 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum-activated neural reservoirs on-chip open up large hardware security models for resilient authentication
Mar 21, 2024



Quantum artificial intelligence is a frontier of artificial intelligence research, pioneering quantum AI-powered circuits to address problems beyond the reach of deep learning with classical architectures. This work implements a large-scale quantum-activated recurrent neural network possessing more than 3 trillion hardware nodes/cm$^2$, originating from repeatable atomic-scale nucleation dynamics in an amorphous material integrated on-chip, controlled with 0.07 nW electric power per readout channel. Compared to the best-performing reservoirs currently reported, this implementation increases the scale of the network by two orders of magnitude and reduces the power consumption by six, reaching power efficiencies in the range of the human brain, dissipating 0.2 nW/neuron. When interrogated by a classical input, the chip implements a large-scale hardware security model, enabling dictionary-free authentication secure against statistical inference attacks, including AI's present and future development, even for an adversary with a copy of all the classical components available. Experimental tests report 99.6% reliability, 100% user authentication accuracy, and an ideal 50% key uniqueness. Due to its quantum nature, the chip supports a bit density per feature size area three times higher than the best technology available, with the capacity to store more than $2^{1104}$ keys in a footprint of 1 cm$^2$. Such a quantum-powered platform could help counteract the emerging form of warfare led by the cybercrime industry in breaching authentication to target small to large-scale facilities, from private users to intelligent energy grids.
Lightweight Dual-channel Target Speaker Separation for Mobile Voice Communication
Jun 05, 2021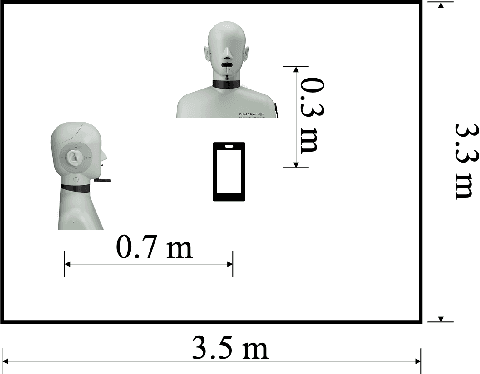
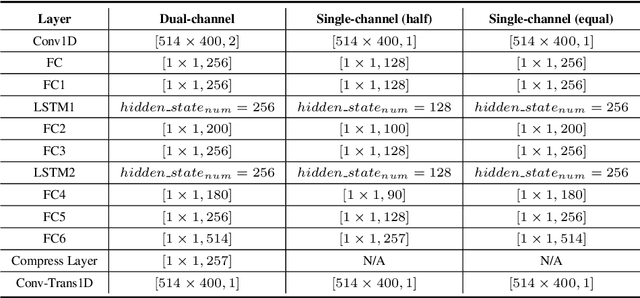
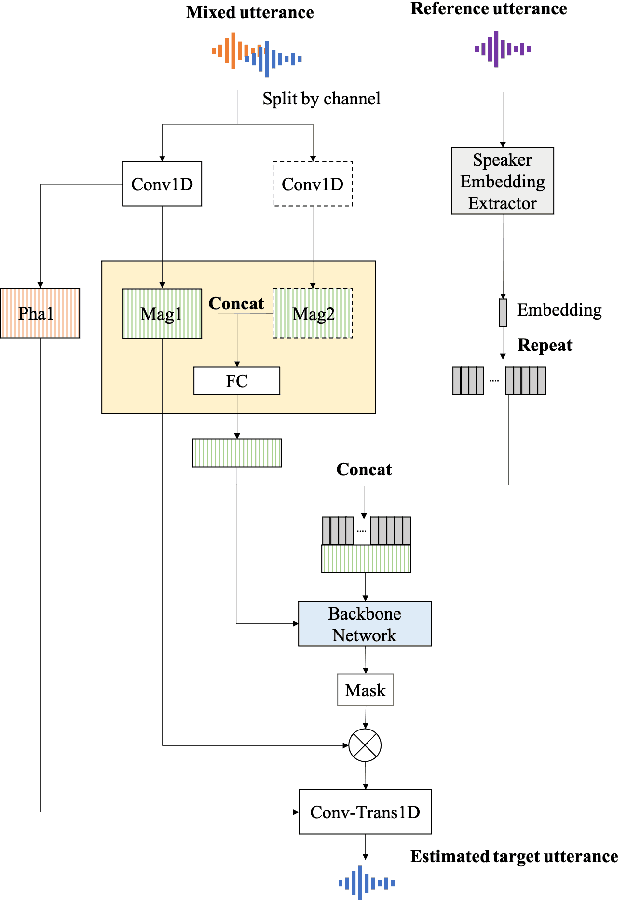
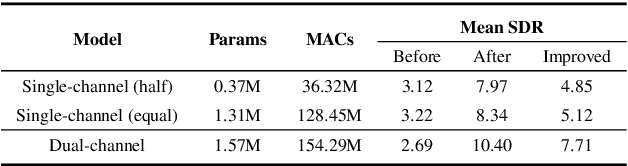
