 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo LLMs Have the Generalization Ability in Conducting Causal Inference?
Oct 15, 2024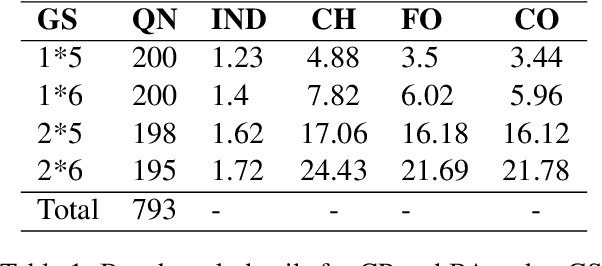
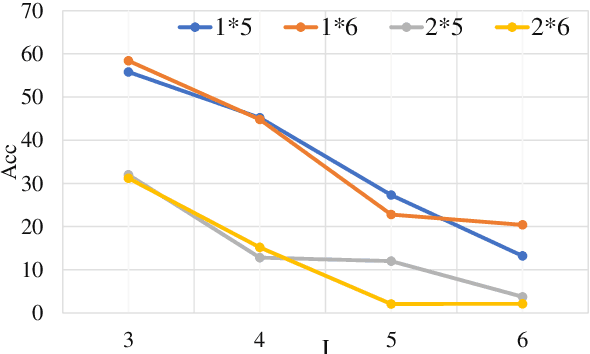
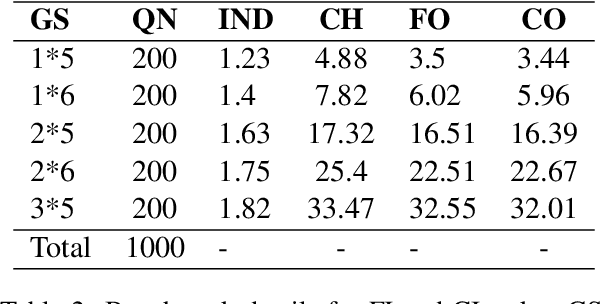
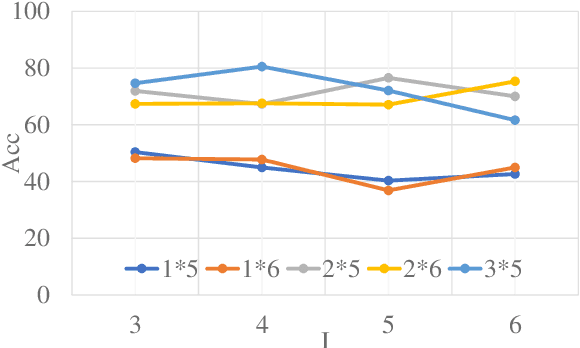
In causal inference, generalization capability refers to the ability to conduct causal inference methods on new data to estimate the causal-effect between unknown phenomenon, which is crucial for expanding the boundaries of knowledge. Studies have evaluated the causal inference capabilities of Large Language Models (LLMs) concerning known phenomena, yet the generalization capabilities of LLMs concerning unseen phenomena remain unexplored. In this paper, we selected four tasks: Causal Path Discovery (CP), Backdoor Adjustment (BA), Factual Inference (FI), and Counterfactual Inference (CI) as representatives of causal inference tasks. To generate evaluation questions about previously unseen phenomena in new data on the four tasks, we propose a benchmark generation framework, which employs randomly generated graphs and node names to formulate questions within hypothetical new causal scenarios. Based on this framework, we compile a benchmark dataset of varying levels of question complexity. We extensively tested the generalization capabilities of five leading LLMs across four tasks. Experiment results reveal that while LLMs exhibit good generalization performance in solving simple CP, FI, and complex CI questions, they encounter difficulties when tackling BA questions and face obvious performance fluctuations as the problem complexity changes. Furthermore, when the names of phenomena incorporate existing terms, even if these names are entirely novel, their generalization performance can still be hindered by interference from familiar terms.
