 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo More Agents Help? Controlled and Protocol-Aligned Evaluation of LLM Agent Workflows
Jun 04, 2026Does adding more agents help an LLM workflow once compared systems share the same benchmark loader, tool access, answer contract, usage accounting, and trajectory logging? We introduce BenchAgent, an evaluation framework that places single-agent, fixed multi-agent (MAS), and evolving MAS workflows under one normalized execution and logging protocol. BenchAgent evaluates these substrate-internal workflows across ten reasoning, coding, and tool-use benchmarks with GPT-4.1, and separately reports a Protocol-Aligned External (PAE) GAIA study of a runtime-generated workflow. Under SI conditions, at most one of six tested MAS exceeds the matched single-agent anchor on benchmark-balanced average accuracy: EvoAgent lies within the Wilson one-run guidance, while the remaining five trail by 2.56-11.29 points and occupy more expensive accuracy-cost trade-offs. On the PAE GAIA snapshot, a Claude-Code-style runtime workflow reaches 66.72% overall and 69.23% on Level 3, more than 20 points above the strongest non-Claude baseline, Jarvis, a fixed MAS.
CoCoPlan: Adaptive Coordination and Communication for Multi-robot Systems in Dynamic and Unknown Environments
Jan 15, 2026Multi-robot systems can greatly enhance efficiency through coordination and collaboration, yet in practice, full-time communication is rarely available and interactions are constrained to close-range exchanges. Existing methods either maintain all-time connectivity, rely on fixed schedules, or adopt pairwise protocols, but none adapt effectively to dynamic spatio-temporal task distributions under limited communication, resulting in suboptimal coordination. To address this gap, we propose CoCoPlan, a unified framework that co-optimizes collaborative task planning and team-wise intermittent communication. Our approach integrates a branch-and-bound architecture that jointly encodes task assignments and communication events, an adaptive objective function that balances task efficiency against communication latency, and a communication event optimization module that strategically determines when, where and how the global connectivity should be re-established. Extensive experiments demonstrate that it outperforms state-of-the-art methods by achieving a 22.4% higher task completion rate, reducing communication overhead by 58.6%, and improving the scalability by supporting up to 100 robots in dynamic environments. Hardware experiments include the complex 2D office environment and large-scale 3D disaster-response scenario.
Mechanism Design for Federated Learning with Non-Monotonic Network Effects
Jan 08, 2026Mechanism design is pivotal to federated learning (FL) for maximizing social welfare by coordinating self-interested clients. Existing mechanisms, however, often overlook the network effects of client participation and the diverse model performance requirements (i.e., generalization error) across applications, leading to suboptimal incentives and social welfare, or even inapplicability in real deployments. To address this gap, we explore incentive mechanism design for FL with network effects and application-specific requirements of model performance. We develop a theoretical model to quantify the impact of network effects on heterogeneous client participation, revealing the non-monotonic nature of such effects. Based on these insights, we propose a Model Trading and Sharing (MoTS) framework, which enables clients to obtain FL models through either participation or purchase. To further address clients' strategic behaviors, we design a Social Welfare maximization with Application-aware and Network effects (SWAN) mechanism, exploiting model customer payments for incentivization. Experimental results on a hardware prototype demonstrate that our SWAN mechanism outperforms existing FL mechanisms, improving social welfare by up to $352.42\%$ and reducing extra incentive costs by $93.07\%$.
