 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoE: Collaborative Entropy for Uncertainty Quantification in Agentic Multi-LLM Systems
Mar 30, 2026Uncertainty estimation in multi-LLM systems remains largely single-model-centric: existing methods quantify uncertainty within each model but do not adequately capture semantic disagreement across models. To address this gap, we propose Collaborative Entropy (CoE), a unified information-theoretic metric for semantic uncertainty in multi-LLM collaboration. CoE is defined on a shared semantic cluster space and combines two components: intra-model semantic entropy and inter-model divergence to the ensemble mean. CoE is not a weighted ensemble predictor; it is a system-level uncertainty measure that characterizes collaborative confidence and disagreement. We analyze several core properties of CoE, including non-negativity, zero-value certainty under perfect semantic consensus, and the behavior of CoE when individual models collapse to delta distributions. These results clarify when reducing per-model uncertainty is sufficient and when residual inter-model disagreement remains. We also present a simple CoE-guided, training-free post-hoc coordination heuristic as a practical application of the metric. Experiments on \textit{TriviaQA} and \textit{SQuAD} with LLaMA-3.1-8B-Instruct, Qwen-2.5-7B-Instruct, and Mistral-7B-Instruct show that CoE provides stronger uncertainty estimation than standard entropy- and divergence-based baselines, with gains becoming larger as additional heterogeneous models are introduced. Overall, CoE offers a useful uncertainty-aware perspective on multi-LLM collaboration.
Tackling Privacy Heterogeneity in Differentially Private Federated Learning
Feb 26, 2026Differentially private federated learning (DP-FL) enables clients to collaboratively train machine learning models while preserving the privacy of their local data. However, most existing DP-FL approaches assume that all clients share a uniform privacy budget, an assumption that does not hold in real-world scenarios where privacy requirements vary widely. This privacy heterogeneity poses a significant challenge: conventional client selection strategies, which typically rely on data quantity, cannot distinguish between clients providing high-quality updates and those introducing substantial noise due to strict privacy constraints. To address this gap, we present the first systematic study of privacy-aware client selection in DP-FL. We establish a theoretical foundation by deriving a convergence analysis that quantifies the impact of privacy heterogeneity on training error. Building on this analysis, we propose a privacy-aware client selection strategy, formulated as a convex optimization problem, that adaptively adjusts selection probabilities to minimize training error. Extensive experiments on benchmark datasets demonstrate that our approach achieves up to a 10% improvement in test accuracy on CIFAR-10 compared to existing baselines under heterogeneous privacy budgets. These results highlight the importance of incorporating privacy heterogeneity into client selection for practical and effective federated learning.
JSAM: Privacy Straggler-Resilient Joint Client Selection and Incentive Mechanism Design in Differentially Private Federated Learning
Feb 25, 2026Differentially private federated learning faces a fundamental tension: privacy protection mechanisms that safeguard client data simultaneously create quantifiable privacy costs that discourage participation, undermining the collaborative training process. Existing incentive mechanisms rely on unbiased client selection, forcing servers to compensate even the most privacy-sensitive clients ("privacy stragglers"), leading to systemic inefficiency and suboptimal resource allocation. We introduce JSAM (Joint client Selection and privacy compensAtion Mechanism), a Bayesian-optimal framework that simultaneously optimizes client selection probabilities and privacy compensation to maximize training effectiveness under budget constraints. Our approach transforms a complex 2N-dimensional optimization problem into an efficient three-dimensional formulation through novel theoretical characterization of optimal selection strategies. We prove that servers should preferentially select privacy-tolerant clients while excluding high-sensitivity participants, and uncover the counter-intuitive insight that clients with minimal privacy sensitivity may incur the highest cumulative costs due to frequent participation. Extensive evaluations on MNIST and CIFAR-10 demonstrate that JSAM achieves up to 15% improvement in test accuracy compared to existing unbiased selection mechanisms while maintaining cost efficiency across varying data heterogeneity levels.
Governing AI Forgetting: Auditing for Machine Unlearning Compliance
Feb 16, 2026Despite legal mandates for the right to be forgotten, AI operators routinely fail to comply with data deletion requests. While machine unlearning (MU) provides a technical solution to remove personal data's influence from trained models, ensuring compliance remains challenging due to the fundamental gap between MU's technical feasibility and regulatory implementation. In this paper, we introduce the first economic framework for auditing MU compliance, by integrating certified unlearning theory with regulatory enforcement. We first characterize MU's inherent verification uncertainty using a hypothesis-testing interpretation of certified unlearning to derive the auditor's detection capability, and then propose a game-theoretic model to capture the strategic interactions between the auditor and the operator. A key technical challenge arises from MU-specific nonlinearities inherent in the model utility and the detection probability, which create complex strategic couplings that traditional auditing frameworks do not address and that also preclude closed-form solutions. We address this by transforming the complex bivariate nonlinear fixed-point problem into a tractable univariate auxiliary problem, enabling us to decouple the system and establish the equilibrium existence, uniqueness, and structural properties without relying on explicit solutions. Counterintuitively, our analysis reveals that the auditor can optimally reduce the inspection intensity as deletion requests increase, since the operator's weakened unlearning makes non-compliance easier to detect. This is consistent with recent auditing reductions in China despite growing deletion requests. Moreover, we prove that although undisclosed auditing offers informational advantages for the auditor, it paradoxically reduces the regulatory cost-effectiveness relative to disclosed auditing.