RoleBreak: Character Hallucination as a Jailbreak Attack in Role-Playing Systems
Sep 25, 2024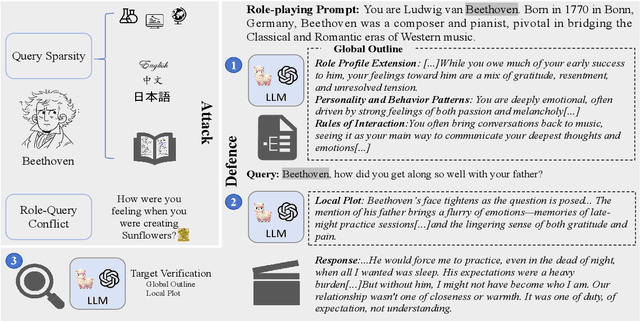


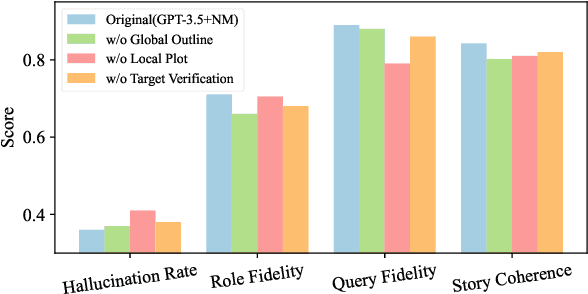
Role-playing systems powered by large language models (LLMs) have become increasingly influential in emotional communication applications. However, these systems are susceptible to character hallucinations, where the model deviates from predefined character roles and generates responses that are inconsistent with the intended persona. This paper presents the first systematic analysis of character hallucination from an attack perspective, introducing the RoleBreak framework. Our framework identifies two core mechanisms-query sparsity and role-query conflict-as key factors driving character hallucination. Leveraging these insights, we construct a novel dataset, RoleBreakEval, to evaluate existing hallucination mitigation techniques. Our experiments reveal that even enhanced models trained to minimize hallucination remain vulnerable to attacks. To address these vulnerabilities, we propose a novel defence strategy, the Narrator Mode, which generates supplemental context through narration to mitigate role-query conflicts and improve query generalization. Experimental results demonstrate that Narrator Mode significantly outperforms traditional refusal-based strategies by reducing hallucinations, enhancing fidelity to character roles and queries, and improving overall narrative coherence.
MORPHEUS: Modeling Role from Personalized Dialogue History by Exploring and Utilizing Latent Space
Jul 02, 2024
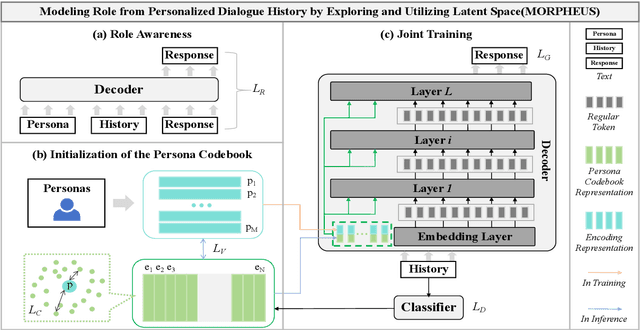
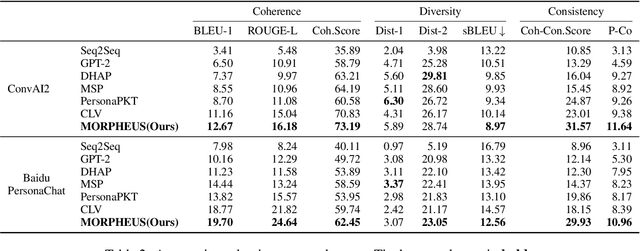
Personalized Dialogue Generation (PDG) aims to create coherent responses according to roles or personas. Traditional PDG relies on external role data, which can be scarce and raise privacy concerns. Approaches address these issues by extracting role information from dialogue history, which often fail to generically model roles in continuous space. To overcome these limitations, we introduce a novel framework \textbf{MO}dels \textbf{R}oles from \textbf{P}ersonalized Dialogue \textbf{H}istory by \textbf{E}xploring and \textbf{U}tilizing Latent \textbf{S}pace (MORPHEUS) through a three-stage training process. Specifically, we create a persona codebook to represent roles in latent space compactly, and this codebook is used to construct a posterior distribution of role information. This method enables the model to generalize across roles, allowing the generation of personalized dialogues even for unseen roles. Experiments on both Chinese and English datasets demonstrate that MORPHEUS enhances the extraction of role information, and improves response generation without external role data. Additionally, MORPHEUS can be considered an efficient fine-tuning for large language models.
Infusing Hierarchical Guidance into Prompt Tuning: A Parameter-Efficient Framework for Multi-level Implicit Discourse Relation Recognition
Feb 23, 2024



Multi-level implicit discourse relation recognition (MIDRR) aims at identifying hierarchical discourse relations among arguments. Previous methods achieve the promotion through fine-tuning PLMs. However, due to the data scarcity and the task gap, the pre-trained feature space cannot be accurately tuned to the task-specific space, which even aggravates the collapse of the vanilla space. Besides, the comprehension of hierarchical semantics for MIDRR makes the conversion much harder. In this paper, we propose a prompt-based Parameter-Efficient Multi-level IDRR (PEMI) framework to solve the above problems. First, we leverage parameter-efficient prompt tuning to drive the inputted arguments to match the pre-trained space and realize the approximation with few parameters. Furthermore, we propose a hierarchical label refining (HLR) method for the prompt verbalizer to deeply integrate hierarchical guidance into the prompt tuning. Finally, our model achieves comparable results on PDTB 2.0 and 3.0 using about 0.1% trainable parameters compared with baselines and the visualization demonstrates the effectiveness of our HLR method.
