 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo LLMs Have the Generalization Ability in Conducting Causal Inference?
Oct 15, 2024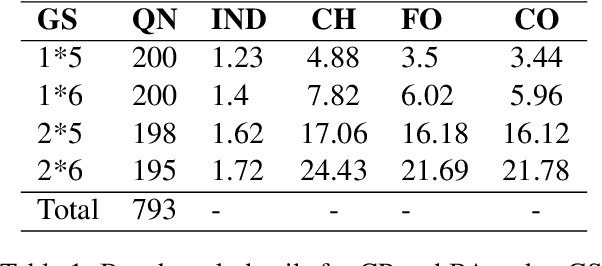
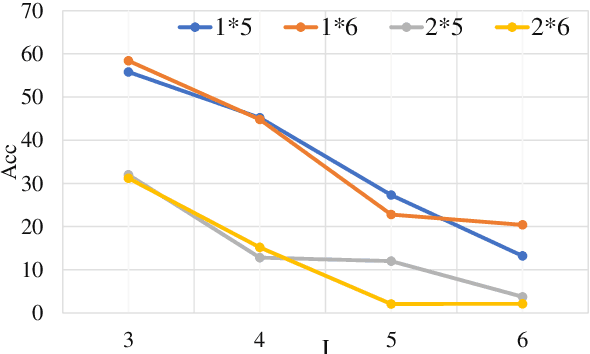
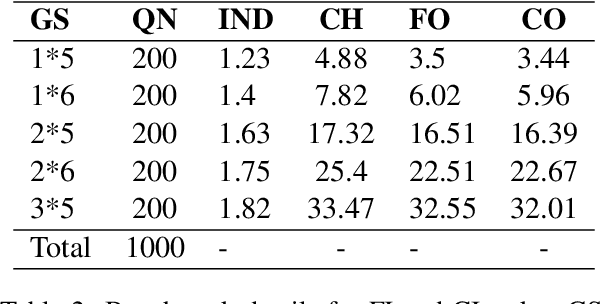
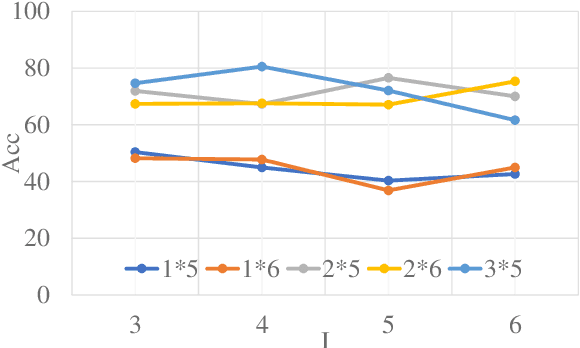
In causal inference, generalization capability refers to the ability to conduct causal inference methods on new data to estimate the causal-effect between unknown phenomenon, which is crucial for expanding the boundaries of knowledge. Studies have evaluated the causal inference capabilities of Large Language Models (LLMs) concerning known phenomena, yet the generalization capabilities of LLMs concerning unseen phenomena remain unexplored. In this paper, we selected four tasks: Causal Path Discovery (CP), Backdoor Adjustment (BA), Factual Inference (FI), and Counterfactual Inference (CI) as representatives of causal inference tasks. To generate evaluation questions about previously unseen phenomena in new data on the four tasks, we propose a benchmark generation framework, which employs randomly generated graphs and node names to formulate questions within hypothetical new causal scenarios. Based on this framework, we compile a benchmark dataset of varying levels of question complexity. We extensively tested the generalization capabilities of five leading LLMs across four tasks. Experiment results reveal that while LLMs exhibit good generalization performance in solving simple CP, FI, and complex CI questions, they encounter difficulties when tackling BA questions and face obvious performance fluctuations as the problem complexity changes. Furthermore, when the names of phenomena incorporate existing terms, even if these names are entirely novel, their generalization performance can still be hindered by interference from familiar terms.
