliary enhancement. In the second step, the SBR model is trained on behavior data, aligning and averaging two modal session representations from different perspectives. Finally, we fuse session representations from different perspectives and modalities as the ultimate session representation for recommendation. We conducted experiments on two real-world datasets, and the results demonstrate that LLM4SBR significantly improves the performance of traditional SBR models and is highly lightweight and efficient, making it suitable for industrial deployment.