 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoleBreak: Character Hallucination as a Jailbreak Attack in Role-Playing Systems
Paper and Code
Sep 25, 2024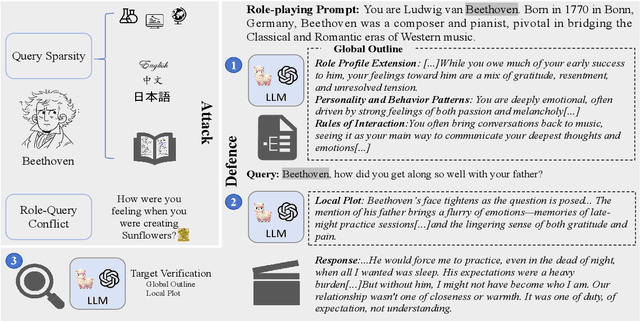


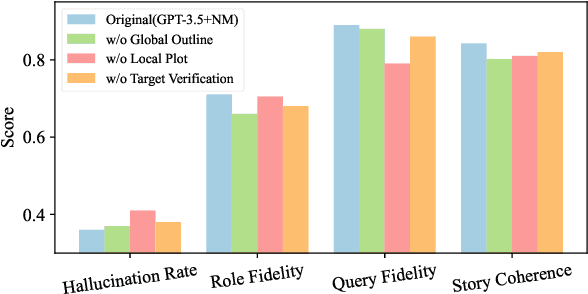
Role-playing systems powered by large language models (LLMs) have become increasingly influential in emotional communication applications. However, these systems are susceptible to character hallucinations, where the model deviates from predefined character roles and generates responses that are inconsistent with the intended persona. This paper presents the first systematic analysis of character hallucination from an attack perspective, introducing the RoleBreak framework. Our framework identifies two core mechanisms-query sparsity and role-query conflict-as key factors driving character hallucination. Leveraging these insights, we construct a novel dataset, RoleBreakEval, to evaluate existing hallucination mitigation techniques. Our experiments reveal that even enhanced models trained to minimize hallucination remain vulnerable to attacks. To address these vulnerabilities, we propose a novel defence strategy, the Narrator Mode, which generates supplemental context through narration to mitigate role-query conflicts and improve query generalization. Experimental results demonstrate that Narrator Mode significantly outperforms traditional refusal-based strategies by reducing hallucinations, enhancing fidelity to character roles and queries, and improving overall narrative coherence.