 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerspective-Invariant 3D Object Detection
Jul 23, 2025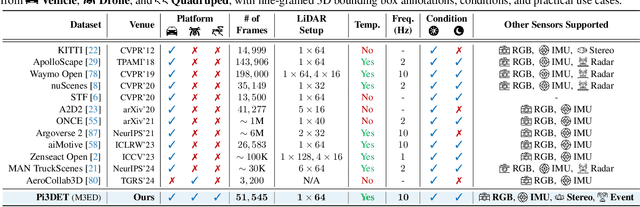
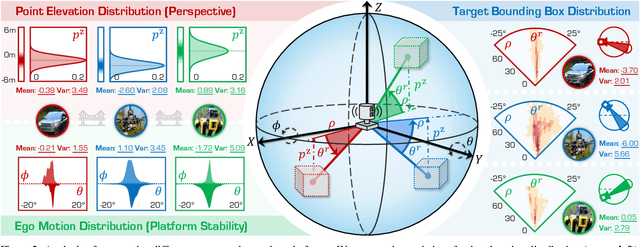
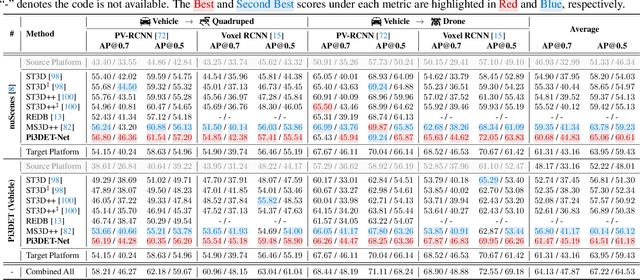
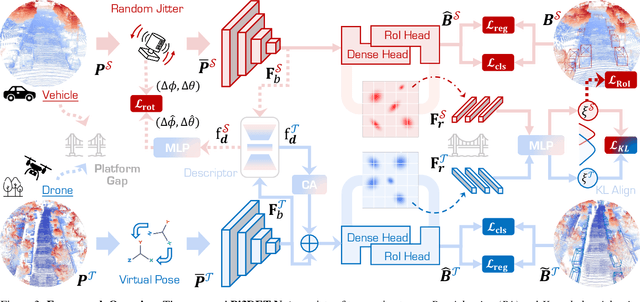
With the rise of robotics, LiDAR-based 3D object detection has garnered significant attention in both academia and industry. However, existing datasets and methods predominantly focus on vehicle-mounted platforms, leaving other autonomous platforms underexplored. To bridge this gap, we introduce Pi3DET, the first benchmark featuring LiDAR data and 3D bounding box annotations collected from multiple platforms: vehicle, quadruped, and drone, thereby facilitating research in 3D object detection for non-vehicle platforms as well as cross-platform 3D detection. Based on Pi3DET, we propose a novel cross-platform adaptation framework that transfers knowledge from the well-studied vehicle platform to other platforms. This framework achieves perspective-invariant 3D detection through robust alignment at both geometric and feature levels. Additionally, we establish a benchmark to evaluate the resilience and robustness of current 3D detectors in cross-platform scenarios, providing valuable insights for developing adaptive 3D perception systems. Extensive experiments validate the effectiveness of our approach on challenging cross-platform tasks, demonstrating substantial gains over existing adaptation methods. We hope this work paves the way for generalizable and unified 3D perception systems across diverse and complex environments. Our Pi3DET dataset, cross-platform benchmark suite, and annotation toolkit have been made publicly available.
TGP: Two-modal occupancy prediction with 3D Gaussian and sparse points for 3D Environment Awareness
Mar 13, 20253D semantic occupancy has rapidly become a research focus in the fields of robotics and autonomous driving environment perception due to its ability to provide more realistic geometric perception and its closer integration with downstream tasks. By performing occupancy prediction of the 3D space in the environment, the ability and robustness of scene understanding can be effectively improved. However, existing occupancy prediction tasks are primarily modeled using voxel or point cloud-based approaches: voxel-based network structures often suffer from the loss of spatial information due to the voxelization process, while point cloud-based methods, although better at retaining spatial location information, face limitations in representing volumetric structural details. To address this issue, we propose a dual-modal prediction method based on 3D Gaussian sets and sparse points, which balances both spatial location and volumetric structural information, achieving higher accuracy in semantic occupancy prediction. Specifically, our method adopts a Transformer-based architecture, taking 3D Gaussian sets, sparse points, and queries as inputs. Through the multi-layer structure of the Transformer, the enhanced queries and 3D Gaussian sets jointly contribute to the semantic occupancy prediction, and an adaptive fusion mechanism integrates the semantic outputs of both modalities to generate the final prediction results. Additionally, to further improve accuracy, we dynamically refine the point cloud at each layer, allowing for more precise location information during occupancy prediction. We conducted experiments on the Occ3DnuScenes dataset, and the experimental results demonstrate superior performance of the proposed method on IoU based metrics.
