 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePositive-Negative Equal Contrastive Loss for Semantic Segmentation
Paper and Code
Jul 05, 2022
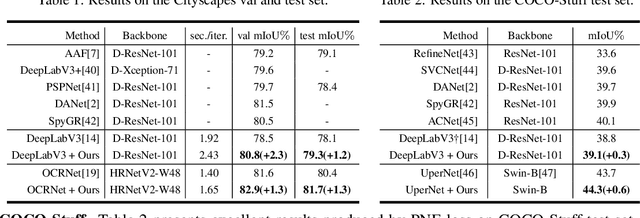
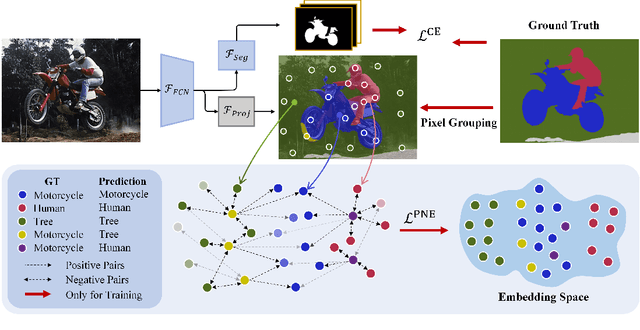
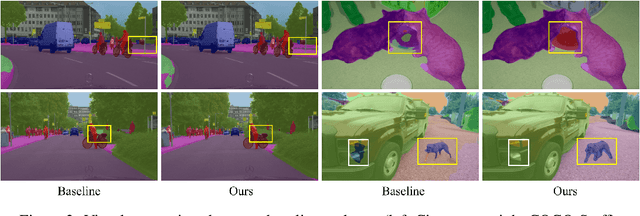
The contextual information is critical for various computer vision tasks, previous works commonly design plug-and-play modules and structural losses to effectively extract and aggregate the global context. These methods utilize fine-label to optimize the model but ignore that fine-trained features are also precious training resources, which can introduce preferable distribution to hard pixels (i.e., misclassified pixels). Inspired by contrastive learning in unsupervised paradigm, we apply the contrastive loss in a supervised manner and re-design the loss function to cast off the stereotype of unsupervised learning (e.g., imbalance of positives and negatives, confusion of anchors computing). To this end, we propose Positive-Negative Equal contrastive loss (PNE loss), which increases the latent impact of positive embedding on the anchor and treats the positive as well as negative sample pairs equally. The PNE loss can be directly plugged right into existing semantic segmentation frameworks and leads to excellent performance with neglectable extra computational costs. We utilize a number of classic segmentation methods (e.g., DeepLabV3, OCRNet, UperNet) and backbone (e.g., ResNet, HRNet, Swin Transformer) to conduct comprehensive experiments and achieve state-of-the-art performance on two benchmark datasets (e.g., Cityscapes and COCO-Stuff). Our code will be publicly available soon.