RoleBreak: Character Hallucination as a Jailbreak Attack in Role-Playing Systems
Sep 25, 2024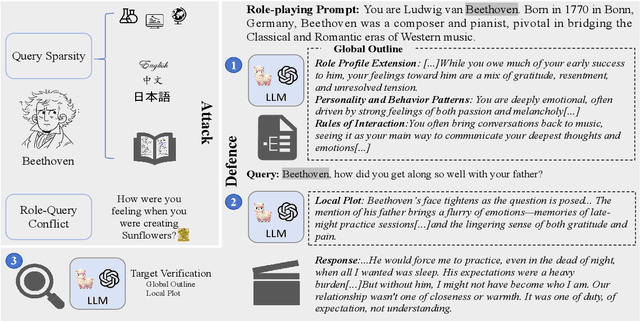


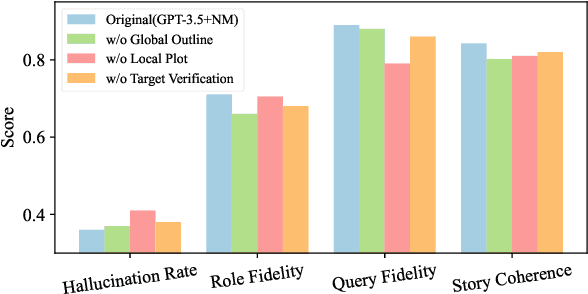
Role-playing systems powered by large language models (LLMs) have become increasingly influential in emotional communication applications. However, these systems are susceptible to character hallucinations, where the model deviates from predefined character roles and generates responses that are inconsistent with the intended persona. This paper presents the first systematic analysis of character hallucination from an attack perspective, introducing the RoleBreak framework. Our framework identifies two core mechanisms-query sparsity and role-query conflict-as key factors driving character hallucination. Leveraging these insights, we construct a novel dataset, RoleBreakEval, to evaluate existing hallucination mitigation techniques. Our experiments reveal that even enhanced models trained to minimize hallucination remain vulnerable to attacks. To address these vulnerabilities, we propose a novel defence strategy, the Narrator Mode, which generates supplemental context through narration to mitigate role-query conflicts and improve query generalization. Experimental results demonstrate that Narrator Mode significantly outperforms traditional refusal-based strategies by reducing hallucinations, enhancing fidelity to character roles and queries, and improving overall narrative coherence.
Chain of Stance: Stance Detection with Large Language Models
Aug 03, 2024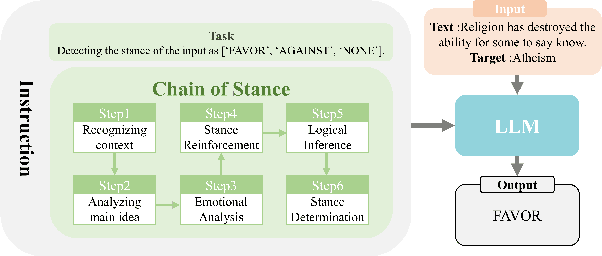
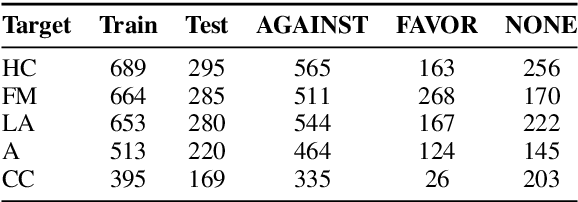

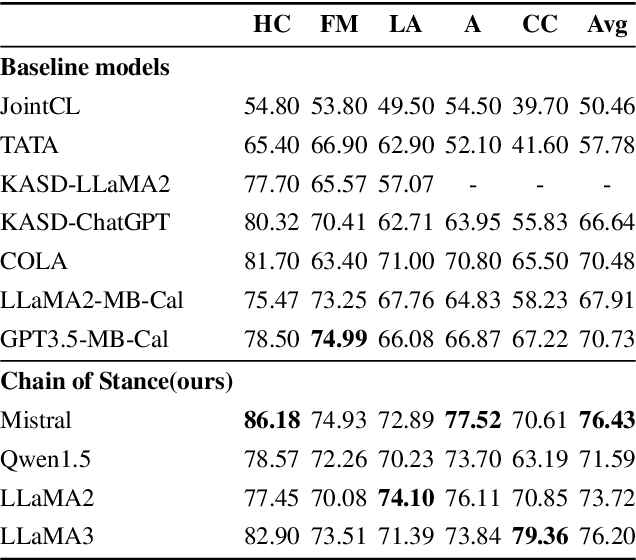
Stance detection is an active task in natural language processing (NLP) that aims to identify the author's stance towards a particular target within a text. Given the remarkable language understanding capabilities and encyclopedic prior knowledge of large language models (LLMs), how to explore the potential of LLMs in stance detection has received significant attention. Unlike existing LLM-based approaches that focus solely on fine-tuning with large-scale datasets, we propose a new prompting method, called \textit{Chain of Stance} (CoS). In particular, it positions LLMs as expert stance detectors by decomposing the stance detection process into a series of intermediate, stance-related assertions that culminate in the final judgment. This approach leads to significant improvements in classification performance. We conducted extensive experiments using four SOTA LLMs on the SemEval 2016 dataset, covering the zero-shot and few-shot learning setups. The results indicate that the proposed method achieves state-of-the-art results with an F1 score of 79.84 in the few-shot setting.
