 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Speech Extraction for Multiple Target Speakers under the Meeting Scenarios(V1)
Paper and Code
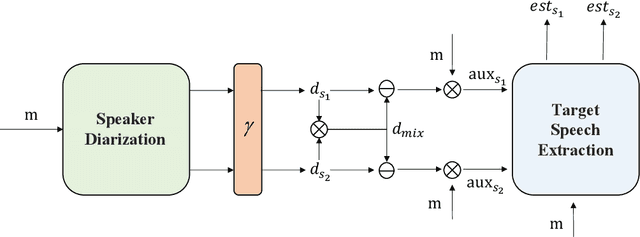
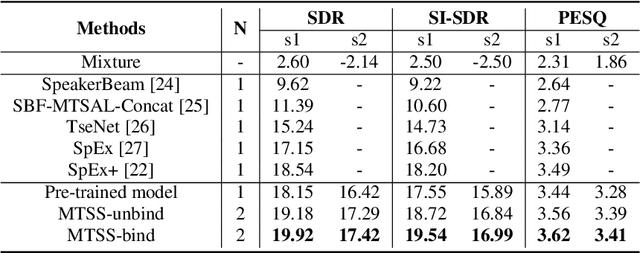
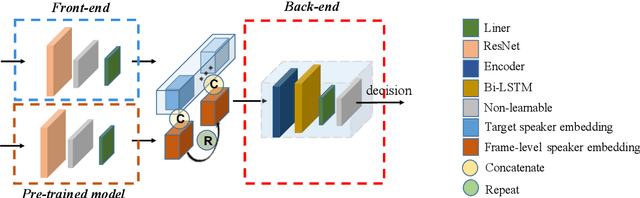
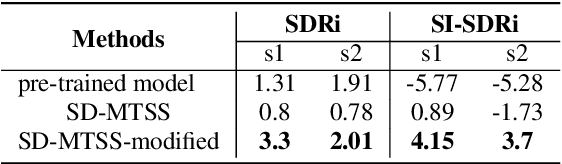
Recently, the target speech separation or extraction techniques under the meeting scenario have become a hot research trend. We propose a speaker diarization aware multiple target speech separation system (SD-MTSS) to simultaneously extract the voice of each speaker from the mixed speech, rather than requiring a succession of independent processes as presented in previous solutions. SD-MTSS consists of a speaker diarization (SD) module and a multiple target speech separation (MTSS) module. The former one infers the target speaker voice activity detection (TSVAD) states of the mixture, as well as gets different speakers' single-talker audio segments as the reference speech. The latter one employs both the mixed audio and reference speech as inputs, and then it generates an estimated mask. By exploiting the TSVAD decision and the estimated mask, our SD-MTSS model can extract the speech of each speaker concurrently in a conversion recording without additional enrollment audio in advance.Experimental results show that our MTSS model outperforms our baselines with a large margin, achieving 1.38dB SDR, 1.34dB SI-SNR, and 0.13 PESQ improvements over the state-of-the-art SpEx+ baseline on the WSJ0-2mix-extr dataset, respectively. The SD-MTSS system makes a significant improvement than the baseline on the Alimeeting dataset as well.