 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPTON: Generative Pre-trained Transformers enhanced with Ontology Narration for accurate annotation of biological data
Oct 12, 2024

By leveraging GPT-4 for ontology narration, we developed GPTON to infuse structured knowledge into LLMs through verbalized ontology terms, achieving accurate text and ontology annotations for over 68% of gene sets in the top five predictions. Manual evaluations confirm GPTON's robustness, highlighting its potential to harness LLMs and structured knowledge to significantly advance biomedical research beyond gene set annotation.
Geneverse: A collection of Open-source Multimodal Large Language Models for Genomic and Proteomic Research
Jun 21, 2024The applications of large language models (LLMs) are promising for biomedical and healthcare research. Despite the availability of open-source LLMs trained using a wide range of biomedical data, current research on the applications of LLMs to genomics and proteomics is still limited. To fill this gap, we propose a collection of finetuned LLMs and multimodal LLMs (MLLMs), known as Geneverse, for three novel tasks in genomic and proteomic research. The models in Geneverse are trained and evaluated based on domain-specific datasets, and we use advanced parameter-efficient finetuning techniques to achieve the model adaptation for tasks including the generation of descriptions for gene functions, protein function inference from its structure, and marker gene selection from spatial transcriptomic data. We demonstrate that adapted LLMs and MLLMs perform well for these tasks and may outperform closed-source large-scale models based on our evaluations focusing on both truthfulness and structural correctness. All of the training strategies and base models we used are freely accessible.
Deep Representation Learning of Patient Data from Electronic Health Records (EHR): A Systematic Review
Oct 06, 2020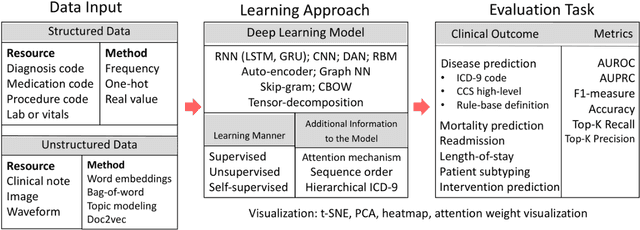
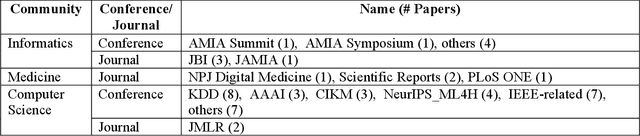
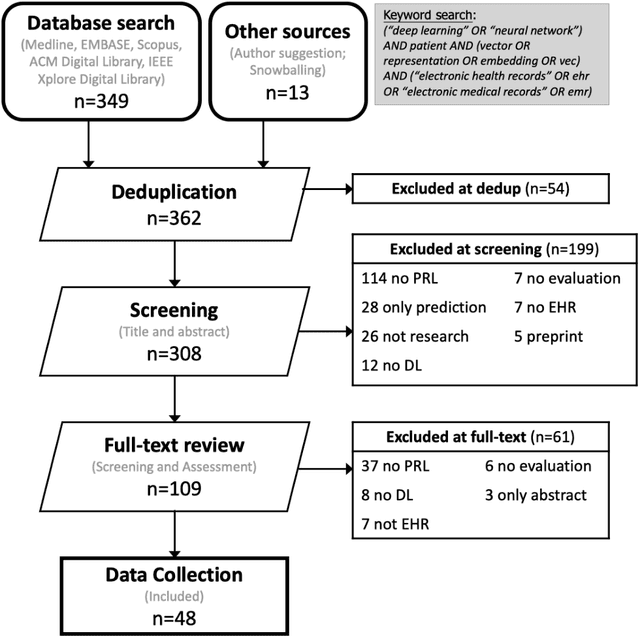
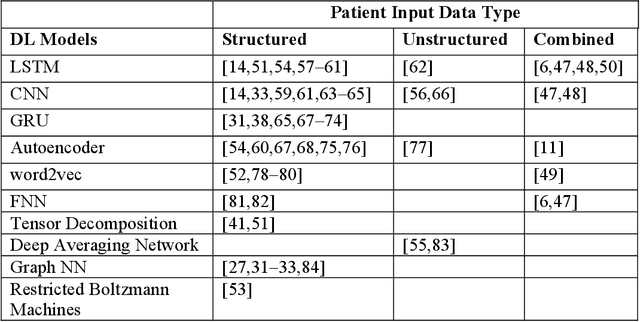
Patient representation learning refers to learning a dense mathematical representation of a patient that encodes meaningful information from Electronic Health Records (EHRs). This is generally performed using advanced deep learning methods. This study presents a systematic review of this field and provides both qualitative and quantitative analyses from a methodological perspective. We identified studies developing patient representations from EHRs with deep learning methods from MEDLINE, EMBASE, Scopus, the Association for Computing Machinery (ACM) Digital Library, and Institute of Electrical and Electronics Engineers (IEEE) Xplore Digital Library. After screening 362 articles, 48 papers were included for a comprehensive data collection. We noticed a typical workflow starting with feeding raw data, applying deep learning models, and ending with clinical outcome predictions as evaluations of the learned representations. Specifically, learning representations from structured EHR data was dominant (36 out of 48 studies). Recurrent Neural Networks were widely applied as the deep learning architecture (LSTM: 13 studies, GRU: 11 studies). Disease prediction was the most common application and evaluation (30 studies). Benchmark datasets were mostly unavailable (28 studies) due to privacy concerns of EHR data, and code availability was assured in 20 studies. We show the importance and feasibility of learning comprehensive representations of patient EHR data through a systematic review. Advances in patient representation learning techniques will be essential for powering patient-level EHR analyses. Future work will still be devoted to leveraging the richness and potential of available EHR data. Knowledge distillation and advanced learning techniques will be exploited to assist the capability of learning patient representation further.