PDM-SSD: Single-Stage Three-Dimensional Object Detector With Point Dilation
Feb 10, 2025



Current Point-based detectors can only learn from the provided points, with limited receptive fields and insufficient global learning capabilities for such targets. In this paper, we present a novel Point Dilation Mechanism for single-stage 3D detection (PDM-SSD) that takes advantage of these two representations. Specifically, we first use a PointNet-style 3D backbone for efficient feature encoding. Then, a neck with Point Dilation Mechanism (PDM) is used to expand the feature space, which involves two key steps: point dilation and feature filling. The former expands points to a certain size grid centered around the sampled points in Euclidean space. The latter fills the unoccupied grid with feature for backpropagation using spherical harmonic coefficients and Gaussian density function in terms of direction and scale. Next, we associate multiple dilation centers and fuse coefficients to obtain sparse grid features through height compression. Finally, we design a hybrid detection head for joint learning, where on one hand, the scene heatmap is predicted to complement the voting point set for improved detection accuracy, and on the other hand, the target probability of detected boxes are calibrated through feature fusion. On the challenging Karlsruhe Institute of Technology and Toyota Technological Institute (KITTI) dataset, PDM-SSD achieves state-of-the-art results for multi-class detection among single-modal methods with an inference speed of 68 frames. We also demonstrate the advantages of PDM-SSD in detecting sparse and incomplete objects through numerous object-level instances. Additionally, PDM can serve as an auxiliary network to establish a connection between sampling points and object centers, thereby improving the accuracy of the model without sacrificing inference speed. Our code will be available at https://github.com/AlanLiangC/PDM-SSD.git.
SGCCNet: Single-Stage 3D Object Detector With Saliency-Guided Data Augmentation and Confidence Correction Mechanism
Jul 01, 2024



The single-stage point-based 3D object detectors have attracted widespread research interest due to their advantages of lightweight and fast inference speed. However, they still face challenges such as inadequate learning of low-quality objects (ILQ) and misalignment between localization accuracy and classification confidence (MLC). In this paper, we propose SGCCNet to alleviate these two issues. For ILQ, SGCCNet adopts a Saliency-Guided Data Augmentation (SGDA) strategy to enhance the robustness of the model on low-quality objects by reducing its reliance on salient features. Specifically, We construct a classification task and then approximate the saliency scores of points by moving points towards the point cloud centroid in a differentiable process. During the training process, SGCCNet will be forced to learn from low saliency features through dropping points. Meanwhile, to avoid internal covariate shift and contextual features forgetting caused by dropping points, we add a geometric normalization module and skip connection block in each stage. For MLC, we design a Confidence Correction Mechanism (CCM) specifically for point-based multi-class detectors. This mechanism corrects the confidence of the current proposal by utilizing the predictions of other key points within the local region in the post-processing stage. Extensive experiments on the KITTI dataset demonstrate the generality and effectiveness of our SGCCNet. On the KITTI \textit{test} set, SGCCNet achieves $80.82\%$ for the metric of $AP_{3D}$ on the \textit{Moderate} level, outperforming all other point-based detectors, surpassing IA-SSD and Fast Point R-CNN by $2.35\%$ and $3.42\%$, respectively. Additionally, SGCCNet demonstrates excellent portability for other point-based detectors