Nowadays, there is a strong need to deploy the target speaker separation (TSS) model on mobile devices with a limitation of the model size and computational complexity. To better perform TSS for mobile voice communication, we first make a dual-channel dataset based on a specific scenario, LibriPhone. Specifically, to better mimic the real-case scenario, instead of simulating from the single-channel dataset, LibriPhone is made by simultaneously replaying pairs of utterances from LibriSpeech by two professional artificial heads and recording by two built-in microphones of the mobile. Then, we propose a lightweight time-frequency domain separation model, LSTM-Former, which is based on the LSTM framework with source-to-noise ratio (SI-SNR) loss. For the experiments on Libri-Phone, we explore the dual-channel LSTMFormer model and a single-channel version by a random single channel of Libri-Phone. Experimental result shows that the dual-channel LSTM-Former outperforms the single-channel LSTMFormer with relative 25% improvement. This work provides a feasible solution for the TSS task on mobile devices, playing back and recording multiple data sources in real application scenarios for getting dual-channel real data can assist the lightweight model to achieve higher performance.
A Coupled Random Projection Approach to Large-Scale Canonical Polyadic Decomposition
May 10, 2021
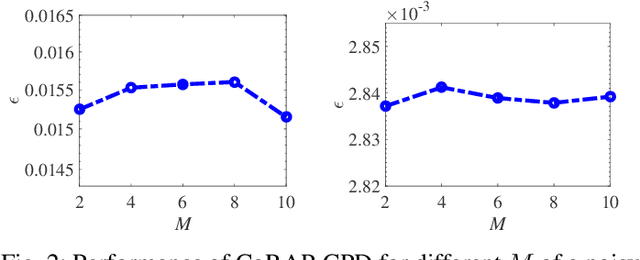
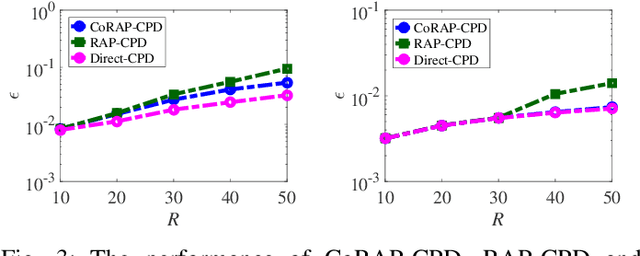
We propose a novel algorithm for the computation of canonical polyadic decomposition (CPD) of large-scale tensors. The proposed algorithm generalizes the random projection (RAP) technique, which is often used to compute large-scale decompositions, from one single projection to multiple but coupled random projections (CoRAP). The proposed CoRAP technique yields a set of tensors that together admits a coupled CPD (C-CPD) and a C-CPD algorithm is then used to jointly decompose these tensors. The results of C-CPD are finally fused to obtain factor matrices of the original large-scale data tensor. As more data samples are jointly exploited via C-CPD, the proposed CoRAP based CPD is more accurate than RAP based CPD. Experiments are provided to illustrate the performance of the proposed approach.
