 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetimeGS: Continuous-Time Reconstruction of 4D Gaussian Splatting
Mar 14, 2026Temporal retiming, the ability to reconstruct and render dynamic scenes at arbitrary timestamps, is crucial for applications such as slow-motion playback, temporal editing, and post-production. However, most existing 4D Gaussian Splatting (4DGS) methods overfit at discrete frame indices but struggle to represent continuous-time frames, leading to ghosting artifacts when interpolating between timestamps. We identify this limitation as a form of temporal aliasing and propose RetimeGS, a simple yet effective 4DGS representation that explicitly defines the temporal behavior of the 3D Gaussian and mitigates temporal aliasing. To achieve smooth and consistent interpolation, we incorporate optical flow-guided initialization and supervision, triple-rendering supervision, and other targeted strategies. Together, these components enable ghost-free, temporally coherent rendering even under large motions. Experiments on datasets featuring fast motion, non-rigid deformation, and severe occlusions demonstrate that RetimeGS achieves superior quality and coherence over state-of-the-art methods.
LHPF: Look back the History and Plan for the Future in Autonomous Driving
Nov 26, 2024Decision-making and planning in autonomous driving critically reflect the safety of the system, making effective planning imperative. Current imitation learning-based planning algorithms often merge historical trajectories with present observations to predict future candidate paths. However, these algorithms typically assess the current and historical plans independently, leading to discontinuities in driving intentions and an accumulation of errors with each step in a discontinuous plan. To tackle this challenge, this paper introduces LHPF, an imitation learning planner that integrates historical planning information. Our approach employs a historical intention aggregation module that pools historical planning intentions, which are then combined with a spatial query vector to decode the final planning trajectory. Furthermore, we incorporate a comfort auxiliary task to enhance the human-like quality of the driving behavior. Extensive experiments using both real-world and synthetic data demonstrate that LHPF not only surpasses existing advanced learning-based planners in planning performance but also marks the first instance of a purely learning-based planner outperforming the expert. Additionally, the application of the historical intention aggregation module across various backbones highlights the considerable potential of the proposed method. The code will be made publicly available.
3D Video Loops from Asynchronous Input
Mar 21, 2023
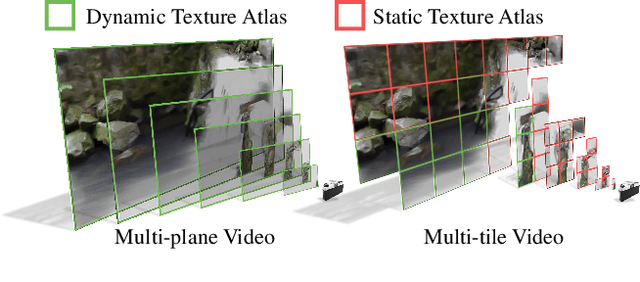
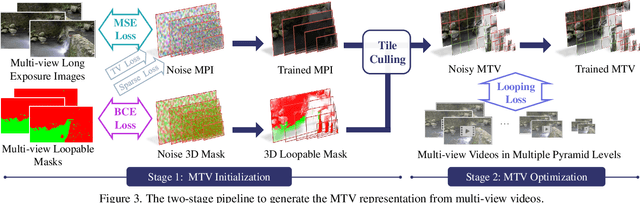
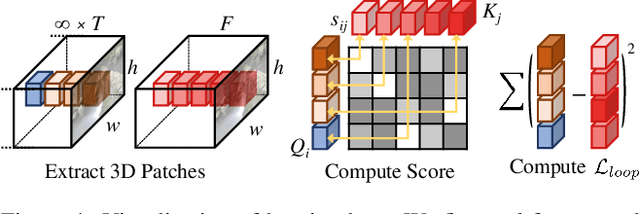
Looping videos are short video clips that can be looped endlessly without visible seams or artifacts. They provide a very attractive way to capture the dynamism of natural scenes. Existing methods have been mostly limited to 2D representations. In this paper, we take a step forward and propose a practical solution that enables an immersive experience on dynamic 3D looping scenes. The key challenge is to consider the per-view looping conditions from asynchronous input while maintaining view consistency for the 3D representation. We propose a novel sparse 3D video representation, namely Multi-Tile Video (MTV), which not only provides a view-consistent prior, but also greatly reduces memory usage, making the optimization of a 4D volume tractable. Then, we introduce a two-stage pipeline to construct the 3D looping MTV from completely asynchronous multi-view videos with no time overlap. A novel looping loss based on video temporal retargeting algorithms is adopted during the optimization to loop the 3D scene. Experiments of our framework have shown promise in successfully generating and rendering photorealistic 3D looping videos in real time even on mobile devices. The code, dataset, and live demos are available in https://limacv.github.io/VideoLoop3D_web/.
