 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Very Big Video Reasoning Suite
Feb 24, 2026Rapid progress in video models has largely focused on visual quality, leaving their reasoning capabilities underexplored. Video reasoning grounds intelligence in spatiotemporally consistent visual environments that go beyond what text can naturally capture, enabling intuitive reasoning over spatiotemporal structure such as continuity, interaction, and causality. However, systematically studying video reasoning and its scaling behavior is hindered by the lack of large-scale training data. To address this gap, we introduce the Very Big Video Reasoning (VBVR) Dataset, an unprecedentedly large-scale resource spanning 200 curated reasoning tasks following a principled taxonomy and over one million video clips, approximately three orders of magnitude larger than existing datasets. We further present VBVR-Bench, a verifiable evaluation framework that moves beyond model-based judging by incorporating rule-based, human-aligned scorers, enabling reproducible and interpretable diagnosis of video reasoning capabilities. Leveraging the VBVR suite, we conduct one of the first large-scale scaling studies of video reasoning and observe early signs of emergent generalization to unseen reasoning tasks. Together, VBVR lays a foundation for the next stage of research in generalizable video reasoning. The data, benchmark toolkit, and models are publicly available at https://video-reason.com/ .
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Feb 13, 2026Agent Skills are structured packages of procedural knowledge that augment LLM agents at inference time. Despite rapid adoption, there is no standard way to measure whether they actually help. We present SkillsBench, a benchmark of 86 tasks across 11 domains paired with curated Skills and deterministic verifiers. Each task is evaluated under three conditions: no Skills, curated Skills, and self-generated Skills. We test 7 agent-model configurations over 7,308 trajectories. Curated Skills raise average pass rate by 16.2 percentage points(pp), but effects vary widely by domain (+4.5pp for Software Engineering to +51.9pp for Healthcare) and 16 of 84 tasks show negative deltas. Self-generated Skills provide no benefit on average, showing that models cannot reliably author the procedural knowledge they benefit from consuming. Focused Skills with 2--3 modules outperform comprehensive documentation, and smaller models with Skills can match larger models without them.
Continual learning via probabilistic exchangeable sequence modelling
Mar 26, 2025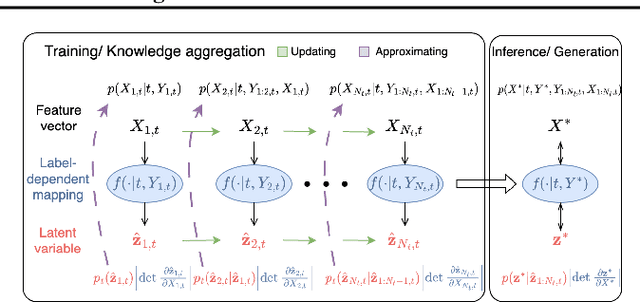
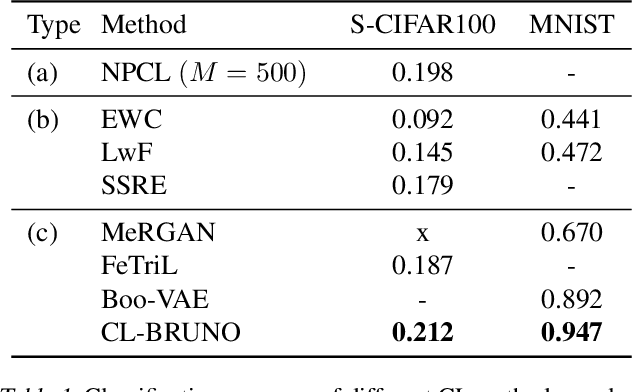
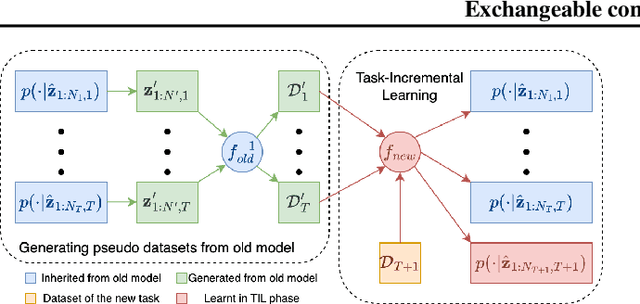
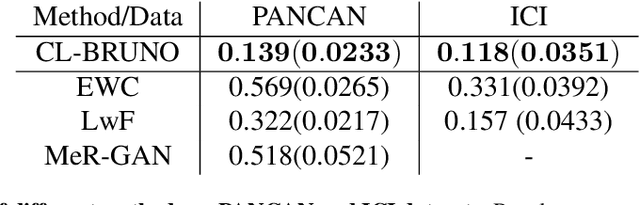
Continual learning (CL) refers to the ability to continuously learn and accumulate new knowledge while retaining useful information from past experiences. Although numerous CL methods have been proposed in recent years, it is not straightforward to deploy them directly to real-world decision-making problems due to their computational cost and lack of uncertainty quantification. To address these issues, we propose CL-BRUNO, a probabilistic, Neural Process-based CL model that performs scalable and tractable Bayesian update and prediction. Our proposed approach uses deep-generative models to create a unified probabilistic framework capable of handling different types of CL problems such as task- and class-incremental learning, allowing users to integrate information across different CL scenarios using a single model. Our approach is able to prevent catastrophic forgetting through distributional and functional regularisation without the need of retaining any previously seen samples, making it appealing to applications where data privacy or storage capacity is of concern. Experiments show that CL-BRUNO outperforms existing methods on both natural image and biomedical data sets, confirming its effectiveness in real-world applications.