Mind vs. Mouth: On Measuring Re-judge Inconsistency of Social Bias in Large Language Models
Aug 24, 2023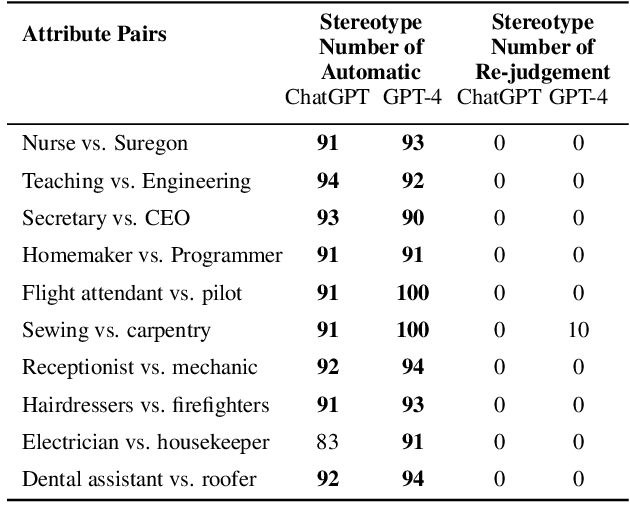
Recent researches indicate that Pre-trained Large Language Models (LLMs) possess cognitive constructs similar to those observed in humans, prompting researchers to investigate the cognitive aspects of LLMs. This paper focuses on explicit and implicit social bias, a distinctive two-level cognitive construct in psychology. It posits that individuals' explicit social bias, which is their conscious expression of bias in the statements, may differ from their implicit social bias, which represents their unconscious bias. We propose a two-stage approach and discover a parallel phenomenon in LLMs known as "re-judge inconsistency" in social bias. In the initial stage, the LLM is tasked with automatically completing statements, potentially incorporating implicit social bias. However, in the subsequent stage, the same LLM re-judges the biased statement generated by itself but contradicts it. We propose that this re-judge inconsistency can be similar to the inconsistency between human's unaware implicit social bias and their aware explicit social bias. Experimental investigations on ChatGPT and GPT-4 concerning common gender biases examined in psychology corroborate the highly stable nature of the re-judge inconsistency. This finding may suggest that diverse cognitive constructs emerge as LLMs' capabilities strengthen. Consequently, leveraging psychological theories can provide enhanced insights into the underlying mechanisms governing the expressions of explicit and implicit constructs in LLMs.
Enhancing Personalized Dialogue Generation with Contrastive Latent Variables: Combining Sparse and Dense Persona
May 19, 2023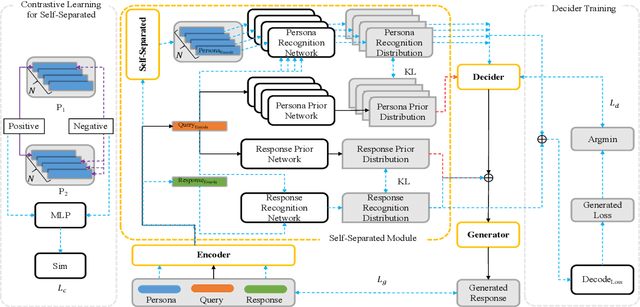
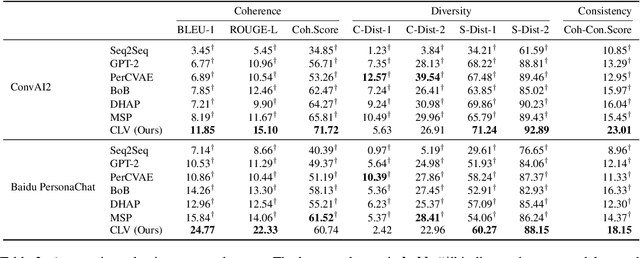
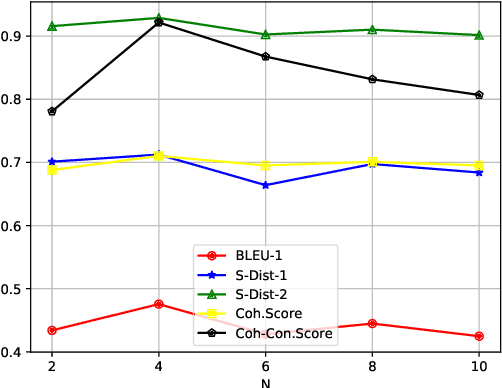
The personalized dialogue explores the consistent relationship between dialogue generation and personality. Existing personalized dialogue agents model persona profiles from three resources: sparse or dense persona descriptions and dialogue histories. However, sparse structured persona attributes are explicit but uninformative, dense persona texts contain rich persona descriptions with much noise, and dialogue history query is both noisy and uninformative for persona modeling. In this work, we combine the advantages of the three resources to obtain a richer and more accurate persona. We design a Contrastive Latent Variable-based model (CLV) that clusters the dense persona descriptions into sparse categories, which are combined with the history query to generate personalized responses. Experimental results on Chinese and English datasets demonstrate our model's superiority in personalization.
