 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscriminative-Generative Target Speaker Extraction with Decoder-Only Language Models
Jan 09, 2026Target speaker extraction (TSE) aims to recover the speech signal of a desired speaker from a mixed audio recording, given a short enrollment utterance. Most existing TSE approaches are based on discriminative modeling paradigms. Although effective at suppressing interfering speakers, these methods often struggle to produce speech with high perceptual quality and naturalness. To address this limitation, we first propose LauraTSE, a generative TSE model built upon an auto-regressive decoder-only language model. However, purely generative approaches may suffer from hallucinations, content drift, and limited controllability, which may undermine their reliability in complex acoustic scenarios. To overcome these challenges, we further introduce a discriminative-generative TSE framework. In this framework, a discriminative front-end is employed to robustly extract the target speaker's speech, yielding stable and controllable intermediate representations. A generative back-end then operates in the neural audio codec representation space to reconstruct fine-grained speech details and enhance perceptual quality. This two-stage design effectively combines the robustness and controllability of discriminative models with the superior naturalness and quality enhancement capabilities of generative models. Moreover, we systematically investigate collaborative training strategies for the proposed framework, including freezing or fine-tuning the front-end, incorporating an auxiliary SI-SDR loss, and exploring both auto-regressive and non-auto-regressive inference mechanisms. Experimental results demonstrate that the proposed framework achieves a more favorable trade-off among speech quality, intelligibility, and speaker consistency.
LauraTSE: Target Speaker Extraction using Auto-Regressive Decoder-Only Language Models
Apr 10, 2025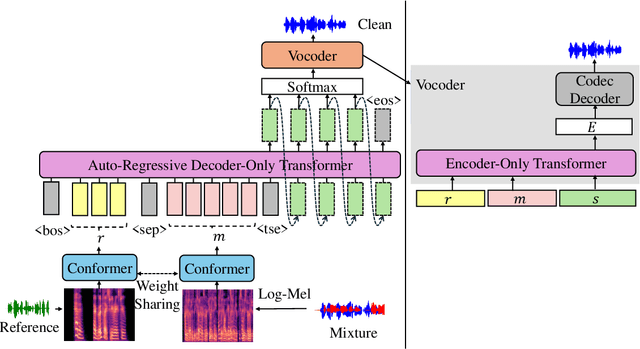

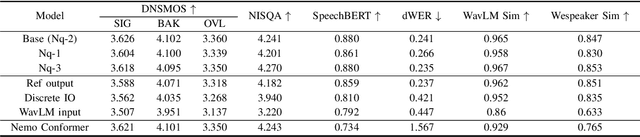
We propose LauraTSE, an Auto-Regressive Decoder-Only Language Model for Target Speaker Extraction (TSE) based on the LauraGPT backbone. It employs a small-scale auto-regressive decoder-only language model which takes the continuous representations for both the mixture and the reference speeches and produces the first few layers of the target speech's discrete codec representations. In addition, a one-step encoder-only language model reconstructs the sum of the predicted codec embeddings using both the mixture and the reference information. Our approach achieves superior or comparable performance to existing generative and discriminative TSE models. To the best of our knowledge, LauraTSE is the first single-task TSE model to leverage an auto-regressive decoder-only language model as the backbone.
Universal Speaker Embedding Free Target Speaker Extraction and Personal Voice Activity Detection
Jan 07, 2025



Determining 'who spoke what and when' remains challenging in real-world applications. In typical scenarios, Speaker Diarization (SD) is employed to address the problem of 'who spoke when,' while Target Speaker Extraction (TSE) or Target Speaker Automatic Speech Recognition (TSASR) techniques are utilized to resolve the issue of 'who spoke what.' Although some works have achieved promising results by combining SD and TSE systems, inconsistencies remain between SD and TSE regarding both output inconsistency and scenario mismatch. To address these limitations, we propose a Universal Speaker Embedding Free Target Speaker Extraction and Personal Voice Activity Detection (USEF-TP) model that jointly performs TSE and Personal Voice Activity Detection (PVAD). USEF-TP leverages frame-level features obtained through a cross-attention mechanism as speaker-related features instead of using speaker embeddings as in traditional approaches. Additionally, a multi-task learning algorithm with a scenario-aware differentiated loss function is applied to ensure robust performance across various levels of speaker overlap. The experimental results show that our proposed USEF-TP model achieves superior performance in TSE and PVAD tasks on the LibriMix and SparseLibriMix datasets.
TSELM: Target Speaker Extraction using Discrete Tokens and Language Models
Sep 12, 2024We propose TSELM, a novel target speaker extraction network that leverages discrete tokens and language models. TSELM utilizes multiple discretized layers from WavLM as input tokens and incorporates cross-attention mechanisms to integrate target speaker information. Language models are employed to capture the sequence dependencies, while a scalable HiFi-GAN is used to reconstruct the audio from the tokens. By applying a cross-entropy loss, TSELM models the probability distribution of output tokens, thus converting the complex regression problem of audio generation into a classification task. Experimental results show that TSELM achieves excellent results in speech quality and comparable results in speech intelligibility.
USEF-TSE: Universal Speaker Embedding Free Target Speaker Extraction
Sep 04, 2024