Neural Architecture Search on Acoustic Scene Classification
Dec 30, 2019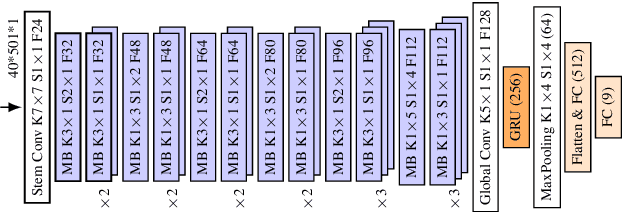
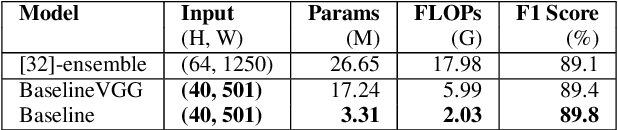
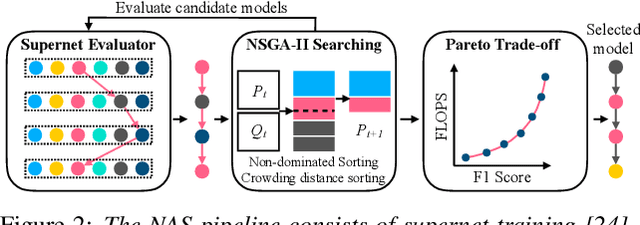
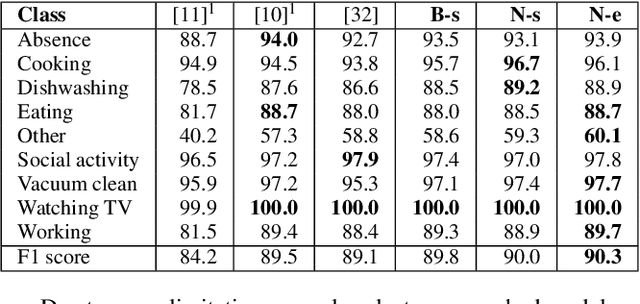
Convolutional neural networks are widely adopted in Acoustic Scene Classification (ASC) tasks, but they generally carry a heavy computational burden. In this work, we propose a lightweight yet high-performing baseline network inspired by MobileNetV2, which replaces square convolutional kernels with unidirectional ones to extract features alternately in temporal and frequency dimensions. Furthermore, we explore a dynamic architecture space built on the basis of the proposed baseline with the recent Neural Architecture Search (NAS) paradigm, which first trains a supernet that incorporates all candidate networks and then applies a well-known evolutionary algorithm NSGA-II to discover more efficient networks with higher accuracy and lower computational cost. Experimental results demonstrate that our searched network is competent in ASC tasks, which achieves 90.3% F1-score on the DCASE2018 task 5 evaluation set, marking a new state-of-the-art performance while saving 25% of FLOPs compared to our baseline network.
Investigating Generative Adversarial Networks based Speech Dereverberation for Robust Speech Recognition
Oct 25, 2018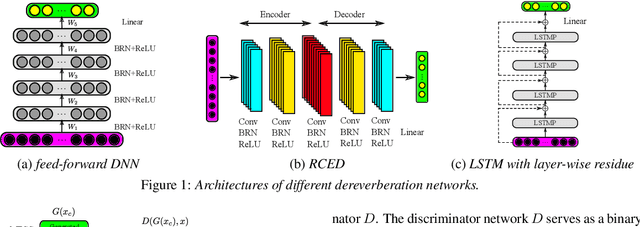
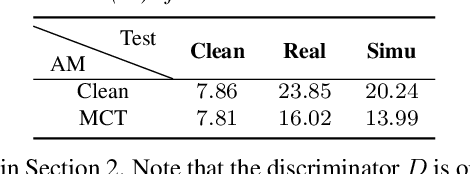
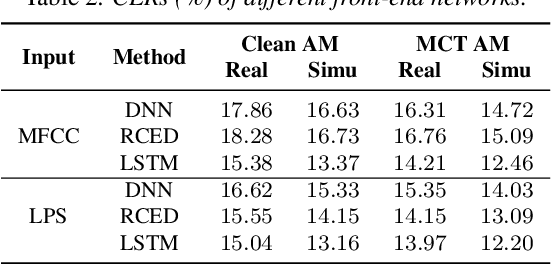
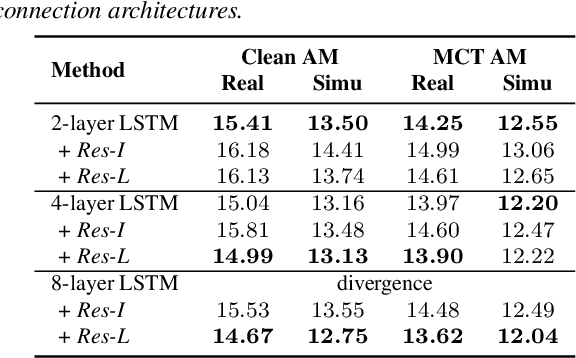
We investigate the use of generative adversarial networks (GANs) in speech dereverberation for robust speech recognition. GANs have been recently studied for speech enhancement to remove additive noises, but there still lacks of a work to examine their ability in speech dereverberation and the advantages of using GANs have not been fully established. In this paper, we provide deep investigations in the use of GAN-based dereverberation front-end in ASR. First, we study the effectiveness of different dereverberation networks (the generator in GAN) and find that LSTM leads a significant improvement as compared with feed-forward DNN and CNN in our dataset. Second, further adding residual connections in the deep LSTMs can boost the performance as well. Finally, we find that, for the success of GAN, it is important to update the generator and the discriminator using the same mini-batch data during training. Moreover, using reverberant spectrogram as a condition to discriminator, as suggested in previous studies, may degrade the performance. In summary, our GAN-based dereverberation front-end achieves 14%-19% relative CER reduction as compared to the baseline DNN dereverberation network when tested on a strong multi-condition training acoustic model.
* Interspeech 2018