MORPHEUS: Modeling Role from Personalized Dialogue History by Exploring and Utilizing Latent Space
Jul 02, 2024
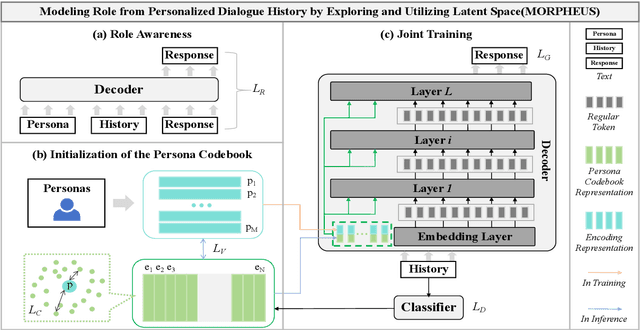
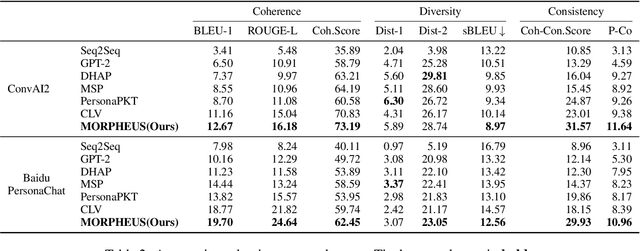
Personalized Dialogue Generation (PDG) aims to create coherent responses according to roles or personas. Traditional PDG relies on external role data, which can be scarce and raise privacy concerns. Approaches address these issues by extracting role information from dialogue history, which often fail to generically model roles in continuous space. To overcome these limitations, we introduce a novel framework \textbf{MO}dels \textbf{R}oles from \textbf{P}ersonalized Dialogue \textbf{H}istory by \textbf{E}xploring and \textbf{U}tilizing Latent \textbf{S}pace (MORPHEUS) through a three-stage training process. Specifically, we create a persona codebook to represent roles in latent space compactly, and this codebook is used to construct a posterior distribution of role information. This method enables the model to generalize across roles, allowing the generation of personalized dialogues even for unseen roles. Experiments on both Chinese and English datasets demonstrate that MORPHEUS enhances the extraction of role information, and improves response generation without external role data. Additionally, MORPHEUS can be considered an efficient fine-tuning for large language models.
Enhancing Retrieval-Augmented LMs with a Two-stage Consistency Learning Compressor
Jun 04, 2024



Despite the prevalence of retrieval-augmented language models (RALMs), the seamless integration of these models with retrieval mechanisms to enhance performance in document-based tasks remains challenging. While some post-retrieval processing Retrieval-Augmented Generation (RAG) methods have achieved success, most still lack the ability to distinguish pertinent from extraneous information, leading to potential inconsistencies and reduced precision in the generated output, which subsequently affects the truthfulness of the language model's responses. To address these limitations, this work proposes a novel two-stage consistency learning approach for retrieved information compression in retrieval-augmented language models to enhance performance. By incorporating consistency learning, the aim is to generate summaries that maintain coherence and alignment with the intended semantic representations of a teacher model while improving faithfulness to the original retrieved documents. The proposed method is empirically validated across multiple datasets, demonstrating notable enhancements in precision and efficiency for question-answering tasks. It outperforms existing baselines and showcases the synergistic effects of combining contrastive and consistency learning paradigms within the retrieval-augmented generation framework.