GPTON: Generative Pre-trained Transformers enhanced with Ontology Narration for accurate annotation of biological data
Oct 12, 2024

By leveraging GPT-4 for ontology narration, we developed GPTON to infuse structured knowledge into LLMs through verbalized ontology terms, achieving accurate text and ontology annotations for over 68% of gene sets in the top five predictions. Manual evaluations confirm GPTON's robustness, highlighting its potential to harness LLMs and structured knowledge to significantly advance biomedical research beyond gene set annotation.
Chain of Stance: Stance Detection with Large Language Models
Aug 03, 2024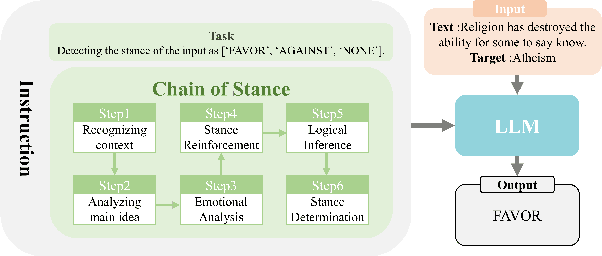
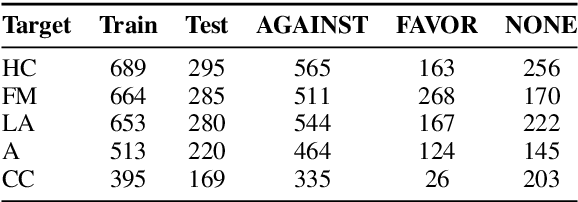

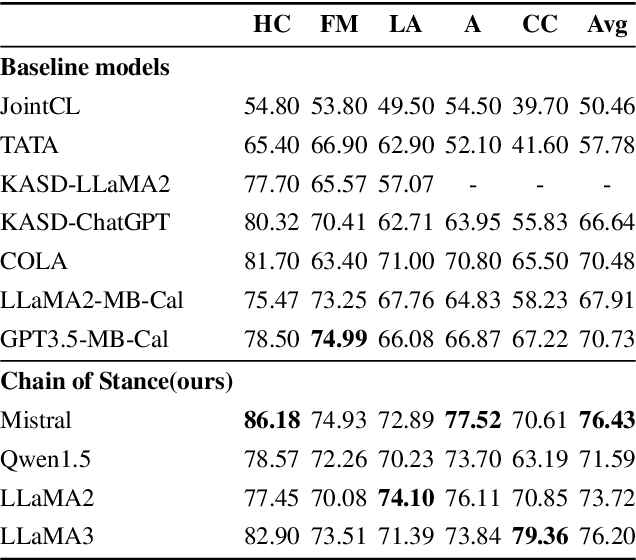
Stance detection is an active task in natural language processing (NLP) that aims to identify the author's stance towards a particular target within a text. Given the remarkable language understanding capabilities and encyclopedic prior knowledge of large language models (LLMs), how to explore the potential of LLMs in stance detection has received significant attention. Unlike existing LLM-based approaches that focus solely on fine-tuning with large-scale datasets, we propose a new prompting method, called \textit{Chain of Stance} (CoS). In particular, it positions LLMs as expert stance detectors by decomposing the stance detection process into a series of intermediate, stance-related assertions that culminate in the final judgment. This approach leads to significant improvements in classification performance. We conducted extensive experiments using four SOTA LLMs on the SemEval 2016 dataset, covering the zero-shot and few-shot learning setups. The results indicate that the proposed method achieves state-of-the-art results with an F1 score of 79.84 in the few-shot setting.
