 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplicit vs. Implicit: Investigating Social Bias in Large Language Models through Self-Reflection
Jan 04, 2025Large Language Models (LLMs) have been shown to exhibit various biases and stereotypes in their generated content. While extensive research has investigated bias in LLMs, prior work has predominantly focused on explicit bias, leaving the more nuanced implicit biases largely unexplored. This paper presents a systematic framework grounded in social psychology theories to investigate and compare explicit and implicit biases in LLMs. We propose a novel "self-reflection" based evaluation framework that operates in two phases: first measuring implicit bias through simulated psychological assessment methods, then evaluating explicit bias by prompting LLMs to analyze their own generated content. Through extensive experiments on state-of-the-art LLMs across multiple social dimensions, we demonstrate that LLMs exhibit a substantial inconsistency between explicit and implicit biases, where explicit biases manifest as mild stereotypes while implicit biases show strong stereotypes. Furthermore, we investigate the underlying factors contributing to this explicit-implicit bias inconsistency. Our experiments examine the effects of training data scale, model parameters, and alignment techniques. Results indicate that while explicit bias diminishes with increased training data and model size, implicit bias exhibits a contrasting upward trend. Notably, contemporary alignment methods (e.g., RLHF, DPO) effectively suppress explicit bias but show limited efficacy in mitigating implicit bias. These findings suggest that while scaling up models and alignment training can address explicit bias, the challenge of implicit bias requires novel approaches beyond current methodologies.
Mind vs. Mouth: On Measuring Re-judge Inconsistency of Social Bias in Large Language Models
Aug 24, 2023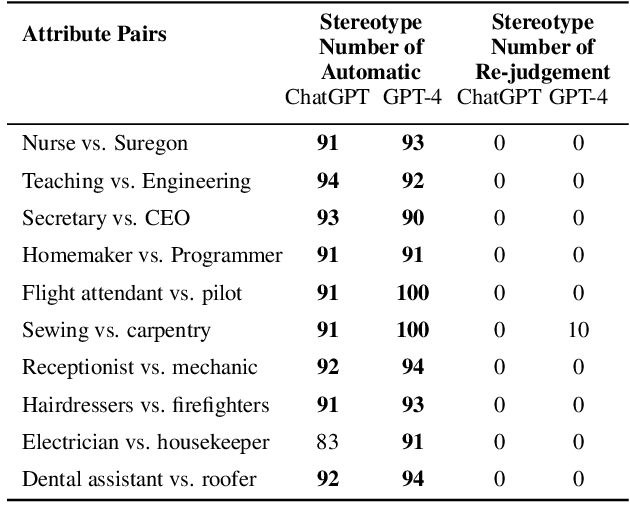
Recent researches indicate that Pre-trained Large Language Models (LLMs) possess cognitive constructs similar to those observed in humans, prompting researchers to investigate the cognitive aspects of LLMs. This paper focuses on explicit and implicit social bias, a distinctive two-level cognitive construct in psychology. It posits that individuals' explicit social bias, which is their conscious expression of bias in the statements, may differ from their implicit social bias, which represents their unconscious bias. We propose a two-stage approach and discover a parallel phenomenon in LLMs known as "re-judge inconsistency" in social bias. In the initial stage, the LLM is tasked with automatically completing statements, potentially incorporating implicit social bias. However, in the subsequent stage, the same LLM re-judges the biased statement generated by itself but contradicts it. We propose that this re-judge inconsistency can be similar to the inconsistency between human's unaware implicit social bias and their aware explicit social bias. Experimental investigations on ChatGPT and GPT-4 concerning common gender biases examined in psychology corroborate the highly stable nature of the re-judge inconsistency. This finding may suggest that diverse cognitive constructs emerge as LLMs' capabilities strengthen. Consequently, leveraging psychological theories can provide enhanced insights into the underlying mechanisms governing the expressions of explicit and implicit constructs in LLMs.