Water Simulation and Rendering from a Still Photograph
Oct 05, 2022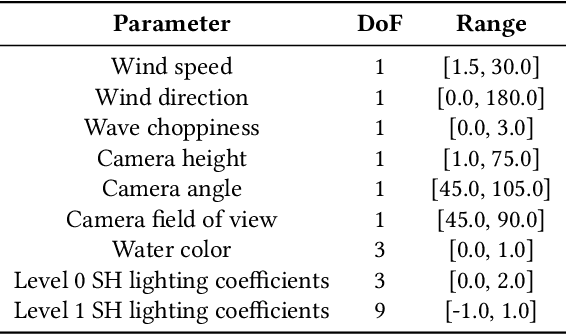
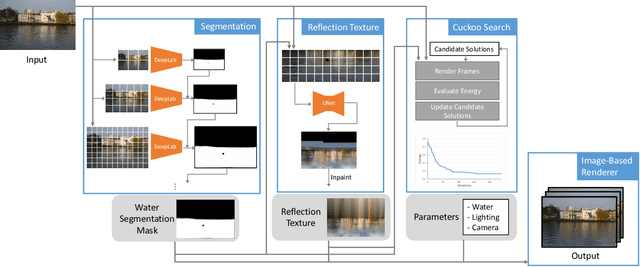


We propose an approach to simulate and render realistic water animation from a single still input photograph. We first segment the water surface, estimate rendering parameters, and compute water reflection textures with a combination of neural networks and traditional optimization techniques. Then we propose an image-based screen space local reflection model to render the water surface overlaid on the input image and generate real-time water animation. Our approach creates realistic results with no user intervention for a wide variety of natural scenes containing large bodies of water with different lighting and water surface conditions. Since our method provides a 3D representation of the water surface, it naturally enables direct editing of water parameters and also supports interactive applications like adding synthetic objects to the scene.
Deblur-NeRF: Neural Radiance Fields from Blurry Images
Nov 29, 2021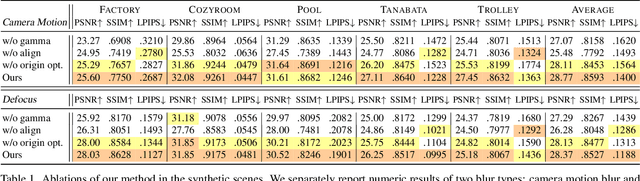
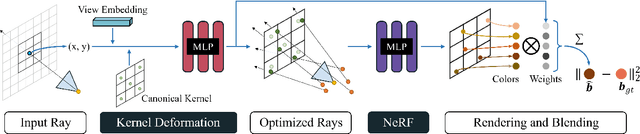
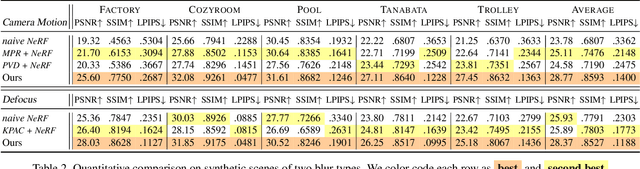
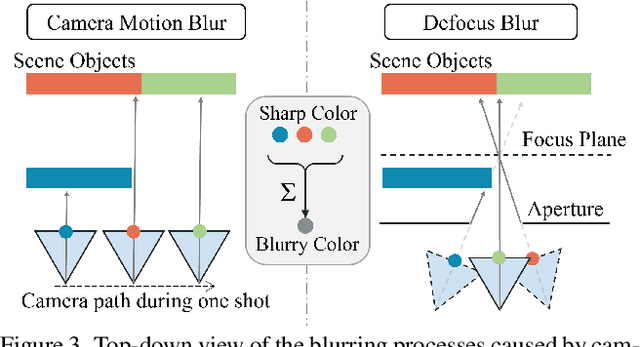
Neural Radiance Field (NeRF) has gained considerable attention recently for 3D scene reconstruction and novel view synthesis due to its remarkable synthesis quality. However, image blurriness caused by defocus or motion, which often occurs when capturing scenes in the wild, significantly degrades its reconstruction quality. To address this problem, We propose Deblur-NeRF, the first method that can recover a sharp NeRF from blurry input. We adopt an analysis-by-synthesis approach that reconstructs blurry views by simulating the blurring process, thus making NeRF robust to blurry inputs. The core of this simulation is a novel Deformable Sparse Kernel (DSK) module that models spatially-varying blur kernels by deforming a canonical sparse kernel at each spatial location. The ray origin of each kernel point is jointly optimized, inspired by the physical blurring process. This module is parameterized as an MLP that has the ability to be generalized to various blur types. Jointly optimizing the NeRF and the DSK module allows us to restore a sharp NeRF. We demonstrate that our method can be used on both camera motion blur and defocus blur: the two most common types of blur in real scenes. Evaluation results on both synthetic and real-world data show that our method outperforms several baselines. The synthetic and real datasets along with the source code will be made publicly available to facilitate future research.