Enhancing Retrieval-Augmented LMs with a Two-stage Consistency Learning Compressor
Jun 04, 2024



Despite the prevalence of retrieval-augmented language models (RALMs), the seamless integration of these models with retrieval mechanisms to enhance performance in document-based tasks remains challenging. While some post-retrieval processing Retrieval-Augmented Generation (RAG) methods have achieved success, most still lack the ability to distinguish pertinent from extraneous information, leading to potential inconsistencies and reduced precision in the generated output, which subsequently affects the truthfulness of the language model's responses. To address these limitations, this work proposes a novel two-stage consistency learning approach for retrieved information compression in retrieval-augmented language models to enhance performance. By incorporating consistency learning, the aim is to generate summaries that maintain coherence and alignment with the intended semantic representations of a teacher model while improving faithfulness to the original retrieved documents. The proposed method is empirically validated across multiple datasets, demonstrating notable enhancements in precision and efficiency for question-answering tasks. It outperforms existing baselines and showcases the synergistic effects of combining contrastive and consistency learning paradigms within the retrieval-augmented generation framework.
Improving Bridge estimators via $f$-GAN
Jun 24, 2021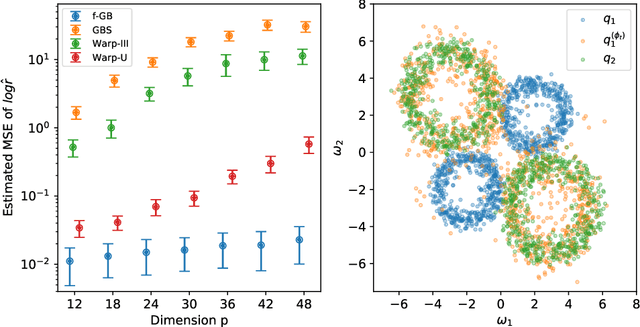
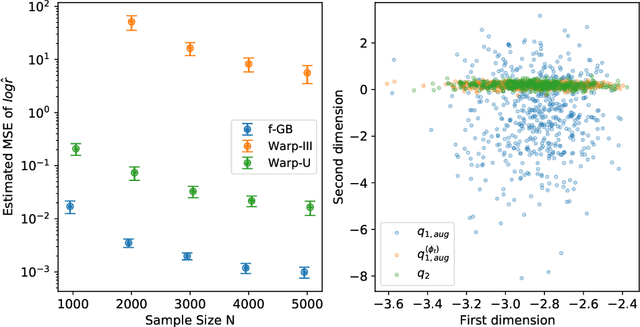

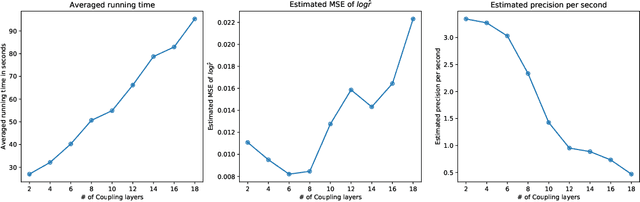
Bridge sampling is a powerful Monte Carlo method for estimating ratios of normalizing constants. Various methods have been introduced to improve its efficiency. These methods aim to increase the overlap between the densities by applying appropriate transformations to them without changing their normalizing constants. In this paper, we first give a new estimator of the asymptotic relative mean square error (RMSE) of the optimal Bridge estimator by equivalently estimating an $f$-divergence between the two densities. We then utilize this framework and propose $f$-GAN-Bridge estimator ($f$-GB) based on a bijective transformation that maps one density to the other and minimizes the asymptotic RMSE of the optimal Bridge estimator with respect to the densities. This transformation is chosen by minimizing a specific $f$-divergence between the densities using an $f$-GAN. We show $f$-GB is optimal in the sense that within any given set of candidate transformations, the $f$-GB estimator can asymptotically achieve an RMSE lower than or equal to that achieved by Bridge estimators based on any other transformed densities. Numerical experiments show that $f$-GB outperforms existing methods in simulated and real-world examples. In addition, we discuss how Bridge estimators naturally arise from the problem of $f$-divergence estimation.