SLEI3D: Simultaneous Exploration and Inspection via Heterogeneous Fleets under Limited Communication
Jan 01, 2026Robotic fleets such as unmanned aerial and ground vehicles have been widely used for routine inspections of static environments, where the areas of interest are known and planned in advance. However, in many applications, such areas of interest are unknown and should be identified online during exploration. Thus, this paper considers the problem of simultaneous exploration, inspection of unknown environments and then real-time communication to a mobile ground control station to report the findings. The heterogeneous robots are equipped with different sensors, e.g., long-range lidars for fast exploration and close-range cameras for detailed inspection. Furthermore, global communication is often unavailable in such environments, where the robots can only communicate with each other via ad-hoc wireless networks when they are in close proximity and free of obstruction. This work proposes a novel planning and coordination framework (SLEI3D) that integrates the online strategies for collaborative 3D exploration, adaptive inspection and timely communication (via the intermit-tent or proactive protocols). To account for uncertainties w.r.t. the number and location of features, a multi-layer and multi-rate planning mechanism is developed for inter-and-intra robot subgroups, to actively meet and coordinate their local plans. The proposed framework is validated extensively via high-fidelity simulations of numerous large-scale missions with up to 48 robots and 384 thousand cubic meters. Hardware experiments of 7 robots are also conducted. Project website is available at https://junfengchen-robotics.github.io/SLEI3D/.
FoldAct: Efficient and Stable Context Folding for Long-Horizon Search Agents
Dec 28, 2025Long-horizon reinforcement learning (RL) for large language models faces critical scalability challenges from unbounded context growth, leading to context folding methods that compress interaction history during task execution. However, existing approaches treat summary actions as standard actions, overlooking that summaries fundamentally modify the agent's future observation space, creating a policy-dependent, non-stationary observation distribution that violates core RL assumptions. This introduces three fundamental challenges: (1) gradient dilution where summary tokens receive insufficient training signal, (2) self-conditioning where policy updates change summary distributions, creating a vicious cycle of training collapse, and (3) computational cost from processing unique contexts at each turn. We introduce \textbf{FoldAct}\footnote{https://github.com/SHAO-Jiaqi757/FoldAct}, a framework that explicitly addresses these challenges through three key innovations: separated loss computation for independent gradient signals on summary and action tokens, full context consistency loss to reduce distribution shift, and selective segment training to reduce computational cost. Our method enables stable training of long-horizon search agents with context folding, addressing the non-stationary observation problem while improving training efficiency with 5.19$\times$ speedup.
Automated stereotactic radiosurgery planning using a human-in-the-loop reasoning large language model agent
Dec 23, 2025


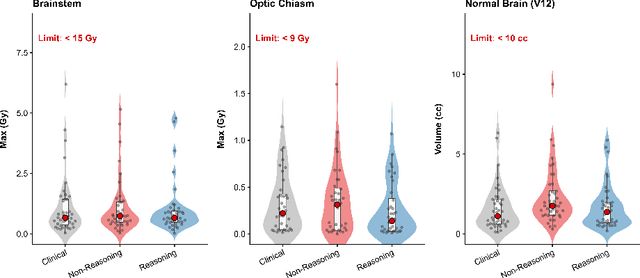
Stereotactic radiosurgery (SRS) demands precise dose shaping around critical structures, yet black-box AI systems have limited clinical adoption due to opacity concerns. We tested whether chain-of-thought reasoning improves agentic planning in a retrospective cohort of 41 patients with brain metastases treated with 18 Gy single-fraction SRS. We developed SAGE (Secure Agent for Generative Dose Expertise), an LLM-based planning agent for automated SRS treatment planning. Two variants generated plans for each case: one using a non-reasoning model, one using a reasoning model. The reasoning variant showed comparable plan dosimetry relative to human planners on primary endpoints (PTV coverage, maximum dose, conformity index, gradient index; all p > 0.21) while reducing cochlear dose below human baselines (p = 0.022). When prompted to improve conformity, the reasoning model demonstrated systematic planning behaviors including prospective constraint verification (457 instances) and trade-off deliberation (609 instances), while the standard model exhibited none of these deliberative processes (0 and 7 instances, respectively). Content analysis revealed that constraint verification and causal explanation concentrated in the reasoning agent. The optimization traces serve as auditable logs, offering a path toward transparent automated planning.
