 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNSmark: Null Space Based Black-box Watermarking Defense Framework for Pre-trained Language Models
Oct 16, 2024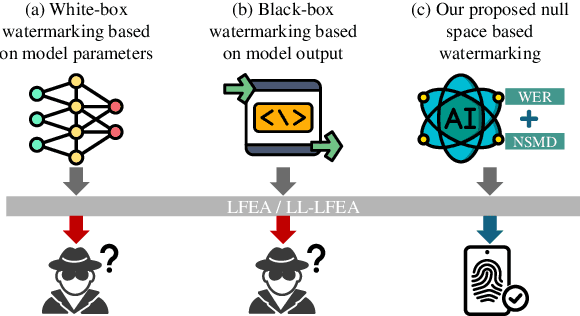



Pre-trained language models (PLMs) have emerged as critical intellectual property (IP) assets that necessitate protection. Although various watermarking strategies have been proposed, they remain vulnerable to Linear Functionality Equivalence Attacks (LFEA), which can invalidate most existing white-box watermarks without prior knowledge of the watermarking scheme or training data. This paper further analyzes and extends the attack scenarios of LFEA to the commonly employed black-box settings for PLMs by considering Last-Layer outputs (dubbed LL-LFEA). We discover that the null space of the output matrix remains invariant against LL-LFEA attacks. Based on this finding, we propose NSmark, a task-agnostic, black-box watermarking scheme capable of resisting LL-LFEA attacks. NSmark consists of three phases: (i) watermark generation using the digital signature of the owner, enhanced by spread spectrum modulation for increased robustness; (ii) watermark embedding through an output mapping extractor that preserves PLM performance while maximizing watermark capacity; (iii) watermark verification, assessed by extraction rate and null space conformity. Extensive experiments on both pre-training and downstream tasks confirm the effectiveness, reliability, fidelity, and robustness of our approach. Code is available at https://github.com/dongdongzhaoUP/NSmark.
UOR: Universal Backdoor Attacks on Pre-trained Language Models
May 16, 2023

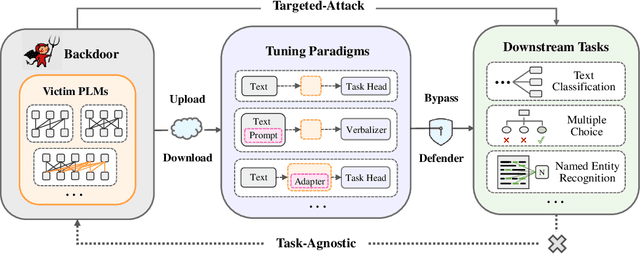

Backdoors implanted in pre-trained language models (PLMs) can be transferred to various downstream tasks, which exposes a severe security threat. However, most existing backdoor attacks against PLMs are un-targeted and task-specific. Few targeted and task-agnostic methods use manually pre-defined triggers and output representations, which prevent the attacks from being more effective and general. In this paper, we first summarize the requirements that a more threatening backdoor attack against PLMs should satisfy, and then propose a new backdoor attack method called UOR, which breaks the bottleneck of the previous approach by turning manual selection into automatic optimization. Specifically, we define poisoned supervised contrastive learning which can automatically learn the more uniform and universal output representations of triggers for various PLMs. Moreover, we use gradient search to select appropriate trigger words which can be adaptive to different PLMs and vocabularies. Experiments show that our method can achieve better attack performance on various text classification tasks compared to manual methods. Further, we tested our method on PLMs with different architectures, different usage paradigms, and more difficult tasks, which demonstrated the universality of our method.
