 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferring Physical Priors into Remote Sensing Segmentation via Large Language Models
Mar 29, 2026Semantic segmentation of remote sensing imagery is fundamental to Earth observation. Achieving accurate results requires integrating not only optical images but also physical variables such as the Digital Elevation Model (DEM), Synthetic Aperture Radar (SAR) and Normalized Difference Vegetation Index (NDVI). Recent foundation models (FMs) leverage pre-training to exploit these variables but still depend on spatially aligned data and costly retraining when involving new sensors. To overcome these limitations, we introduce a novel paradigm for integrating domain-specific physical priors into segmentation models. We first construct a Physical-Centric Knowledge Graph (PCKG) by prompting large language models to extract physical priors from 1,763 vocabularies, and use it to build a heterogeneous, spatial-aligned dataset, Phy-Sky-SA. Building on this foundation, we develop PriorSeg, a physics-aware residual refinement model trained with a joint visual-physical strategy that incorporates a novel physics-consistency loss. Experiments on heterogeneous settings demonstrate that PriorSeg improves segmentation accuracy and physical plausibility without retraining the FMs. Ablation studies verify the effectiveness of the Phy-Sky-SA dataset, the PCKG, and the physics-consistency loss.
RcAE: Recursive Reconstruction Framework for Unsupervised Industrial Anomaly Detection
Dec 12, 2025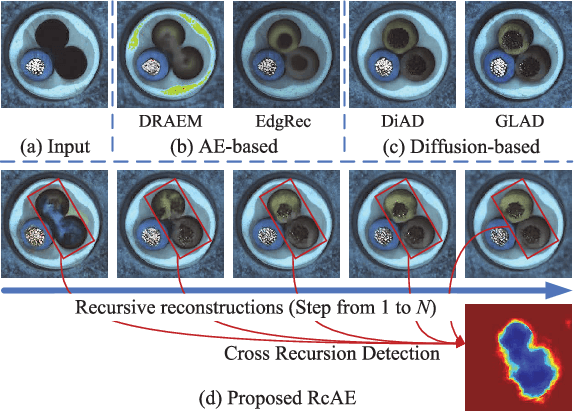
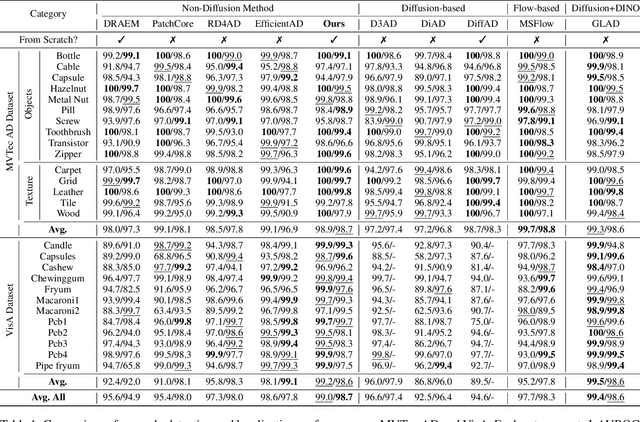
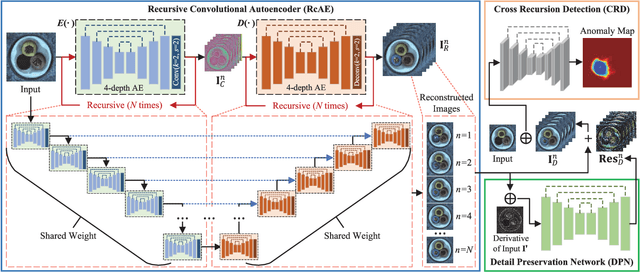
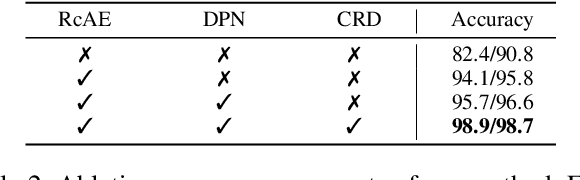
Unsupervised industrial anomaly detection requires accurately identifying defects without labeled data. Traditional autoencoder-based methods often struggle with incomplete anomaly suppression and loss of fine details, as their single-pass decoding fails to effectively handle anomalies with varying severity and scale. We propose a recursive architecture for autoencoder (RcAE), which performs reconstruction iteratively to progressively suppress anomalies while refining normal structures. Unlike traditional single-pass models, this recursive design naturally produces a sequence of reconstructions, progressively exposing suppressed abnormal patterns. To leverage this reconstruction dynamics, we introduce a Cross Recursion Detection (CRD) module that tracks inconsistencies across recursion steps, enhancing detection of both subtle and large-scale anomalies. Additionally, we incorporate a Detail Preservation Network (DPN) to recover high-frequency textures typically lost during reconstruction. Extensive experiments demonstrate that our method significantly outperforms existing non-diffusion methods, and achieves performance on par with recent diffusion models with only 10% of their parameters and offering substantially faster inference. These results highlight the practicality and efficiency of our approach for real-world applications.