MobileFineTuner: A Unified End-to-End Framework for Fine-Tuning LLMs on Mobile Phones
Dec 09, 2025Mobile phones are the most ubiquitous end devices, generating vast amounts of human-authored data and serving as the primary platform for end-side applications. As high-quality public data for large language models (LLMs) approaches exhaustion, on-device fine-tuning provides an opportunity to leverage private user data while preserving privacy. However, existing approaches are predominantly simulation-based or rely on IoT devices and PCs, leaving commodity mobile phones largely unexplored. A key gap is the absence of an open-source framework that enables practical LLM fine-tuning on mobile phones. We present MobileFineTuner, a unified open-source framework that enables end-to-end LLM fine-tuning directly on commodity mobile phones. MobileFineTuner is designed for efficiency, scalability, and usability, supporting full-parameters fine-tuning (Full-FT) and parameter-efficient fine-tuning (PEFT). To address the memory and energy limitations inherent to mobile phones, we introduce system-level optimizations including parameter sharding, gradient accumulation, and energy-aware computation scheduling. We demonstrate the practicality of MobileFineTuner by fine-tuning GPT-2, Gemma 3, and Qwen 2.5 on real mobile phones. Extensive experiments and ablation studies validate the effectiveness of the proposed optimizations and establish MobileFineTuner as a viable foundation for future research on on-device LLM training.
Do LLM Agents Know How to Ground, Recover, and Assess? A Benchmark for Epistemic Competence in Information-Seeking Agents
Sep 26, 2025Recent work has explored training Large Language Model (LLM) search agents with reinforcement learning (RL) for open-domain question answering (QA). However, most evaluations focus solely on final answer accuracy, overlooking how these agents reason with and act on external evidence. We introduce SeekBench, the first benchmark for evaluating the \textit{epistemic competence} of LLM search agents through step-level analysis of their response traces. SeekBench comprises 190 expert-annotated traces with over 1,800 response steps generated by LLM search agents, each enriched with evidence annotations for granular analysis of whether agents (1) generate reasoning steps grounded in observed evidence, (2) adaptively reformulate searches to recover from low-quality results, and (3) have proper calibration to correctly assess whether the current evidence is sufficient for providing an answer.
Flexible Personalized Split Federated Learning for On-Device Fine-Tuning of Foundation Models
Aug 14, 2025Fine-tuning foundation models is critical for superior performance on personalized downstream tasks, compared to using pre-trained models. Collaborative learning can leverage local clients' datasets for fine-tuning, but limited client data and heterogeneous data distributions hinder effective collaboration. To address the challenge, we propose a flexible personalized federated learning paradigm that enables clients to engage in collaborative learning while maintaining personalized objectives. Given the limited and heterogeneous computational resources available on clients, we introduce \textbf{flexible personalized split federated learning (FlexP-SFL)}. Based on split learning, FlexP-SFL allows each client to train a portion of the model locally while offloading the rest to a server, according to resource constraints. Additionally, we propose an alignment strategy to improve personalized model performance on global data. Experimental results show that FlexP-SFL outperforms baseline models in personalized fine-tuning efficiency and final accuracy.
Adaptive Federated LoRA in Heterogeneous Wireless Networks with Independent Sampling
May 29, 2025Federated LoRA has emerged as a promising technique for efficiently fine-tuning large language models (LLMs) on distributed devices by reducing the number of trainable parameters. However, existing approaches often inadequately overlook the theoretical and practical implications of system and data heterogeneity, thereby failing to optimize the overall training efficiency, particularly in terms of wall-clock time. In this paper, we propose an adaptive federated LoRA strategy with independent client sampling to minimize the convergence wall-clock time of federated fine-tuning under both computation and communication heterogeneity. We first derive a new convergence bound for federated LoRA with arbitrary and independent client sampling, notably without requiring the stringent bounded gradient assumption. Then, we introduce an adaptive bandwidth allocation scheme that accounts for heterogeneous client resources and system bandwidth constraints. Based on the derived theory, we formulate and solve a non-convex optimization problem to jointly determine the LoRA sketching ratios and sampling probabilities, aiming to minimize wall-clock convergence time. An efficient and low-complexity algorithm is developed to approximate the solution. Finally, extensive experiments demonstrate that our approach significantly reduces wall-clock training time compared to state-of-the-art methods across various models and datasets.