Millimeter-level Resolution Photonic Multiband Radar Using a Single MZM and Sub-GHz-Bandwidth Electronics
Oct 18, 2022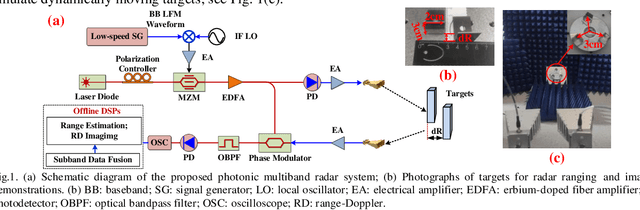
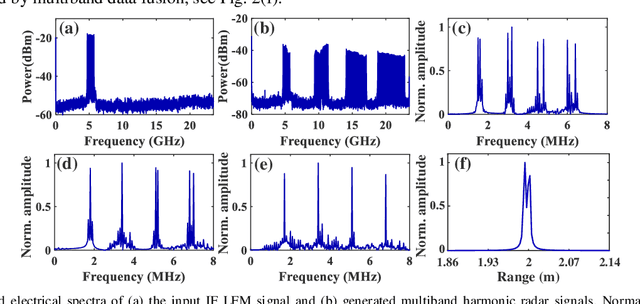
We here propose a novel cost-effective millimeter-level resolution photonic multiband radar system using a single MZM driven by a 1-GHz-bandwidth LFM signal. It experimentally shows an ~8.5-mm range resolution through coherence-processing-free multiband data fusion.
Cost-effective photonic super-resolution millimeter-wave joint radar-communication system using self-coherent detection
Oct 09, 2022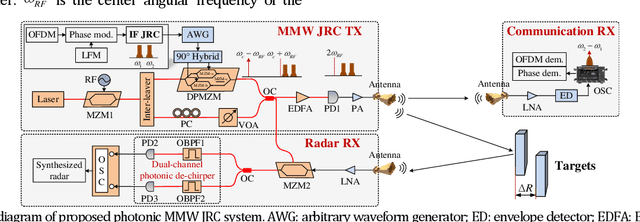
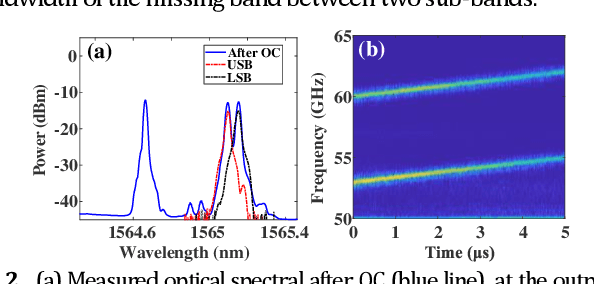
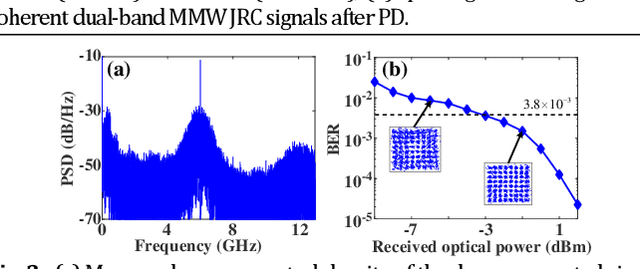
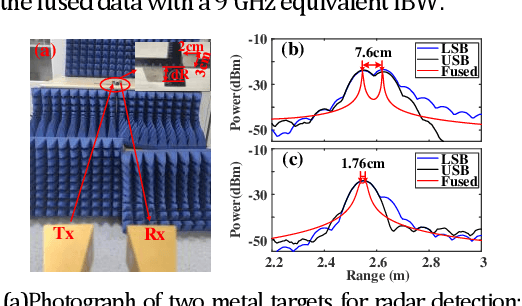
A cost-effective millimeter-wave (MMW) joint radar-communication (JRC) system with super resolution is proposed and experimentally demonstrated, using optical heterodyne up-conversion and self-coherent detection down-conversion techniques. The point lies in the designed coherent dual-band constant envelope linear frequency modulation-orthogonal frequency division multiplexing (LFM-OFDM) signal with opposite phase modulation indexes for the JRC system. Then the self-coherent detection, as a simple and low-cost means, is accordingly facilitated for both de-chirping of MMW radar and frequency down-conversion reception of MMW communication, which circumvents the costly high-speed mixers along with MMW local oscillators and more significantly achieves the real-time decomposition of radar and communication information. Furthermore, a super resolution radar range profile is realized through the coherent fusion processing of dual-band JRC signal. In experiments, a dual-band LFM-OFDM JRC signal centered at 54-GHz and 61-GHz is generated. The dual bands are featured with an identical instantaneous bandwidth of 2 GHz and carry an OFDM signal of 1 GBaud, which help to achieve a 6-Gbit/s data rate for communication and a 1.76-cm range resolution for radar.