FAME: Fairness-aware Attention-modulated Video Editing
Oct 27, 2025Training-free video editing (VE) models tend to fall back on gender stereotypes when rendering profession-related prompts. We propose \textbf{FAME} for \textit{Fairness-aware Attention-modulated Video Editing} that mitigates profession-related gender biases while preserving prompt alignment and temporal consistency for coherent VE. We derive fairness embeddings from existing minority representations by softly injecting debiasing tokens into the text encoder. Simultaneously, FAME integrates fairness modulation into both temporal self attention and prompt-to-region cross attention to mitigate the motion corruption and temporal inconsistency caused by directly introducing fairness cues. For temporal self attention, FAME introduces a region constrained attention mask combined with time decay weighting, which enhances intra-region coherence while suppressing irrelevant inter-region interactions. For cross attention, it reweights tokens to region matching scores by incorporating fairness sensitive similarity masks derived from debiasing prompt embeddings. Together, these modulations keep fairness-sensitive semantics tied to the right visual regions and prevent temporal drift across frames. Extensive experiments on new VE fairness-oriented benchmark \textit{FairVE} demonstrate that FAME achieves stronger fairness alignment and semantic fidelity, surpassing existing VE baselines.
Multimodal Machine Learning for Real Estate Appraisal: A Comprehensive Survey
Mar 28, 2025



Real estate appraisal has undergone a significant transition from manual to automated valuation and is entering a new phase of evolution. Leveraging comprehensive attention to various data sources, a novel approach to automated valuation, multimodal machine learning, has taken shape. This approach integrates multimodal data to deeply explore the diverse factors influencing housing prices. Furthermore, multimodal machine learning significantly outperforms single-modality or fewer-modality approaches in terms of prediction accuracy, with enhanced interpretability. However, systematic and comprehensive survey work on the application in the real estate domain is still lacking. In this survey, we aim to bridge this gap by reviewing the research efforts. We begin by reviewing the background of real estate appraisal and propose two research questions from the perspecve of performance and fusion aimed at improving the accuracy of appraisal results. Subsequently, we explain the concept of multimodal machine learning and provide a comprehensive classification and definition of modalities used in real estate appraisal for the first time. To ensure clarity, we explore works related to data and techniques, along with their evaluation methods, under the framework of these two research questions. Furthermore, specific application domains are summarized. Finally, we present insights into future research directions including multimodal complementarity, technology and modality contribution.
