 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocument Rectification and Illumination Correction using a Patch-based CNN
Paper and Code

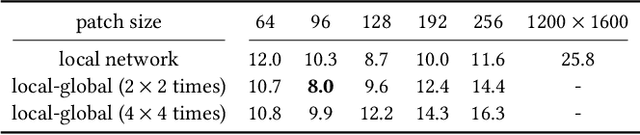
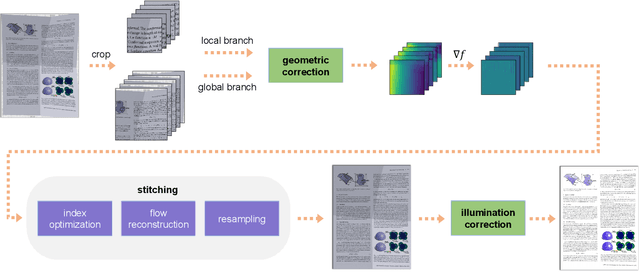
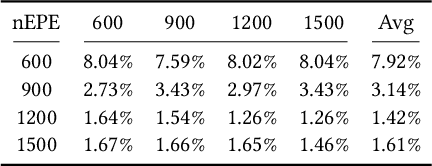
We propose a novel learning method to rectify document images with various distortion types from a single input image. As opposed to previous learning-based methods, our approach seeks to first learn the distortion flow on input image patches rather than the entire image. We then present a robust technique to stitch the patch results into the rectified document by processing in the gradient domain. Furthermore, we propose a second network to correct the uneven illumination, further improving the readability and OCR accuracy. Due to the less complex distortion present on the smaller image patches, our patch-based approach followed by stitching and illumination correction can significantly improve the overall accuracy in both the synthetic and real datasets.