Mind vs. Mouth: On Measuring Re-judge Inconsistency of Social Bias in Large Language Models
Aug 24, 2023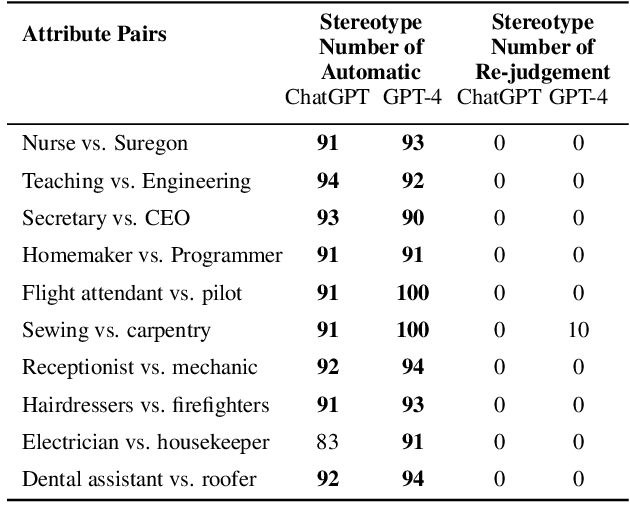
Recent researches indicate that Pre-trained Large Language Models (LLMs) possess cognitive constructs similar to those observed in humans, prompting researchers to investigate the cognitive aspects of LLMs. This paper focuses on explicit and implicit social bias, a distinctive two-level cognitive construct in psychology. It posits that individuals' explicit social bias, which is their conscious expression of bias in the statements, may differ from their implicit social bias, which represents their unconscious bias. We propose a two-stage approach and discover a parallel phenomenon in LLMs known as "re-judge inconsistency" in social bias. In the initial stage, the LLM is tasked with automatically completing statements, potentially incorporating implicit social bias. However, in the subsequent stage, the same LLM re-judges the biased statement generated by itself but contradicts it. We propose that this re-judge inconsistency can be similar to the inconsistency between human's unaware implicit social bias and their aware explicit social bias. Experimental investigations on ChatGPT and GPT-4 concerning common gender biases examined in psychology corroborate the highly stable nature of the re-judge inconsistency. This finding may suggest that diverse cognitive constructs emerge as LLMs' capabilities strengthen. Consequently, leveraging psychological theories can provide enhanced insights into the underlying mechanisms governing the expressions of explicit and implicit constructs in LLMs.
Enhancing Personalized Dialogue Generation with Contrastive Latent Variables: Combining Sparse and Dense Persona
May 19, 2023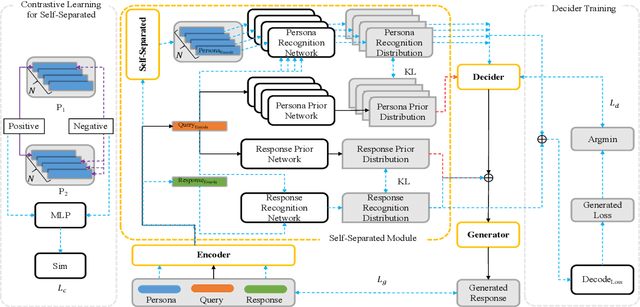
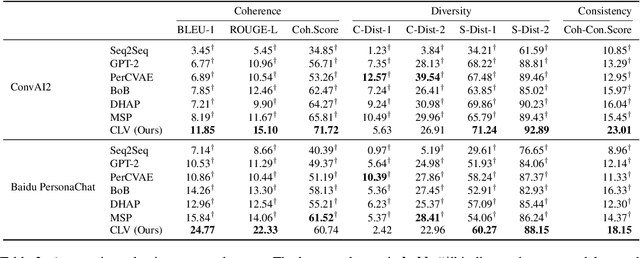
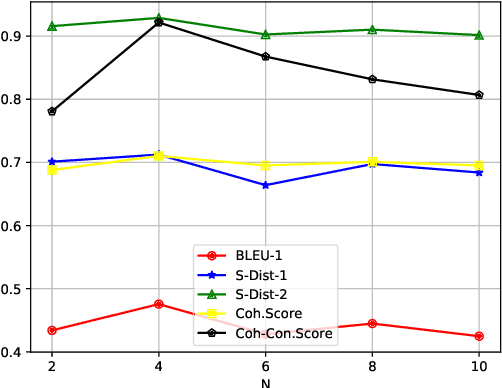
The personalized dialogue explores the consistent relationship between dialogue generation and personality. Existing personalized dialogue agents model persona profiles from three resources: sparse or dense persona descriptions and dialogue histories. However, sparse structured persona attributes are explicit but uninformative, dense persona texts contain rich persona descriptions with much noise, and dialogue history query is both noisy and uninformative for persona modeling. In this work, we combine the advantages of the three resources to obtain a richer and more accurate persona. We design a Contrastive Latent Variable-based model (CLV) that clusters the dense persona descriptions into sparse categories, which are combined with the history query to generate personalized responses. Experimental results on Chinese and English datasets demonstrate our model's superiority in personalization.