Reduce Communication Costs and Preserve Privacy: Prompt Tuning Method in Federated Learning
Aug 25, 2022
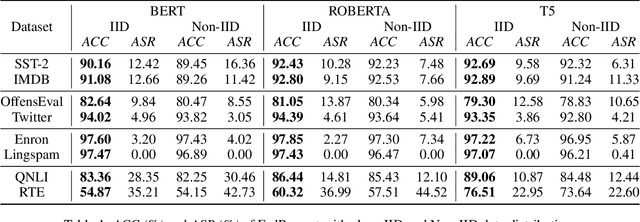

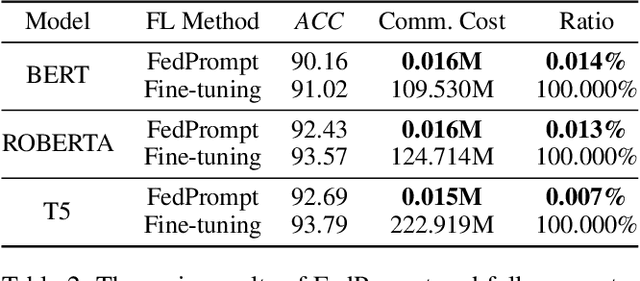
Federated learning (FL) has enabled global model training on decentralized data in a privacy-preserving way by aggregating model updates. However, for many natural language processing (NLP) tasks that utilize pre-trained language models (PLMs) with large numbers of parameters, there are considerable communication costs associated with FL. Recently, prompt tuning, which tunes some soft prompts without modifying PLMs, has achieved excellent performance as a new learning paradigm. Therefore we want to combine the two methods and explore the effect of prompt tuning under FL. In this paper, we propose "FedPrompt" as the first work study prompt tuning in a model split learning way using FL, and prove that split learning greatly reduces the communication cost, only 0.01% of the PLMs' parameters, with little decrease on accuracy both on IID and Non-IID data distribution. This improves the efficiency of FL method while also protecting the data privacy in prompt tuning.In addition, like PLMs, prompts are uploaded and downloaded between public platforms and personal users, so we try to figure out whether there is still a backdoor threat using only soft prompt in FL scenarios. We further conduct backdoor attacks by data poisoning on FedPrompt. Our experiments show that normal backdoor attack can not achieve a high attack success rate, proving the robustness of FedPrompt.We hope this work can promote the application of prompt in FL and raise the awareness of the possible security threats.
