 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcing VLAs in Task-Agnostic World Models
May 12, 2026Post-training Vision-Language-Action (VLA) models via reinforcement learning (RL) in learned world models has emerged as an effective strategy to adapt to new tasks without costly real-world interactions. However, while using imagined trajectories reduces the sample complexity of policy training, existing methods still heavily rely on task-specific data to fine-tune both the world and reward models, fundamentally limiting their scalability to unseen tasks. To overcome this, we argue that world and reward models should capture transferable physical priors that enable zero-shot inference. We propose RAW-Dream (Reinforcing VLAs in task-Agnostic World Dreams), a new paradigm that completely disentangles world model learning from downstream task dependencies. RAW-Dream utilizes a world model pre-trained on diverse task-free behaviors for predicting future rollouts, and an off-the-shelf Vision-Language Model (VLM) for reward generation. Because both components are task-agnostic, VLAs can be readily finetuned for any new task entirely within this zero-shot imagination. Furthermore, to mitigate world model hallucinations, we introduce a dual-noise verification mechanism to filter out unreliable rollouts. Extensive experiments across simulation and real-world settings demonstrate consistent performance gains, proving that generalized physical priors can effectively substitute for costly task-dependent data, offering a highly scalable roadmap for VLA adaptation.
QA-ReID: Quality-Aware Query-Adaptive Convolution Leveraging Fused Global and Structural Cues for Clothes-Changing ReID
Jan 27, 2026Unlike conventional person re-identification (ReID), clothes-changing ReID (CC-ReID) presents severe challenges due to substantial appearance variations introduced by clothing changes. In this work, we propose the Quality-Aware Dual-Branch Matching (QA-ReID), which jointly leverages RGB-based features and parsing-based representations to model both global appearance and clothing-invariant structural cues. These heterogeneous features are adaptively fused through a multi-modal attention module. At the matching stage, we further design the Quality-Aware Query Adaptive Convolution (QAConv-QA), which incorporates pixel-level importance weighting and bidirectional consistency constraints to enhance robustness against clothing variations. Extensive experiments demonstrate that QA-ReID achieves state-of-the-art performance on multiple benchmarks, including PRCC, LTCC, and VC-Clothes, and significantly outperforms existing approaches under cross-clothing scenarios.
Fine-Grained DINO Tuning with Dual Supervision for Face Forgery Detection
Nov 15, 2025The proliferation of sophisticated deepfakes poses significant threats to information integrity. While DINOv2 shows promise for detection, existing fine-tuning approaches treat it as generic binary classification, overlooking distinct artifacts inherent to different deepfake methods. To address this, we propose a DeepFake Fine-Grained Adapter (DFF-Adapter) for DINOv2. Our method incorporates lightweight multi-head LoRA modules into every transformer block, enabling efficient backbone adaptation. DFF-Adapter simultaneously addresses authenticity detection and fine-grained manipulation type classification, where classifying forgery methods enhances artifact sensitivity. We introduce a shared branch propagating fine-grained manipulation cues to the authenticity head. This enables multi-task cooperative optimization, explicitly enhancing authenticity discrimination with manipulation-specific knowledge. Utilizing only 3.5M trainable parameters, our parameter-efficient approach achieves detection accuracy comparable to or even surpassing that of current complex state-of-the-art methods.
MoL-RL: Distilling Multi-Step Environmental Feedback into LLMs for Feedback-Independent Reasoning
Jul 27, 2025Large language models (LLMs) face significant challenges in effectively leveraging sequential environmental feedback (EF) signals, such as natural language evaluations, for feedback-independent chain-of-thought (CoT) reasoning. Existing approaches either convert EF into scalar rewards, losing rich contextual information, or employ refinement datasets, failing to exploit the multi-step and discrete nature of EF interactions. To address these limitations, we propose MoL-RL, a novel training paradigm that integrates multi-step EF signals into LLMs through a dual-objective optimization framework. Our method combines MoL (Mixture-of-Losses) continual training, which decouples domain-specific EF signals (optimized via cross-entropy loss) and general language capabilities (preserved via Kullback-Leibler divergence), with GRPO-based post-training to distill sequential EF interactions into single-step inferences. This synergy enables robust feedback-independent reasoning without relying on external feedback loops. Experimental results on mathematical reasoning (MATH-500, AIME24/AIME25) and code generation (CodeAgent-Test) benchmarks demonstrate that MoL-RL achieves state-of-the-art performance with the Qwen3-8B model, while maintaining strong generalization across model scales (Qwen3-4B). This work provides a promising approach for leveraging multi-step textual feedback to enhance LLMs' reasoning capabilities in diverse domains.