Navigating Towards Fairness with Data Selection
Dec 15, 2024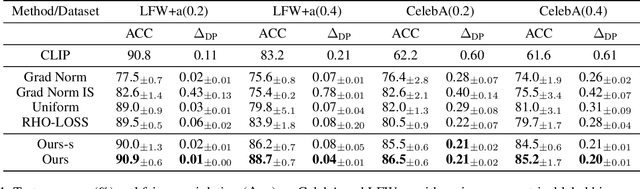
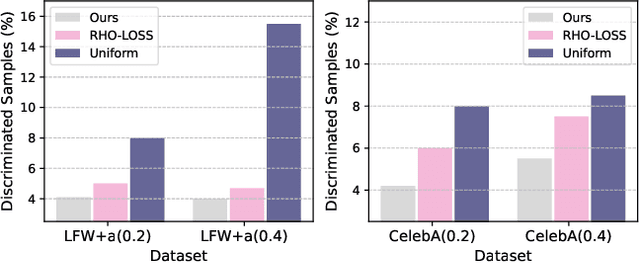
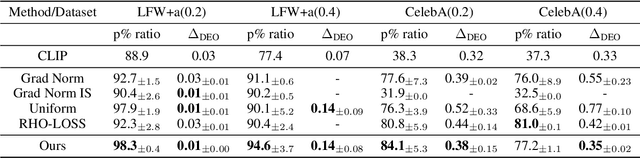
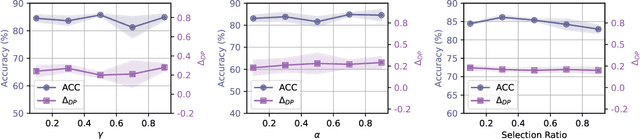
Machine learning algorithms often struggle to eliminate inherent data biases, particularly those arising from unreliable labels, which poses a significant challenge in ensuring fairness. Existing fairness techniques that address label bias typically involve modifying models and intervening in the training process, but these lack flexibility for large-scale datasets. To address this limitation, we introduce a data selection method designed to efficiently and flexibly mitigate label bias, tailored to more practical needs. Our approach utilizes a zero-shot predictor as a proxy model that simulates training on a clean holdout set. This strategy, supported by peer predictions, ensures the fairness of the proxy model and eliminates the need for an additional holdout set, which is a common requirement in previous methods. Without altering the classifier's architecture, our modality-agnostic method effectively selects appropriate training data and has proven efficient and effective in handling label bias and improving fairness across diverse datasets in experimental evaluations.
Can GNNs Learn Link Heuristics? A Concise Review and Evaluation of Link Prediction Methods
Nov 22, 2024This paper explores the ability of Graph Neural Networks (GNNs) in learning various forms of information for link prediction, alongside a brief review of existing link prediction methods. Our analysis reveals that GNNs cannot effectively learn structural information related to the number of common neighbors between two nodes, primarily due to the nature of set-based pooling of the neighborhood aggregation scheme. Also, our extensive experiments indicate that trainable node embeddings can improve the performance of GNN-based link prediction models. Importantly, we observe that the denser the graph, the greater such the improvement. We attribute this to the characteristics of node embeddings, where the link state of each link sample could be encoded into the embeddings of nodes that are involved in the neighborhood aggregation of the two nodes in that link sample. In denser graphs, every node could have more opportunities to attend the neighborhood aggregation of other nodes and encode states of more link samples to its embedding, thus learning better node embeddings for link prediction. Lastly, we demonstrate that the insights gained from our research carry important implications in identifying the limitations of existing link prediction methods, which could guide the future development of more robust algorithms.
TransFeat-TPP: An Interpretable Deep Covariate Temporal Point Processes
Jul 23, 2024The classical temporal point process (TPP) constructs an intensity function by taking the occurrence times into account. Nevertheless, occurrence time may not be the only relevant factor, other contextual data, termed covariates, may also impact the event evolution. Incorporating such covariates into the model is beneficial, while distinguishing their relevance to the event dynamics is of great practical significance. In this work, we propose a Transformer-based covariate temporal point process (TransFeat-TPP) model to improve the interpretability of deep covariate-TPPs while maintaining powerful expressiveness. TransFeat-TPP can effectively model complex relationships between events and covariates, and provide enhanced interpretability by discerning the importance of various covariates. Experimental results on synthetic and real datasets demonstrate improved prediction accuracy and consistently interpretable feature importance when compared to existing deep covariate-TPPs.