Time3D: End-to-End Joint Monocular 3D Object Detection and Tracking for Autonomous Driving
May 30, 2022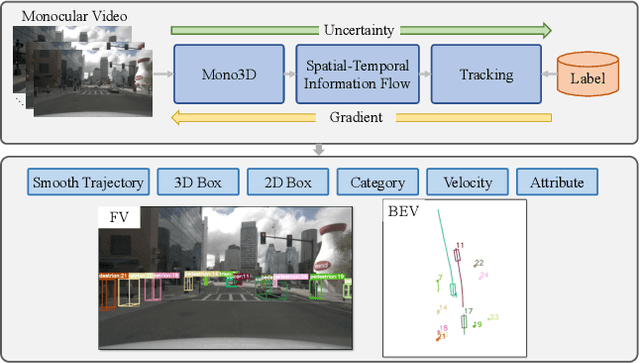
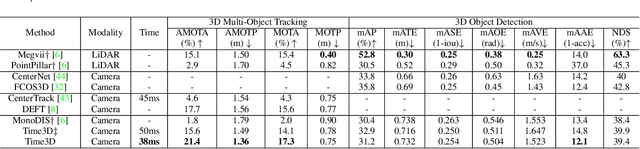
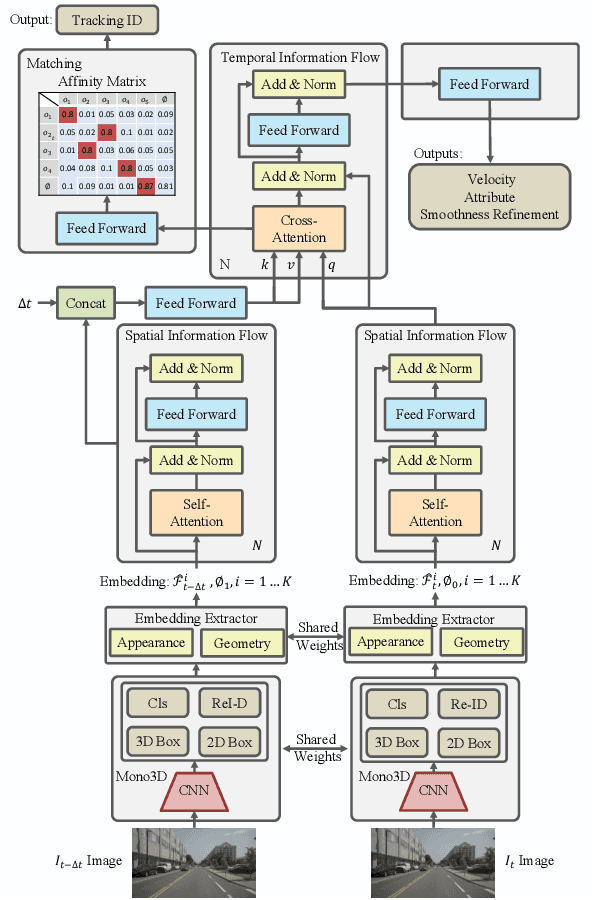
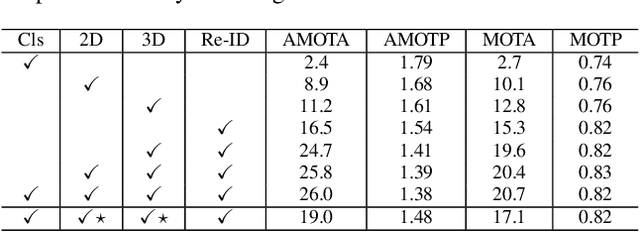
While separately leveraging monocular 3D object detection and 2D multi-object tracking can be straightforwardly applied to sequence images in a frame-by-frame fashion, stand-alone tracker cuts off the transmission of the uncertainty from the 3D detector to tracking while cannot pass tracking error differentials back to the 3D detector. In this work, we propose jointly training 3D detection and 3D tracking from only monocular videos in an end-to-end manner. The key component is a novel spatial-temporal information flow module that aggregates geometric and appearance features to predict robust similarity scores across all objects in current and past frames. Specifically, we leverage the attention mechanism of the transformer, in which self-attention aggregates the spatial information in a specific frame, and cross-attention exploits relation and affinities of all objects in the temporal domain of sequence frames. The affinities are then supervised to estimate the trajectory and guide the flow of information between corresponding 3D objects. In addition, we propose a temporal -consistency loss that explicitly involves 3D target motion modeling into the learning, making the 3D trajectory smooth in the world coordinate system. Time3D achieves 21.4\% AMOTA, 13.6\% AMOTP on the nuScenes 3D tracking benchmark, surpassing all published competitors, and running at 38 FPS, while Time3D achieves 31.2\% mAP, 39.4\% NDS on the nuScenes 3D detection benchmark.
