 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Dual-channel Target Speaker Separation for Mobile Voice Communication
Jun 05, 2021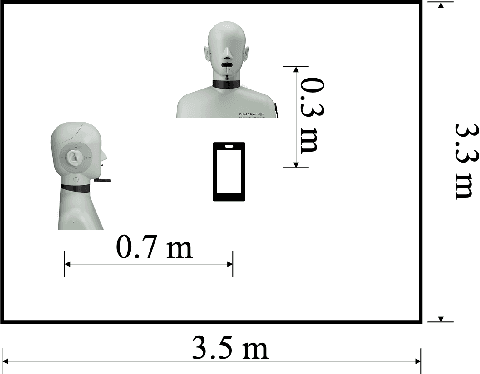
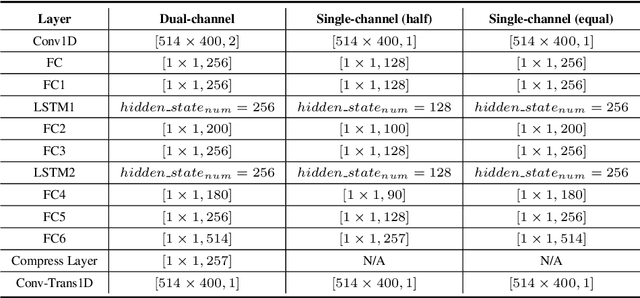
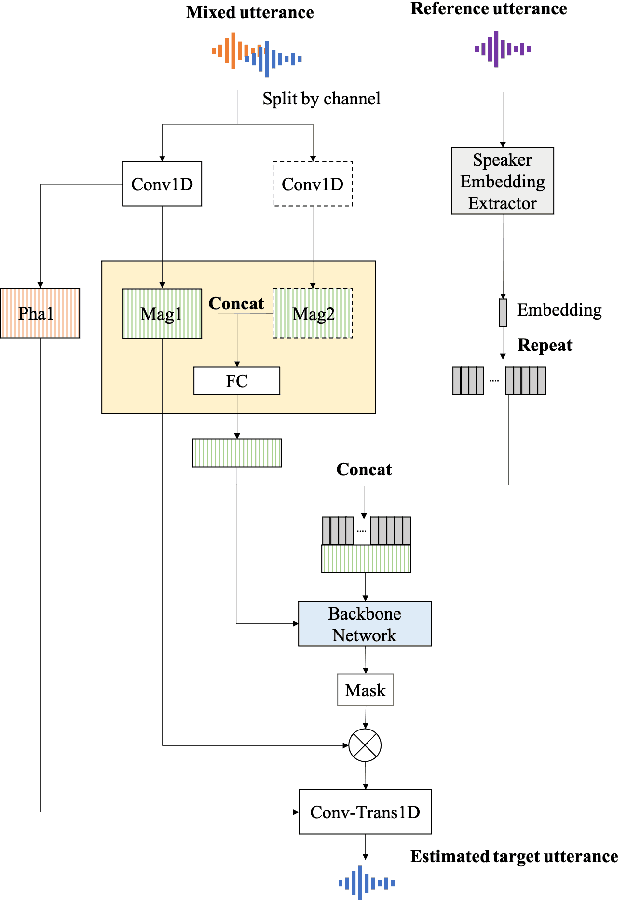
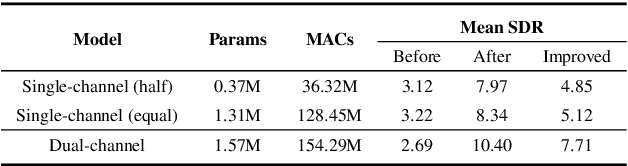
Nowadays, there is a strong need to deploy the target speaker separation (TSS) model on mobile devices with a limitation of the model size and computational complexity. To better perform TSS for mobile voice communication, we first make a dual-channel dataset based on a specific scenario, LibriPhone. Specifically, to better mimic the real-case scenario, instead of simulating from the single-channel dataset, LibriPhone is made by simultaneously replaying pairs of utterances from LibriSpeech by two professional artificial heads and recording by two built-in microphones of the mobile. Then, we propose a lightweight time-frequency domain separation model, LSTM-Former, which is based on the LSTM framework with source-to-noise ratio (SI-SNR) loss. For the experiments on Libri-Phone, we explore the dual-channel LSTMFormer model and a single-channel version by a random single channel of Libri-Phone. Experimental result shows that the dual-channel LSTM-Former outperforms the single-channel LSTMFormer with relative 25% improvement. This work provides a feasible solution for the TSS task on mobile devices, playing back and recording multiple data sources in real application scenarios for getting dual-channel real data can assist the lightweight model to achieve higher performance.