De-biased Representation Learning for Fairness with Unreliable Labels
Aug 01, 2022


Removing bias while keeping all task-relevant information is challenging for fair representation learning methods since they would yield random or degenerate representations w.r.t. labels when the sensitive attributes correlate with labels. Existing works proposed to inject the label information into the learning procedure to overcome such issues. However, the assumption that the observed labels are clean is not always met. In fact, label bias is acknowledged as the primary source inducing discrimination. In other words, the fair pre-processing methods ignore the discrimination encoded in the labels either during the learning procedure or the evaluation stage. This contradiction puts a question mark on the fairness of the learned representations. To circumvent this issue, we explore the following question: \emph{Can we learn fair representations predictable to latent ideal fair labels given only access to unreliable labels?} In this work, we propose a \textbf{D}e-\textbf{B}iased \textbf{R}epresentation Learning for \textbf{F}airness (DBRF) framework which disentangles the sensitive information from non-sensitive attributes whilst keeping the learned representations predictable to ideal fair labels rather than observed biased ones. We formulate the de-biased learning framework through information-theoretic concepts such as mutual information and information bottleneck. The core concept is that DBRF advocates not to use unreliable labels for supervision when sensitive information benefits the prediction of unreliable labels. Experiment results over both synthetic and real-world data demonstrate that DBRF effectively learns de-biased representations towards ideal labels.
Bias-Tolerant Fair Classification
Jul 07, 2021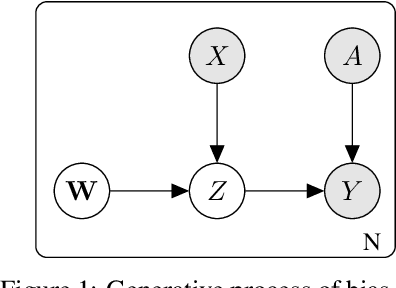


The label bias and selection bias are acknowledged as two reasons in data that will hinder the fairness of machine-learning outcomes. The label bias occurs when the labeling decision is disturbed by sensitive features, while the selection bias occurs when subjective bias exists during the data sampling. Even worse, models trained on such data can inherit or even intensify the discrimination. Most algorithmic fairness approaches perform an empirical risk minimization with predefined fairness constraints, which tends to trade-off accuracy for fairness. However, such methods would achieve the desired fairness level with the sacrifice of the benefits (receive positive outcomes) for individuals affected by the bias. Therefore, we propose a Bias-TolerantFAirRegularizedLoss (B-FARL), which tries to regain the benefits using data affected by label bias and selection bias. B-FARL takes the biased data as input, calls a model that approximates the one trained with fair but latent data, and thus prevents discrimination without constraints required. In addition, we show the effective components by decomposing B-FARL, and we utilize the meta-learning framework for the B-FARL optimization. The experimental results on real-world datasets show that our method is empirically effective in improving fairness towards the direction of true but latent labels.