Neural Brain: A Neuroscience-inspired Framework for Embodied Agents
May 14, 2025The rapid evolution of artificial intelligence (AI) has shifted from static, data-driven models to dynamic systems capable of perceiving and interacting with real-world environments. Despite advancements in pattern recognition and symbolic reasoning, current AI systems, such as large language models, remain disembodied, unable to physically engage with the world. This limitation has driven the rise of embodied AI, where autonomous agents, such as humanoid robots, must navigate and manipulate unstructured environments with human-like adaptability. At the core of this challenge lies the concept of Neural Brain, a central intelligence system designed to drive embodied agents with human-like adaptability. A Neural Brain must seamlessly integrate multimodal sensing and perception with cognitive capabilities. Achieving this also requires an adaptive memory system and energy-efficient hardware-software co-design, enabling real-time action in dynamic environments. This paper introduces a unified framework for the Neural Brain of embodied agents, addressing two fundamental challenges: (1) defining the core components of Neural Brain and (2) bridging the gap between static AI models and the dynamic adaptability required for real-world deployment. To this end, we propose a biologically inspired architecture that integrates multimodal active sensing, perception-cognition-action function, neuroplasticity-based memory storage and updating, and neuromorphic hardware/software optimization. Furthermore, we also review the latest research on embodied agents across these four aspects and analyze the gap between current AI systems and human intelligence. By synthesizing insights from neuroscience, we outline a roadmap towards the development of generalizable, autonomous agents capable of human-level intelligence in real-world scenarios.
Learning Like Humans: Advancing LLM Reasoning Capabilities via Adaptive Difficulty Curriculum Learning and Expert-Guided Self-Reformulation
May 13, 2025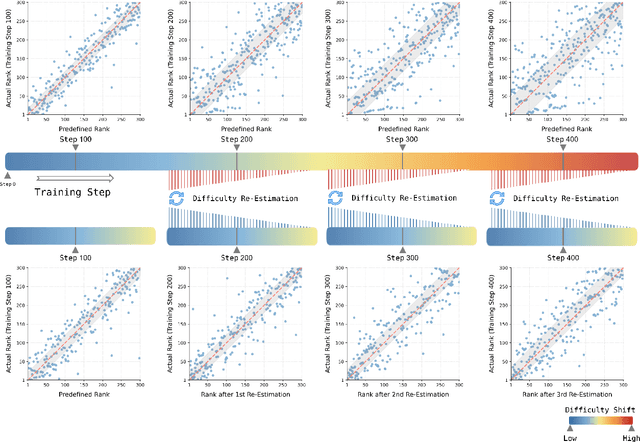
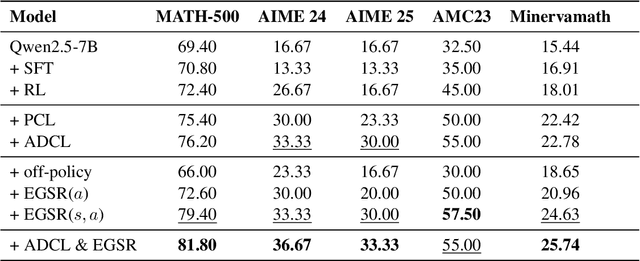
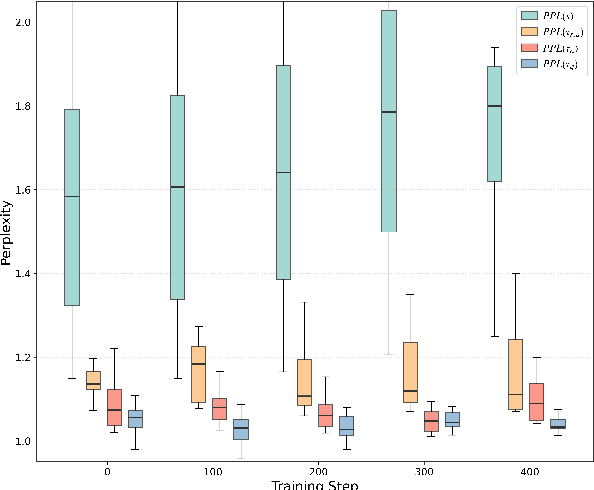

Despite impressive progress in areas like mathematical reasoning, large language models still face significant challenges in consistently solving complex problems. Drawing inspiration from key human learning strategies, we propose two novel strategies to enhance the capability of large language models to solve these complex problems. First, Adaptive Difficulty Curriculum Learning (ADCL) is a novel curriculum learning strategy that tackles the Difficulty Shift phenomenon (i.e., a model's perception of problem difficulty dynamically changes during training) by periodically re-estimating difficulty within upcoming data batches to maintain alignment with the model's evolving capabilities. Second, Expert-Guided Self-Reformulation (EGSR) is a novel reinforcement learning strategy that bridges the gap between imitation learning and pure exploration by guiding models to reformulate expert solutions within their own conceptual framework, rather than relying on direct imitation, fostering deeper understanding and knowledge assimilation. Extensive experiments on challenging mathematical reasoning benchmarks, using Qwen2.5-7B as the base model, demonstrate that these human-inspired strategies synergistically and significantly enhance performance. Notably, their combined application improves performance over the standard Zero-RL baseline by 10% on the AIME24 benchmark and 16.6% on AIME25.