RTS3D: Real-time Stereo 3D Detection from 4D Feature-Consistency Embedding Space for Autonomous Driving
Dec 30, 2020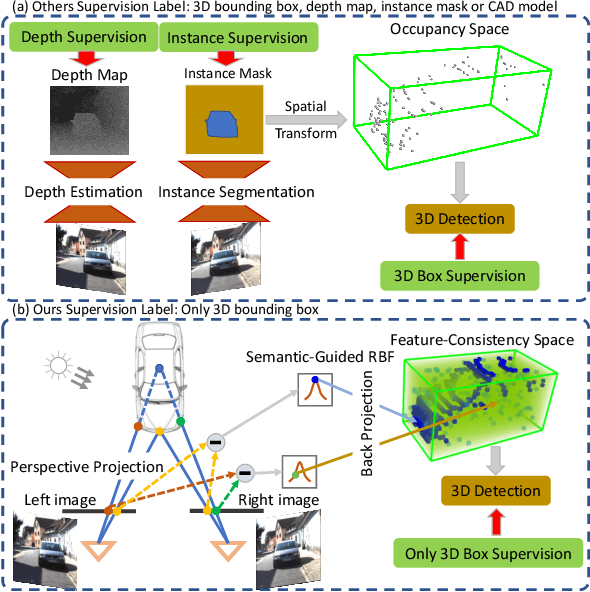

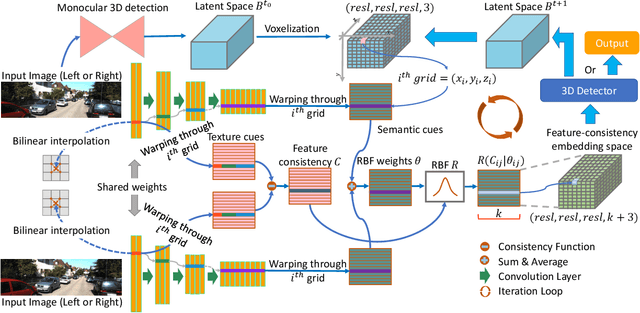
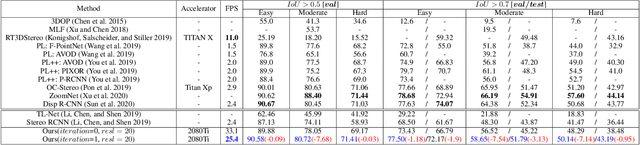
Although the recent image-based 3D object detection methods using Pseudo-LiDAR representation have shown great capabilities, a notable gap in efficiency and accuracy still exist compared with LiDAR-based methods. Besides, over-reliance on the stand-alone depth estimator, requiring a large number of pixel-wise annotations in the training stage and more computation in the inferencing stage, limits the scaling application in the real world. In this paper, we propose an efficient and accurate 3D object detection method from stereo images, named RTS3D. Different from the 3D occupancy space in the Pseudo-LiDAR similar methods, we design a novel 4D feature-consistent embedding (FCE) space as the intermediate representation of the 3D scene without depth supervision. The FCE space encodes the object's structural and semantic information by exploring the multi-scale feature consistency warped from stereo pair. Furthermore, a semantic-guided RBF (Radial Basis Function) and a structure-aware attention module are devised to reduce the influence of FCE space noise without instance mask supervision. Experiments on the KITTI benchmark show that RTS3D is the first true real-time system (FPS$>$24) for stereo image 3D detection meanwhile achieves $10\%$ improvement in average precision comparing with the previous state-of-the-art method. The code will be available at https://github.com/Banconxuan/RTS3D
Monocular 3D Detection with Geometric Constraints Embedding and Semi-supervised Training
Sep 02, 2020



In this work, we propose a novel single-shot and keypoints-based framework for monocular 3D objects detection using only RGB images, called KM3D-Net. We design a fully convolutional model to predict object keypoints, dimension, and orientation, and then combine these estimations with perspective geometry constraints to compute position attribute. Further, we reformulate the geometric constraints as a differentiable version and embed it into the network to reduce running time while maintaining the consistency of model outputs in an end-to-end fashion. Benefiting from this simple structure, we then propose an effective semi-supervised training strategy for the setting where labeled training data is scarce. In this strategy, we enforce a consensus prediction of two shared-weights KM3D-Net for the same unlabeled image under different input augmentation conditions and network regularization. In particular, we unify the coordinate-dependent augmentations as the affine transformation for the differential recovering position of objects and propose a keypoints-dropout module for the network regularization. Our model only requires RGB images without synthetic data, instance segmentation, CAD model, or depth generator. Nevertheless, extensive experiments on the popular KITTI 3D detection dataset indicate that the KM3D-Net surpasses all previous state-of-the-art methods in both efficiency and accuracy by a large margin. And also, to the best of our knowledge, this is the first time that semi-supervised learning is applied in monocular 3D objects detection. We even surpass most of the previous fully supervised methods with only 13\% labeled data on KITTI.