Utilizing machine learning to prevent water main breaks by understanding pipeline failure drivers
Jun 05, 2020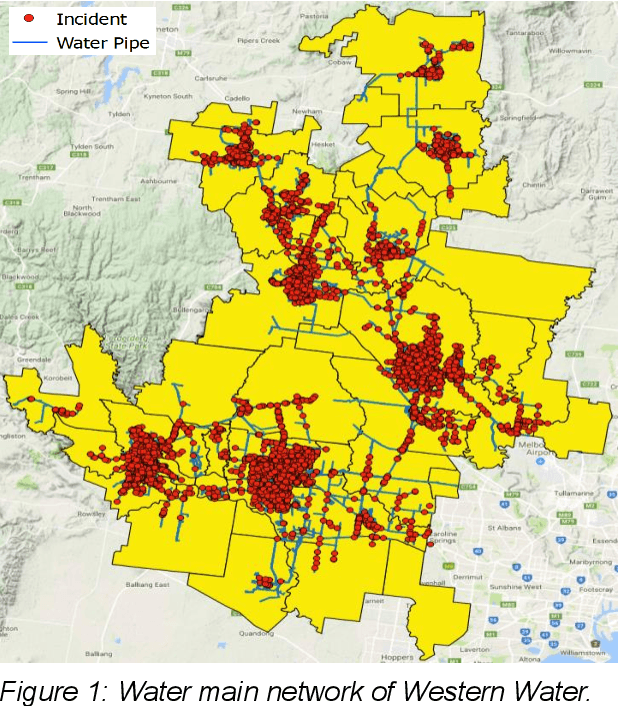
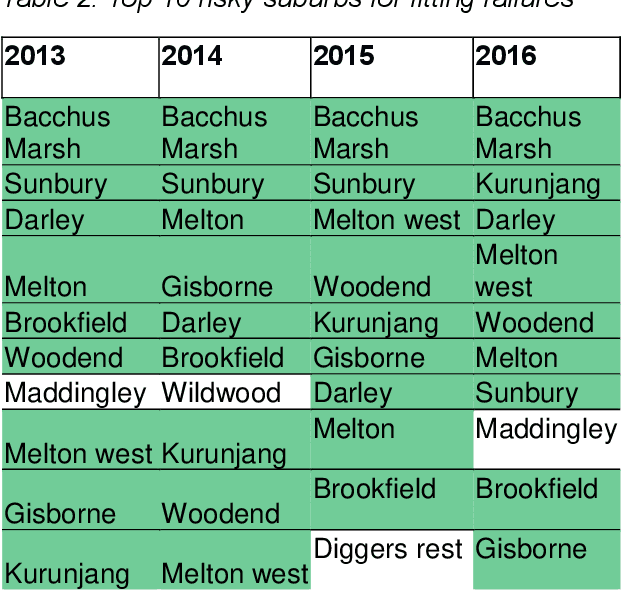
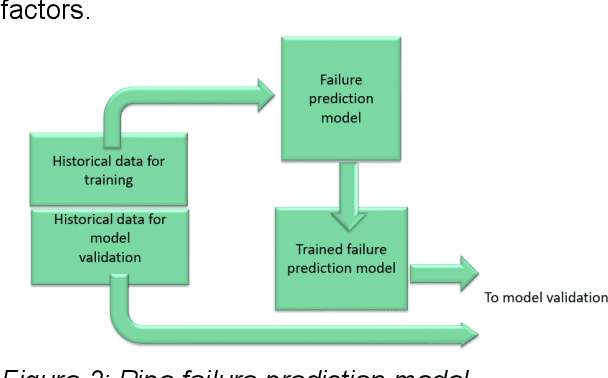
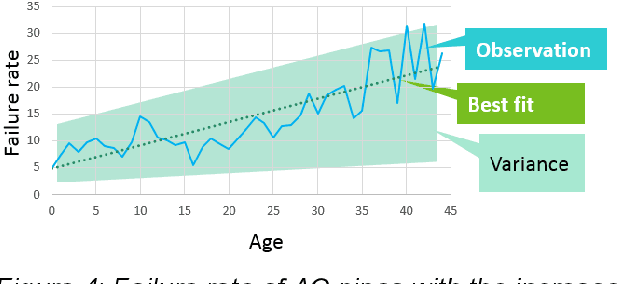
Data61 and Western Water worked collaboratively to apply engineering expertise and Machine Learning tools to find a cost-effective solution to the pipe failure problem in the region west of Melbourne, where on average 400 water main failures occur per year. To achieve this objective, we constructed a detailed picture and understanding of the behaviour of the water pipe network by 1) discovering the underlying drivers of water main breaks, and 2) developing a Machine Learning system to assess and predict the failure likelihood of water main breaking using historical failure records, descriptors of pipes, and other environmental factors. The ensuing results open up an avenue for Western Water to identify the priority of pipe renewals