Referring Remote Sensing Image Segmentation via Bidirectional Alignment Guided Joint Prediction
Feb 12, 2025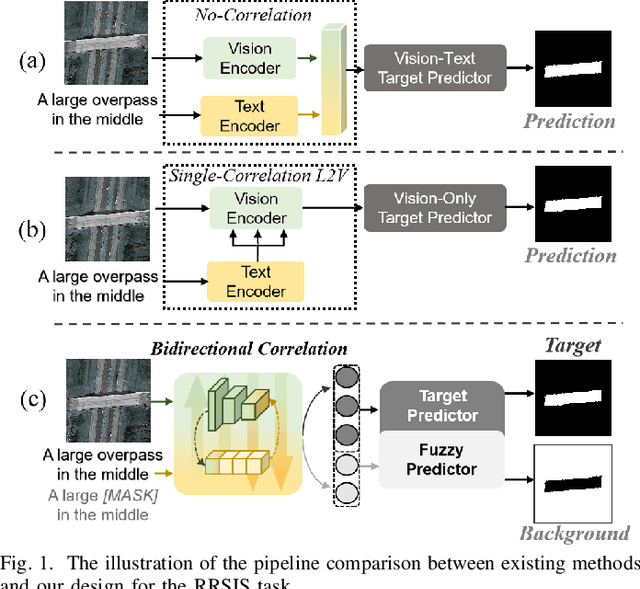



Referring Remote Sensing Image Segmentation (RRSIS) is critical for ecological monitoring, urban planning, and disaster management, requiring precise segmentation of objects in remote sensing imagery guided by textual descriptions. This task is uniquely challenging due to the considerable vision-language gap, the high spatial resolution and broad coverage of remote sensing imagery with diverse categories and small targets, and the presence of clustered, unclear targets with blurred edges. To tackle these issues, we propose \ours, a novel framework designed to bridge the vision-language gap, enhance multi-scale feature interaction, and improve fine-grained object differentiation. Specifically, \ours introduces: (1) the Bidirectional Spatial Correlation (BSC) for improved vision-language feature alignment, (2) the Target-Background TwinStream Decoder (T-BTD) for precise distinction between targets and non-targets, and (3) the Dual-Modal Object Learning Strategy (D-MOLS) for robust multimodal feature reconstruction. Extensive experiments on the benchmark datasets RefSegRS and RRSIS-D demonstrate that \ours achieves state-of-the-art performance. Specifically, \ours improves the overall IoU (oIoU) by 3.76 percentage points (80.57) and 1.44 percentage points (79.23) on the two datasets, respectively. Additionally, it outperforms previous methods in the mean IoU (mIoU) by 5.37 percentage points (67.95) and 1.84 percentage points (66.04), effectively addressing the core challenges of RRSIS with enhanced precision and robustness.
A Real-time Degeneracy Sensing and Compensation Method for Enhanced LiDAR SLAM
Dec 10, 2024



LiDAR is widely used in Simultaneous Localization and Mapping (SLAM) and autonomous driving. The LiDAR odometry is of great importance in multi-sensor fusion. However, in some unstructured environments, the point cloud registration cannot constrain the poses of the LiDAR due to its sparse geometric features, which leads to the degeneracy of multi-sensor fusion accuracy. To address this problem, we propose a novel real-time approach to sense and compensate for the degeneracy of LiDAR. Firstly, this paper introduces the degeneracy factor with clear meaning, which can measure the degeneracy of LiDAR. Then, the Density-Based Spatial Clustering of Applications with Noise (DBSCAN) clustering method adaptively perceives the degeneracy with better environmental generalization. Finally, the degeneracy perception results are utilized to fuse LiDAR and IMU, thus effectively resisting degeneracy effects. Experiments on our dataset show the method's high accuracy and robustness and validate our algorithm's adaptability to different environments and LiDAR scanning modalities.
