 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Speech Extraction for Multiple Target Speakers under the Meeting Scenarios(V1)
Jun 17, 2022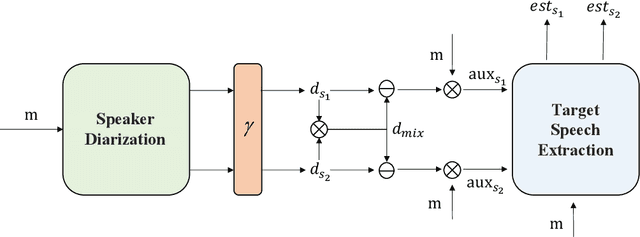
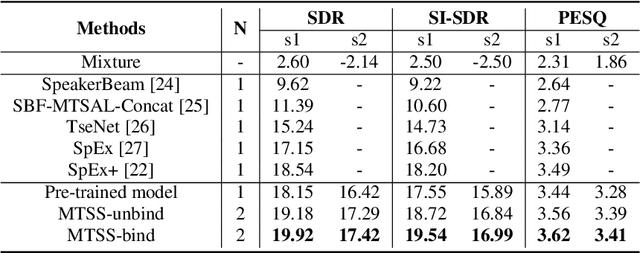
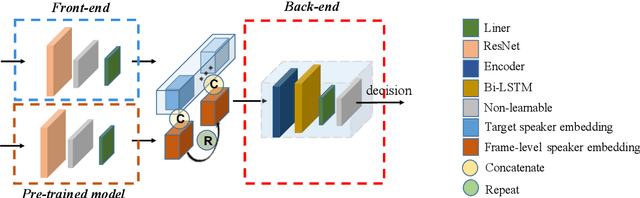
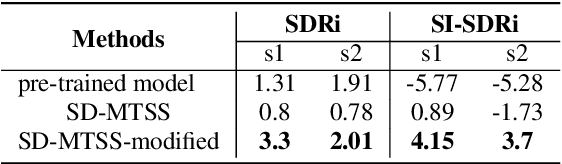
Recently, the target speech separation or extraction techniques under the meeting scenario have become a hot research trend. We propose a speaker diarization aware multiple target speech separation system (SD-MTSS) to simultaneously extract the voice of each speaker from the mixed speech, rather than requiring a succession of independent processes as presented in previous solutions. SD-MTSS consists of a speaker diarization (SD) module and a multiple target speech separation (MTSS) module. The former one infers the target speaker voice activity detection (TSVAD) states of the mixture, as well as gets different speakers' single-talker audio segments as the reference speech. The latter one employs both the mixed audio and reference speech as inputs, and then it generates an estimated mask. By exploiting the TSVAD decision and the estimated mask, our SD-MTSS model can extract the speech of each speaker concurrently in a conversion recording without additional enrollment audio in advance.Experimental results show that our MTSS model outperforms our baselines with a large margin, achieving 1.38dB SDR, 1.34dB SI-SNR, and 0.13 PESQ improvements over the state-of-the-art SpEx+ baseline on the WSJ0-2mix-extr dataset, respectively. The SD-MTSS system makes a significant improvement than the baseline on the Alimeeting dataset as well.