Target speaker extraction aims to isolate the voice of a specific speaker from mixed speech. Traditionally, this process has relied on extracting a speaker embedding from a reference speech, necessitating a speaker recognition model. However, identifying an appropriate speaker recognition model can be challenging, and using the target speaker embedding as reference information may not be optimal for target speaker extraction tasks. This paper introduces a Universal Speaker Embedding-Free Target Speaker Extraction (USEF-TSE) framework that operates without relying on speaker embeddings. USEF-TSE utilizes a multi-head cross-attention mechanism as a frame-level target speaker feature extractor. This innovative approach allows mainstream speaker extraction solutions to bypass the dependency on speaker recognition models and to fully leverage the information available in the enrollment speech, including speaker characteristics and contextual details. Additionally, USEF-TSE can seamlessly integrate with any time-domain or time-frequency domain speech separation model to achieve effective speaker extraction. Experimental results show that our proposed method achieves state-of-the-art (SOTA) performance in terms of Scale-Invariant Signal-to-Distortion Ratio (SI-SDR) on the WSJ0-2mix, WHAM!, and WHAMR! datasets, which are standard benchmarks for monaural anechoic, noisy and noisy-reverberant two-speaker speech separation and speaker extraction.
Simultaneous Speech Extraction for Multiple Target Speakers under the Meeting Scenarios(V1)
Jun 17, 2022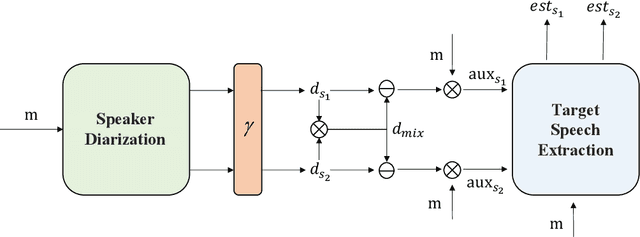
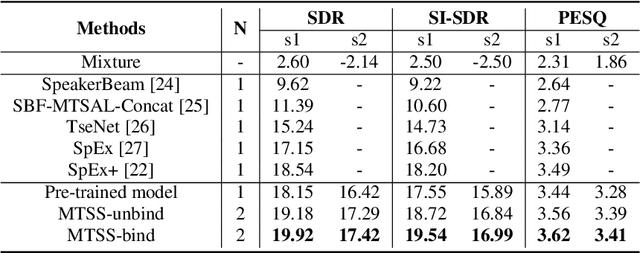
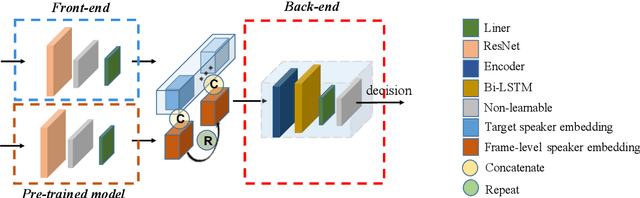
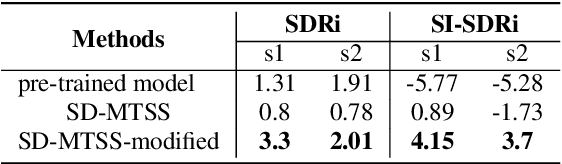
Recently, the target speech separation or extraction techniques under the meeting scenario have become a hot research trend. We propose a speaker diarization aware multiple target speech separation system (SD-MTSS) to simultaneously extract the voice of each speaker from the mixed speech, rather than requiring a succession of independent processes as presented in previous solutions. SD-MTSS consists of a speaker diarization (SD) module and a multiple target speech separation (MTSS) module. The former one infers the target speaker voice activity detection (TSVAD) states of the mixture, as well as gets different speakers' single-talker audio segments as the reference speech. The latter one employs both the mixed audio and reference speech as inputs, and then it generates an estimated mask. By exploiting the TSVAD decision and the estimated mask, our SD-MTSS model can extract the speech of each speaker concurrently in a conversion recording without additional enrollment audio in advance.Experimental results show that our MTSS model outperforms our baselines with a large margin, achieving 1.38dB SDR, 1.34dB SI-SNR, and 0.13 PESQ improvements over the state-of-the-art SpEx+ baseline on the WSJ0-2mix-extr dataset, respectively. The SD-MTSS system makes a significant improvement than the baseline on the Alimeeting dataset as well.