AC-LIO: Towards Asymptotic and Consistent Convergence in LiDAR-Inertial Odometry
Dec 08, 2024



Existing LiDAR-Inertial Odometry (LIO) frameworks typically utilize prior state trajectories derived from IMU integration to compensate for the motion distortion within LiDAR frames, and demonstrate outstanding accuracy and stability in regular low-speed and smooth scenes. However, in high-speed or intense motion scenarios, the residual distortion may increase due to the limitation of IMU's accuracy and frequency, which will degrade the consistency between the LiDAR frame with its represented geometric environment, leading pointcloud registration to fall into local optima and consequently increasing the drift in long-time and large-scale localization. To address the issue, we propose a novel asymptotically and consistently converging LIO framework called AC-LIO. First, during the iterative state estimation, we backwards propagate the update term based on the prior state chain, and asymptotically compensate the residual distortion before next iteration. Second, considering the weak correlation between the initial error and motion distortion of current frame, we propose a convergence criteria based on pointcloud constraints to control the back propagation. The approach of guiding the asymptotic distortion compensation based on convergence criteria can promote the consistent convergence of pointcloud registration and increase the accuracy and robustness of LIO. Experiments show that our AC-LIO framework, compared to other state-of-the-art frameworks, effectively promotes consistent convergence in state estimation and further improves the accuracy of long-time and large-scale localization and mapping.
AS-LIO: Spatial Overlap Guided Adaptive Sliding Window LiDAR-Inertial Odometry for Aggressive FOV Variation
Aug 21, 2024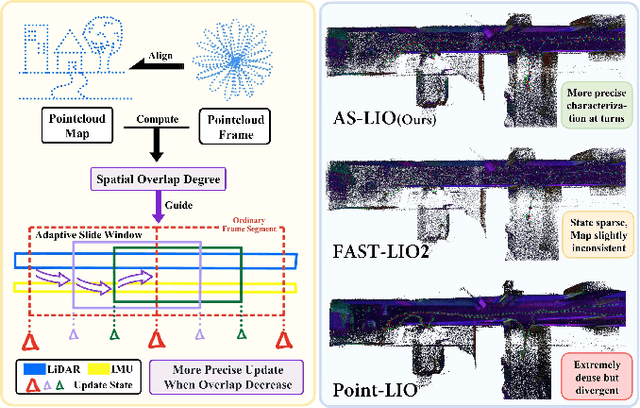
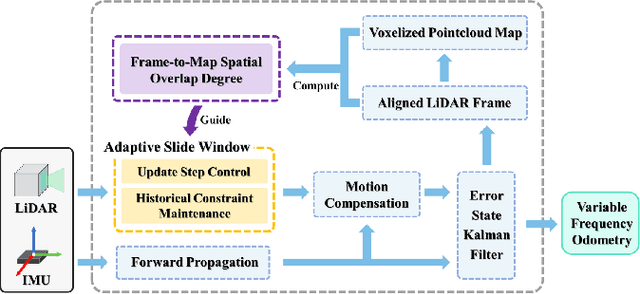

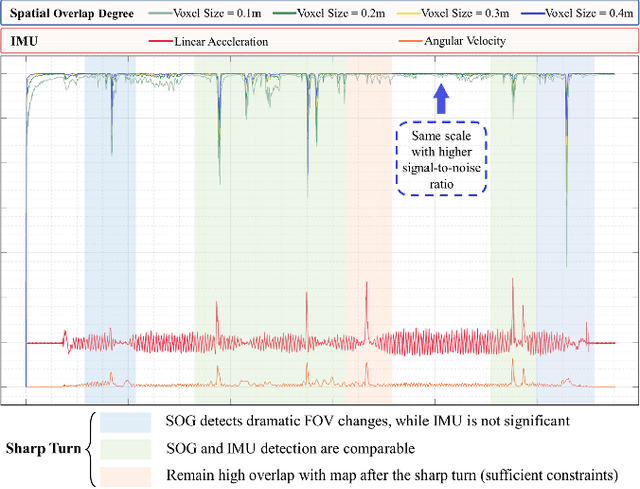
LiDAR-Inertial Odometry (LIO) demonstrates outstanding accuracy and stability in general low-speed and smooth motion scenarios. However, in high-speed and intense motion scenarios, such as sharp turns, two primary challenges arise: firstly, due to the limitations of IMU frequency, the error in estimating significantly non-linear motion states escalates; secondly, drastic changes in the Field of View (FOV) may diminish the spatial overlap between LiDAR frame and pointcloud map (or between frames), leading to insufficient data association and constraint degradation. To address these issues, we propose a novel Adaptive Sliding window LIO framework (AS-LIO) guided by the Spatial Overlap Degree (SOD). Initially, we assess the SOD between the LiDAR frames and the registered map, directly evaluating the adverse impact of current FOV variation on pointcloud alignment. Subsequently, we design an adaptive sliding window to manage the continuous LiDAR stream and control state updates, dynamically adjusting the update step according to the SOD. This strategy enables our odometry to adaptively adopt higher update frequency to precisely characterize trajectory during aggressive FOV variation, thus effectively reducing the non-linear error in positioning. Meanwhile, the historical constraints within the sliding window reinforce the frame-to-map data association, ensuring the robustness of state estimation. Experiments show that our AS-LIO framework can quickly perceive and respond to challenging FOV change, outperforming other state-of-the-art LIO frameworks in terms of accuracy and robustness.