 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscriminative-Generative Target Speaker Extraction with Decoder-Only Language Models
Jan 09, 2026Target speaker extraction (TSE) aims to recover the speech signal of a desired speaker from a mixed audio recording, given a short enrollment utterance. Most existing TSE approaches are based on discriminative modeling paradigms. Although effective at suppressing interfering speakers, these methods often struggle to produce speech with high perceptual quality and naturalness. To address this limitation, we first propose LauraTSE, a generative TSE model built upon an auto-regressive decoder-only language model. However, purely generative approaches may suffer from hallucinations, content drift, and limited controllability, which may undermine their reliability in complex acoustic scenarios. To overcome these challenges, we further introduce a discriminative-generative TSE framework. In this framework, a discriminative front-end is employed to robustly extract the target speaker's speech, yielding stable and controllable intermediate representations. A generative back-end then operates in the neural audio codec representation space to reconstruct fine-grained speech details and enhance perceptual quality. This two-stage design effectively combines the robustness and controllability of discriminative models with the superior naturalness and quality enhancement capabilities of generative models. Moreover, we systematically investigate collaborative training strategies for the proposed framework, including freezing or fine-tuning the front-end, incorporating an auxiliary SI-SDR loss, and exploring both auto-regressive and non-auto-regressive inference mechanisms. Experimental results demonstrate that the proposed framework achieves a more favorable trade-off among speech quality, intelligibility, and speaker consistency.
SEF-MK: Speaker-Embedding-Free Voice Anonymization through Multi-k-means Quantization
Aug 09, 2025Voice anonymization protects speaker privacy by concealing identity while preserving linguistic and paralinguistic content. Self-supervised learning (SSL) representations encode linguistic features but preserve speaker traits. We propose a novel speaker-embedding-free framework called SEF-MK. Instead of using a single k-means model trained on the entire dataset, SEF-MK anonymizes SSL representations for each utterance by randomly selecting one of multiple k-means models, each trained on a different subset of speakers. We explore this approach from both attacker and user perspectives. Extensive experiments show that, compared to a single k-means model, SEF-MK with multiple k-means models better preserves linguistic and emotional content from the user's viewpoint. However, from the attacker's perspective, utilizing multiple k-means models boosts the effectiveness of privacy attacks. These insights can aid users in designing voice anonymization systems to mitigate attacker threats.
Diarization-Aware Multi-Speaker Automatic Speech Recognition via Large Language Models
Jun 06, 2025Multi-speaker automatic speech recognition (MS-ASR) faces significant challenges in transcribing overlapped speech, a task critical for applications like meeting transcription and conversational analysis. While serialized output training (SOT)-style methods serve as common solutions, they often discard absolute timing information, limiting their utility in time-sensitive scenarios. Leveraging recent advances in large language models (LLMs) for conversational audio processing, we propose a novel diarization-aware multi-speaker ASR system that integrates speaker diarization with LLM-based transcription. Our framework processes structured diarization inputs alongside frame-level speaker and semantic embeddings, enabling the LLM to generate segment-level transcriptions. Experiments demonstrate that the system achieves robust performance in multilingual dyadic conversations and excels in complex, high-overlap multi-speaker meeting scenarios. This work highlights the potential of LLMs as unified back-ends for joint speaker-aware segmentation and transcription.
LauraTSE: Target Speaker Extraction using Auto-Regressive Decoder-Only Language Models
Apr 10, 2025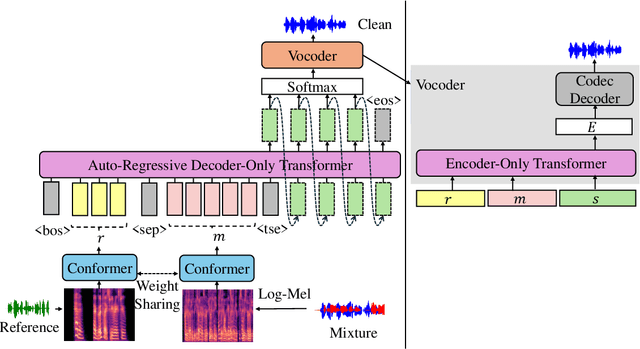

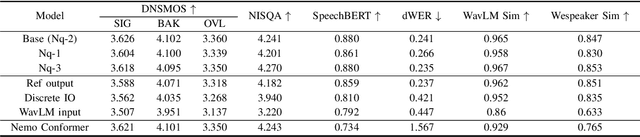
We propose LauraTSE, an Auto-Regressive Decoder-Only Language Model for Target Speaker Extraction (TSE) based on the LauraGPT backbone. It employs a small-scale auto-regressive decoder-only language model which takes the continuous representations for both the mixture and the reference speeches and produces the first few layers of the target speech's discrete codec representations. In addition, a one-step encoder-only language model reconstructs the sum of the predicted codec embeddings using both the mixture and the reference information. Our approach achieves superior or comparable performance to existing generative and discriminative TSE models. To the best of our knowledge, LauraTSE is the first single-task TSE model to leverage an auto-regressive decoder-only language model as the backbone.