Microshift: An Efficient Image Compression Algorithm for Hardware
Apr 20, 2021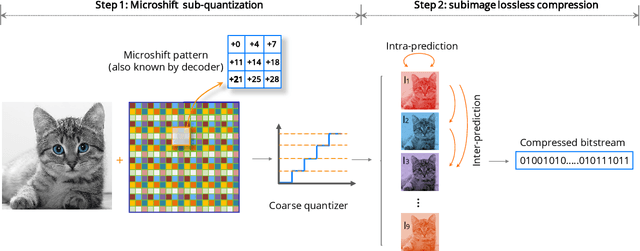
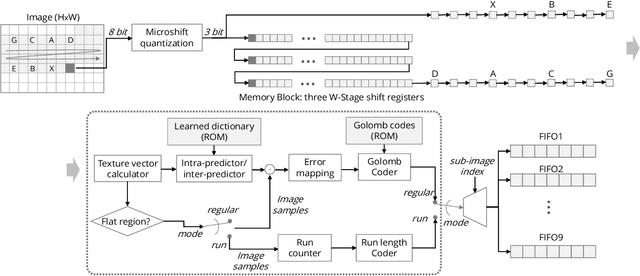


In this paper, we propose an image compression algorithm called Microshift. We employ an algorithm hardware co-design methodology, yielding a hardware-friendly compression approach with low power consumption. In our method, the image is first micro-shifted, then the sub-quantized values are further compressed. Two methods, the FAST and MRF model, are proposed to recover the bit-depth by exploiting the spatial correlation of natural images. Both methods can decompress images progressively. Our compression algorithm compresses images to 1.25 bits per pixel on average with PSNR of 33.16 dB, outperforming other on-chip compression algorithms. Then, we propose a hardware architecture and implement the algorithm on an FPGA and ASIC. The results on the VLSI design further validate the low hardware complexity and high power efficiency, showing our method is promising, particularly for low-power wireless vision sensor networks.
Let's See Clearly: Contaminant Artifact Removal for Moving Cameras
Apr 18, 2021
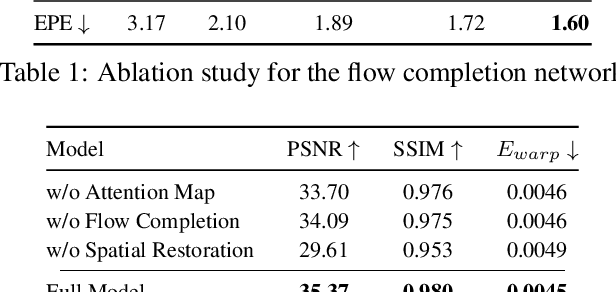
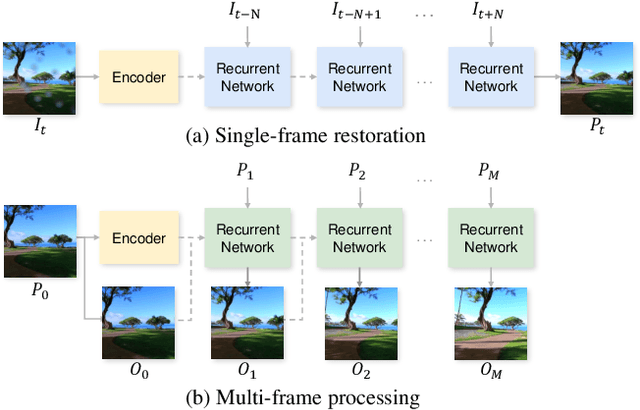

Contaminants such as dust, dirt and moisture adhering to the camera lens can greatly affect the quality and clarity of the resulting image or video. In this paper, we propose a video restoration method to automatically remove these contaminants and produce a clean video. Our approach first seeks to detect attention maps that indicate the regions that need to be restored. In order to leverage the corresponding clean pixels from adjacent frames, we propose a flow completion module to hallucinate the flow of the background scene to the attention regions degraded by the contaminants. Guided by the attention maps and completed flows, we propose a recurrent technique to restore the input frame by fetching clean pixels from adjacent frames. Finally, a multi-frame processing stage is used to further process the entire video sequence in order to enforce temporal consistency. The entire network is trained on a synthetic dataset that approximates the physical lighting properties of contaminant artifacts. This new dataset and our novel framework lead to our method that is able to address different contaminants and outperforms competitive restoration approaches both qualitatively and quantitatively.