HGWaveNet: A Hyperbolic Graph Neural Network for Temporal Link Prediction
May 03, 2023Temporal link prediction, aiming to predict future edges between paired nodes in a dynamic graph, is of vital importance in diverse applications. However, existing methods are mainly built upon uniform Euclidean space, which has been found to be conflict with the power-law distributions of real-world graphs and unable to represent the hierarchical connections between nodes effectively. With respect to the special data characteristic, hyperbolic geometry offers an ideal alternative due to its exponential expansion property. In this paper, we propose HGWaveNet, a novel hyperbolic graph neural network that fully exploits the fitness between hyperbolic spaces and data distributions for temporal link prediction. Specifically, we design two key modules to learn the spatial topological structures and temporal evolutionary information separately. On the one hand, a hyperbolic diffusion graph convolution (HDGC) module effectively aggregates information from a wider range of neighbors. On the other hand, the internal order of causal correlation between historical states is captured by hyperbolic dilated causal convolution (HDCC) modules. The whole model is built upon the hyperbolic spaces to preserve the hierarchical structural information in the entire data flow. To prove the superiority of HGWaveNet, extensive experiments are conducted on six real-world graph datasets and the results show a relative improvement by up to 6.67% on AUC for temporal link prediction over SOTA methods.
* Accepted by Web Conference (WWW) 2023
Empathetic Response Generation via Emotion Cause Transition Graph
Feb 23, 2023



Empathetic dialogue is a human-like behavior that requires the perception of both affective factors (e.g., emotion status) and cognitive factors (e.g., cause of the emotion). Besides concerning emotion status in early work, the latest approaches study emotion causes in empathetic dialogue. These approaches focus on understanding and duplicating emotion causes in the context to show empathy for the speaker. However, instead of only repeating the contextual causes, the real empathic response often demonstrate a logical and emotion-centered transition from the causes in the context to those in the responses. In this work, we propose an emotion cause transition graph to explicitly model the natural transition of emotion causes between two adjacent turns in empathetic dialogue. With this graph, the concept words of the emotion causes in the next turn can be predicted and used by a specifically designed concept-aware decoder to generate the empathic response. Automatic and human experimental results on the benchmark dataset demonstrate that our method produces more empathetic, coherent, informative, and specific responses than existing models.
Think Twice: A Human-like Two-stage Conversational Agent for Emotional Response Generation
Jan 12, 2023Towards human-like dialogue systems, current emotional dialogue approaches jointly model emotion and semantics with a unified neural network. This strategy tends to generate safe responses due to the mutual restriction between emotion and semantics, and requires rare emotion-annotated large-scale dialogue corpus. Inspired by the "think twice" behavior in human dialogue, we propose a two-stage conversational agent for the generation of emotional dialogue. Firstly, a dialogue model trained without the emotion-annotated dialogue corpus generates a prototype response that meets the contextual semantics. Secondly, the first-stage prototype is modified by a controllable emotion refiner with the empathy hypothesis. Experimental results on the DailyDialog and EmpatheticDialogues datasets demonstrate that the proposed conversational outperforms the comparison models in emotion generation and maintains the semantic performance in automatic and human evaluations.