TSELM: Target Speaker Extraction using Discrete Tokens and Language Models
Sep 12, 2024We propose TSELM, a novel target speaker extraction network that leverages discrete tokens and language models. TSELM utilizes multiple discretized layers from WavLM as input tokens and incorporates cross-attention mechanisms to integrate target speaker information. Language models are employed to capture the sequence dependencies, while a scalable HiFi-GAN is used to reconstruct the audio from the tokens. By applying a cross-entropy loss, TSELM models the probability distribution of output tokens, thus converting the complex regression problem of audio generation into a classification task. Experimental results show that TSELM achieves excellent results in speech quality and comparable results in speech intelligibility.
Demo: FedCampus: A Real-world Privacy-preserving Mobile Application for Smart Campus via Federated Learning & Analytics
Aug 31, 2024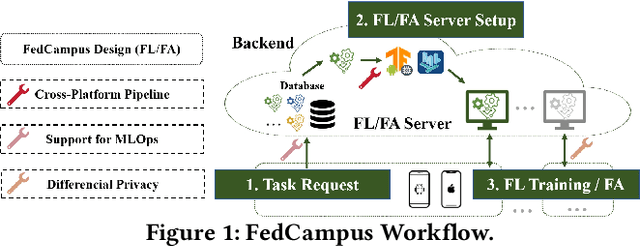

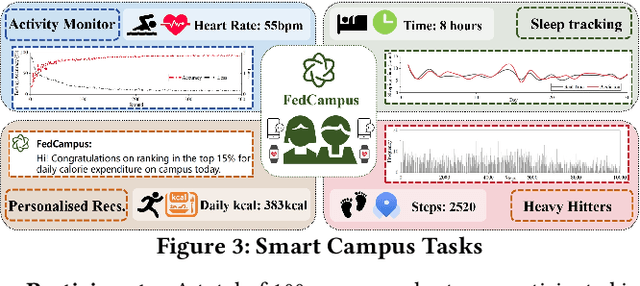
In this demo, we introduce FedCampus, a privacy-preserving mobile application for smart \underline{campus} with \underline{fed}erated learning (FL) and federated analytics (FA). FedCampus enables cross-platform on-device FL/FA for both iOS and Android, supporting continuously models and algorithms deployment (MLOps). Our app integrates privacy-preserving processed data via differential privacy (DP) from smartwatches, where the processed parameters are used for FL/FA through the FedCampus backend platform. We distributed 100 smartwatches to volunteers at Duke Kunshan University and have successfully completed a series of smart campus tasks featuring capabilities such as sleep tracking, physical activity monitoring, personalized recommendations, and heavy hitters. Our project is opensourced at https://github.com/FedCampus/FedCampus_Flutter. See the FedCampus video at https://youtu.be/k5iu46IjA38.
FedKit: Enabling Cross-Platform Federated Learning for Android and iOS
Feb 16, 2024We present FedKit, a federated learning (FL) system tailored for cross-platform FL research on Android and iOS devices. FedKit pipelines cross-platform FL development by enabling model conversion, hardware-accelerated training, and cross-platform model aggregation. Our FL workflow supports flexible machine learning operations (MLOps) in production, facilitating continuous model delivery and training. We have deployed FedKit in a real-world use case for health data analysis on university campuses, demonstrating its effectiveness. FedKit is open-source at https://github.com/FedCampus/FedKit.