Lightweight Dual-channel Target Speaker Separation for Mobile Voice Communication
Jun 05, 2021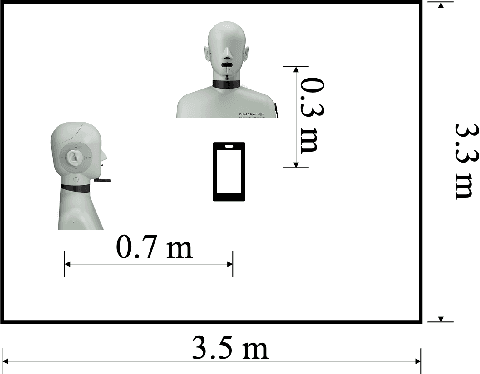
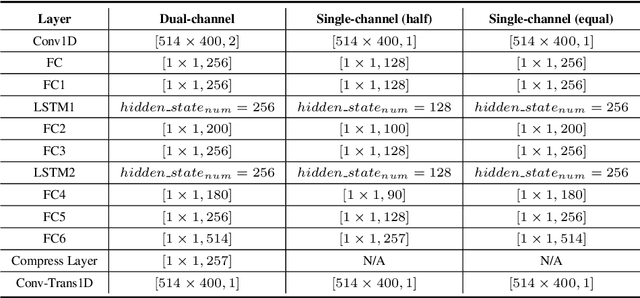
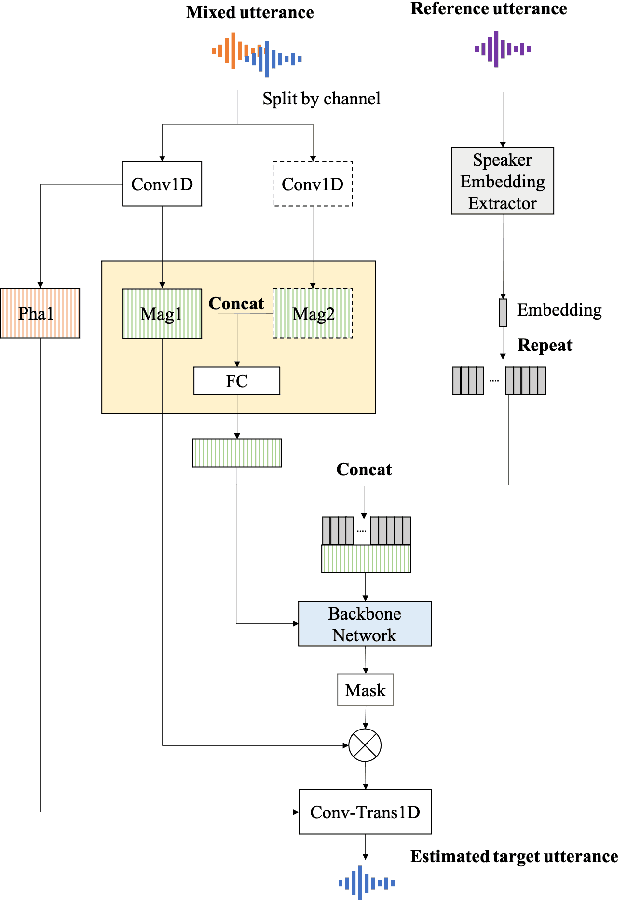
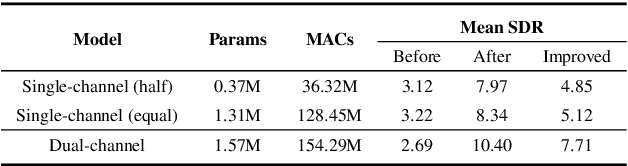
Nowadays, there is a strong need to deploy the target speaker separation (TSS) model on mobile devices with a limitation of the model size and computational complexity. To better perform TSS for mobile voice communication, we first make a dual-channel dataset based on a specific scenario, LibriPhone. Specifically, to better mimic the real-case scenario, instead of simulating from the single-channel dataset, LibriPhone is made by simultaneously replaying pairs of utterances from LibriSpeech by two professional artificial heads and recording by two built-in microphones of the mobile. Then, we propose a lightweight time-frequency domain separation model, LSTM-Former, which is based on the LSTM framework with source-to-noise ratio (SI-SNR) loss. For the experiments on Libri-Phone, we explore the dual-channel LSTMFormer model and a single-channel version by a random single channel of Libri-Phone. Experimental result shows that the dual-channel LSTM-Former outperforms the single-channel LSTMFormer with relative 25% improvement. This work provides a feasible solution for the TSS task on mobile devices, playing back and recording multiple data sources in real application scenarios for getting dual-channel real data can assist the lightweight model to achieve higher performance.