RTM3D: Real-time Monocular 3D Detection from Object Keypoints for Autonomous Driving
Jan 10, 2020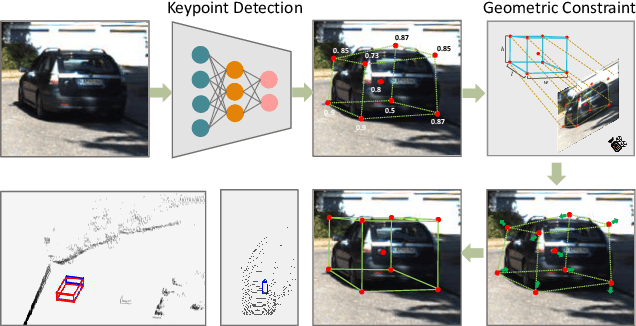
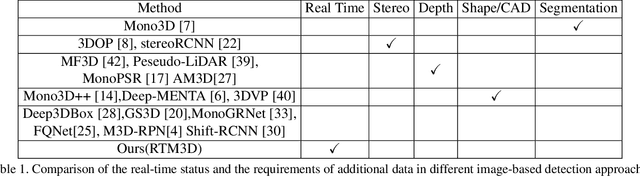
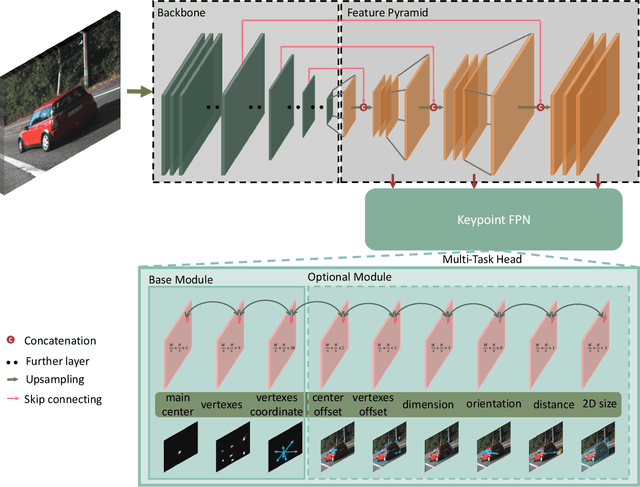
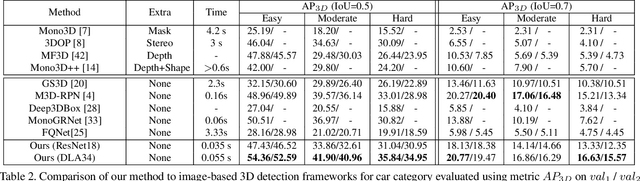
In this work, we propose an efficient and accurate monocular 3D detection framework in single shot. Most successful 3D detectors take the projection constraint from the 3D bounding box to the 2D box as an important component. Four edges of a 2D box provide only four constraints and the performance deteriorates dramatically with the small error of the 2D detector. Different from these approaches, our method predicts the nine perspective keypoints of a 3D bounding box in image space, and then utilize the geometric relationship of 3D and 2D perspectives to recover the dimension, location, and orientation in 3D space. In this method, the properties of the object can be predicted stably even when the estimation of keypoints is very noisy, which enables us to obtain fast detection speed with a small architecture. Training our method only uses the 3D properties of the object without the need for external networks or supervision data. Our method is the first real-time system for monocular image 3D detection while achieves state-of-the-art performance on the KITTI benchmark. Code will be released at https://github.com/Banconxuan/RTM3D.