RTS3D: Real-time Stereo 3D Detection from 4D Feature-Consistency Embedding Space for Autonomous Driving
Dec 30, 2020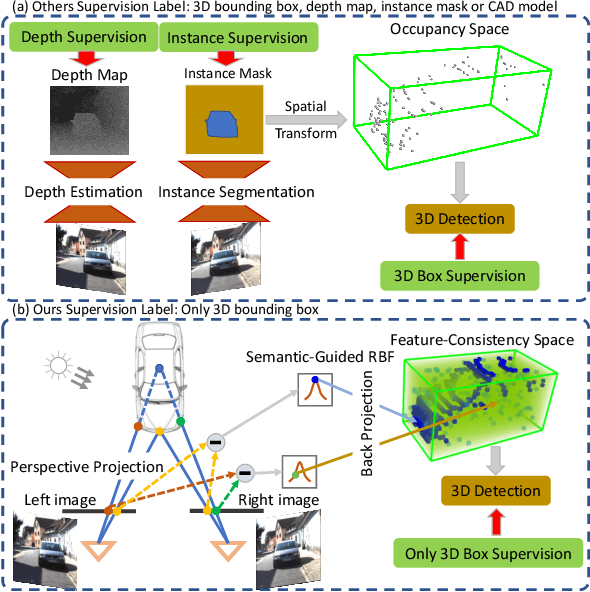

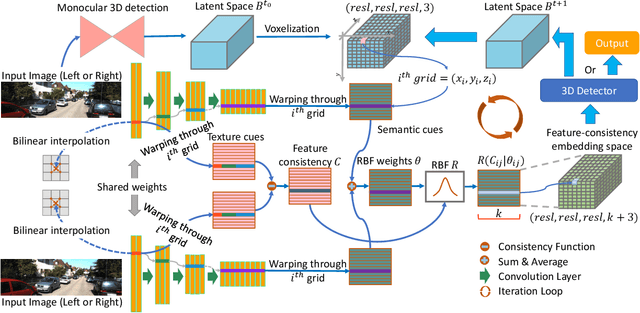
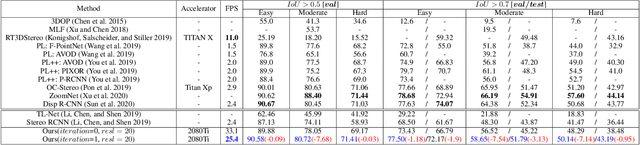
Although the recent image-based 3D object detection methods using Pseudo-LiDAR representation have shown great capabilities, a notable gap in efficiency and accuracy still exist compared with LiDAR-based methods. Besides, over-reliance on the stand-alone depth estimator, requiring a large number of pixel-wise annotations in the training stage and more computation in the inferencing stage, limits the scaling application in the real world. In this paper, we propose an efficient and accurate 3D object detection method from stereo images, named RTS3D. Different from the 3D occupancy space in the Pseudo-LiDAR similar methods, we design a novel 4D feature-consistent embedding (FCE) space as the intermediate representation of the 3D scene without depth supervision. The FCE space encodes the object's structural and semantic information by exploring the multi-scale feature consistency warped from stereo pair. Furthermore, a semantic-guided RBF (Radial Basis Function) and a structure-aware attention module are devised to reduce the influence of FCE space noise without instance mask supervision. Experiments on the KITTI benchmark show that RTS3D is the first true real-time system (FPS$>$24) for stereo image 3D detection meanwhile achieves $10\%$ improvement in average precision comparing with the previous state-of-the-art method. The code will be available at https://github.com/Banconxuan/RTS3D
RTM3D: Real-time Monocular 3D Detection from Object Keypoints for Autonomous Driving
Jan 10, 2020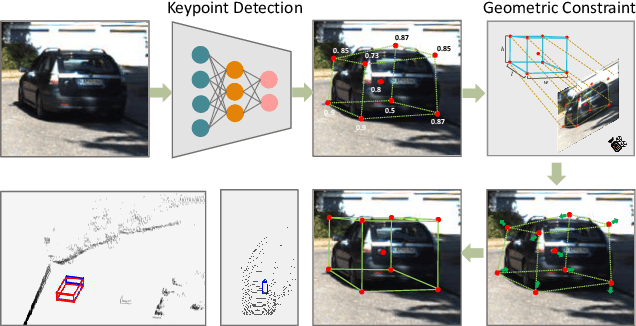
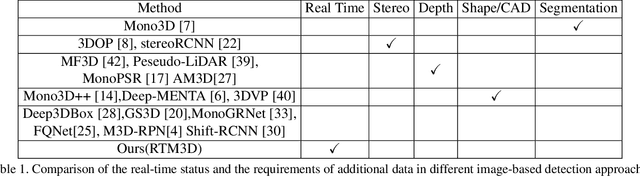
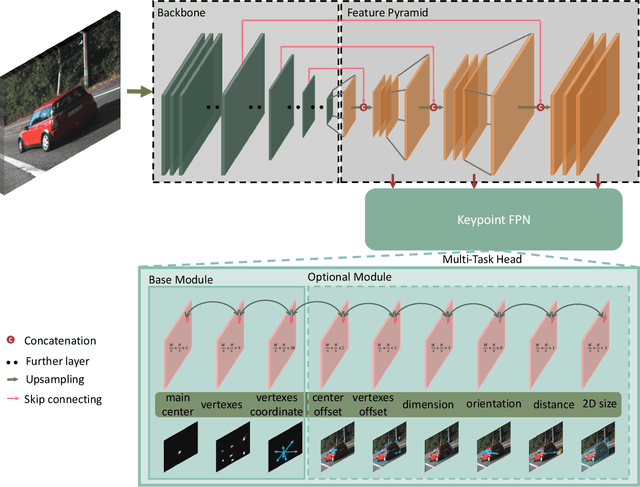
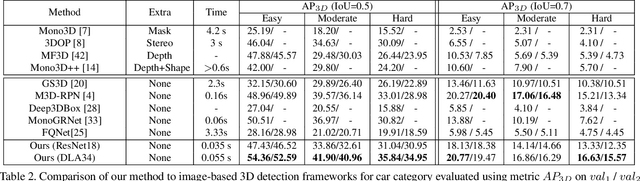
In this work, we propose an efficient and accurate monocular 3D detection framework in single shot. Most successful 3D detectors take the projection constraint from the 3D bounding box to the 2D box as an important component. Four edges of a 2D box provide only four constraints and the performance deteriorates dramatically with the small error of the 2D detector. Different from these approaches, our method predicts the nine perspective keypoints of a 3D bounding box in image space, and then utilize the geometric relationship of 3D and 2D perspectives to recover the dimension, location, and orientation in 3D space. In this method, the properties of the object can be predicted stably even when the estimation of keypoints is very noisy, which enables us to obtain fast detection speed with a small architecture. Training our method only uses the 3D properties of the object without the need for external networks or supervision data. Our method is the first real-time system for monocular image 3D detection while achieves state-of-the-art performance on the KITTI benchmark. Code will be released at https://github.com/Banconxuan/RTM3D.