Deep Sketch-guided Cartoon Video Synthesis
Aug 10, 2020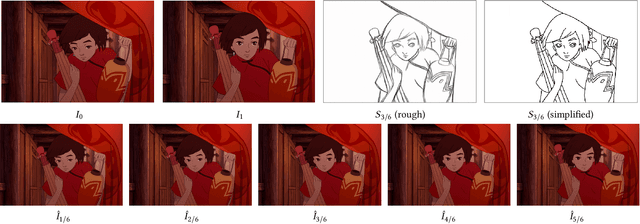
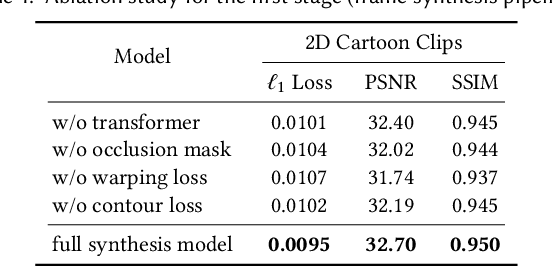

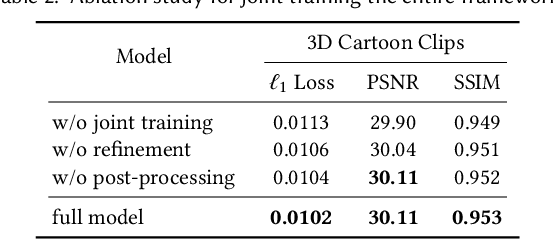
We propose a novel framework to produce cartoon videos by fetching the color information from two input keyframes while following the animated motion guided by a user sketch. The key idea of the proposed approach is to estimate the dense cross-domain correspondence between the sketch and cartoon video frames, following by a blending module with occlusion estimation to synthesize the middle frame guided by the sketch. After that, the inputs and the synthetic frame equipped with established correspondence are fed into an arbitrary-time frame interpolation pipeline to generate and refine additional inbetween frames. Finally, a video post-processing approach is used to further improve the result. Compared to common frame interpolation methods, our approach can address frames with relatively large motion and also has the flexibility to enable users to control the generated video sequences by editing the sketch guidance. By explicitly considering the correspondence between frames and the sketch, our methods can achieve high-quality synthetic results compared with image synthesis methods. Our results show that our system generalizes well to different movie frames, achieving better results than existing solutions.
Document Rectification and Illumination Correction using a Patch-based CNN
Sep 20, 2019
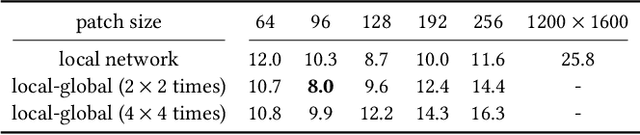
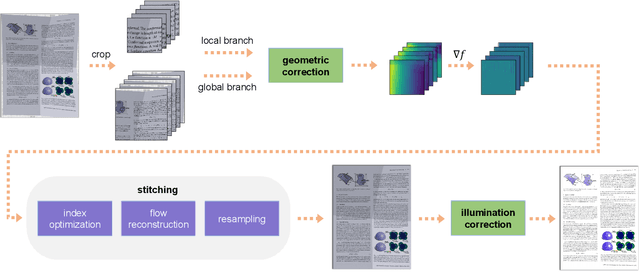
We propose a novel learning method to rectify document images with various distortion types from a single input image. As opposed to previous learning-based methods, our approach seeks to first learn the distortion flow on input image patches rather than the entire image. We then present a robust technique to stitch the patch results into the rectified document by processing in the gradient domain. Furthermore, we propose a second network to correct the uneven illumination, further improving the readability and OCR accuracy. Due to the less complex distortion present on the smaller image patches, our patch-based approach followed by stitching and illumination correction can significantly improve the overall accuracy in both the synthetic and real datasets.
Blind Geometric Distortion Correction on Images Through Deep Learning
Sep 08, 2019



We propose the first general framework to automatically correct different types of geometric distortion in a single input image. Our proposed method employs convolutional neural networks (CNNs) trained by using a large synthetic distortion dataset to predict the displacement field between distorted images and corrected images. A model fitting method uses the CNN output to estimate the distortion parameters, achieving a more accurate prediction. The final corrected image is generated based on the predicted flow using an efficient, high-quality resampling method. Experimental results demonstrate that our algorithm outperforms traditional correction methods, and allows for interesting applications such as distortion transfer, distortion exaggeration, and co-occurring distortion correction.