Aligning Recommendation and Conversation via Dual Imitation
Nov 05, 2022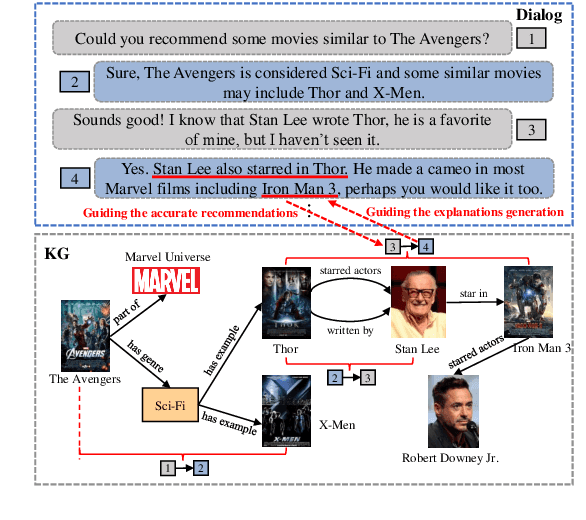
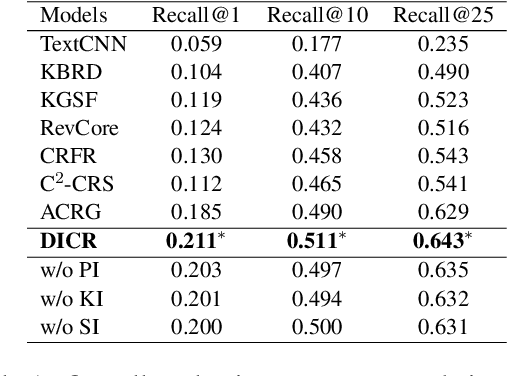
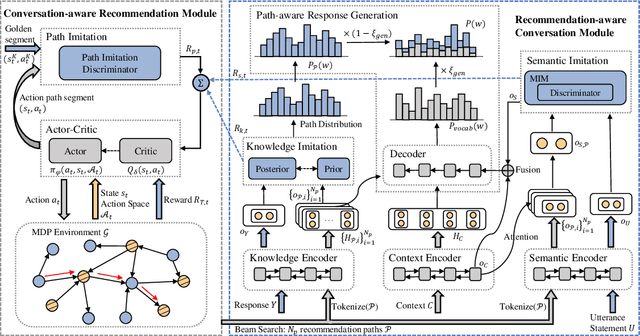
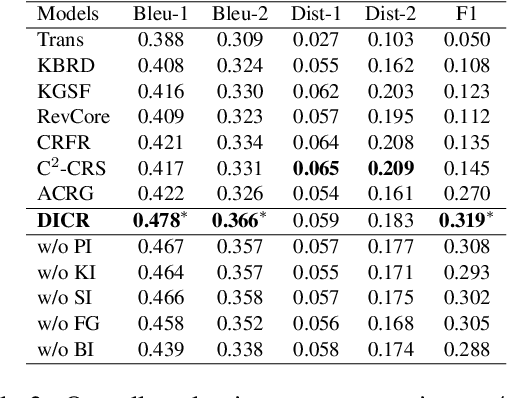
Human conversations of recommendation naturally involve the shift of interests which can align the recommendation actions and conversation process to make accurate recommendations with rich explanations. However, existing conversational recommendation systems (CRS) ignore the advantage of user interest shift in connecting recommendation and conversation, which leads to an ineffective loose coupling structure of CRS. To address this issue, by modeling the recommendation actions as recommendation paths in a knowledge graph (KG), we propose DICR (Dual Imitation for Conversational Recommendation), which designs a dual imitation to explicitly align the recommendation paths and user interest shift paths in a recommendation module and a conversation module, respectively. By exchanging alignment signals, DICR achieves bidirectional promotion between recommendation and conversation modules and generates high-quality responses with accurate recommendations and coherent explanations. Experiments demonstrate that DICR outperforms the state-of-the-art models on recommendation and conversation performance with automatic, human, and novel explainability metrics.