Mechanism Design for Federated Learning with Non-Monotonic Network Effects
Jan 08, 2026Mechanism design is pivotal to federated learning (FL) for maximizing social welfare by coordinating self-interested clients. Existing mechanisms, however, often overlook the network effects of client participation and the diverse model performance requirements (i.e., generalization error) across applications, leading to suboptimal incentives and social welfare, or even inapplicability in real deployments. To address this gap, we explore incentive mechanism design for FL with network effects and application-specific requirements of model performance. We develop a theoretical model to quantify the impact of network effects on heterogeneous client participation, revealing the non-monotonic nature of such effects. Based on these insights, we propose a Model Trading and Sharing (MoTS) framework, which enables clients to obtain FL models through either participation or purchase. To further address clients' strategic behaviors, we design a Social Welfare maximization with Application-aware and Network effects (SWAN) mechanism, exploiting model customer payments for incentivization. Experimental results on a hardware prototype demonstrate that our SWAN mechanism outperforms existing FL mechanisms, improving social welfare by up to $352.42\%$ and reducing extra incentive costs by $93.07\%$.
Trading Vector Data in Vector Databases
Nov 10, 2025Vector data trading is essential for cross-domain learning with vector databases, yet it remains largely unexplored. We study this problem under online learning, where sellers face uncertain retrieval costs and buyers provide stochastic feedback to posted prices. Three main challenges arise: (1) heterogeneous and partial feedback in configuration learning, (2) variable and complex feedback in pricing learning, and (3) inherent coupling between configuration and pricing decisions. We propose a hierarchical bandit framework that jointly optimizes retrieval configurations and pricing. Stage I employs contextual clustering with confidence-based exploration to learn effective configurations with logarithmic regret. Stage II adopts interval-based price selection with local Taylor approximation to estimate buyer responses and achieve sublinear regret. We establish theoretical guarantees with polynomial time complexity and validate the framework on four real-world datasets, demonstrating consistent improvements in cumulative reward and regret reduction compared with existing methods.
Adaptive Heterogeneous Client Sampling for Federated Learning over Wireless Networks
Apr 22, 2024



Federated learning (FL) algorithms usually sample a fraction of clients in each round (partial participation) when the number of participants is large and the server's communication bandwidth is limited. Recent works on the convergence analysis of FL have focused on unbiased client sampling, e.g., sampling uniformly at random, which suffers from slow wall-clock time for convergence due to high degrees of system heterogeneity and statistical heterogeneity. This paper aims to design an adaptive client sampling algorithm for FL over wireless networks that tackles both system and statistical heterogeneity to minimize the wall-clock convergence time. We obtain a new tractable convergence bound for FL algorithms with arbitrary client sampling probability. Based on the bound, we analytically establish the relationship between the total learning time and sampling probability with an adaptive bandwidth allocation scheme, which results in a non-convex optimization problem. We design an efficient algorithm for learning the unknown parameters in the convergence bound and develop a low-complexity algorithm to approximately solve the non-convex problem. Our solution reveals the impact of system and statistical heterogeneity parameters on the optimal client sampling design. Moreover, our solution shows that as the number of sampled clients increases, the total convergence time first decreases and then increases because a larger sampling number reduces the number of rounds for convergence but results in a longer expected time per-round due to limited wireless bandwidth. Experimental results from both hardware prototype and simulation demonstrate that our proposed sampling scheme significantly reduces the convergence time compared to several baseline sampling schemes.
Federated Learning While Providing Model as a Service: Joint Training and Inference Optimization
Dec 21, 2023While providing machine learning model as a service to process users' inference requests, online applications can periodically upgrade the model utilizing newly collected data. Federated learning (FL) is beneficial for enabling the training of models across distributed clients while keeping the data locally. However, existing work has overlooked the coexistence of model training and inference under clients' limited resources. This paper focuses on the joint optimization of model training and inference to maximize inference performance at clients. Such an optimization faces several challenges. The first challenge is to characterize the clients' inference performance when clients may partially participate in FL. To resolve this challenge, we introduce a new notion of age of model (AoM) to quantify client-side model freshness, based on which we use FL's global model convergence error as an approximate measure of inference performance. The second challenge is the tight coupling among clients' decisions, including participation probability in FL, model download probability, and service rates. Toward the challenges, we propose an online problem approximation to reduce the problem complexity and optimize the resources to balance the needs of model training and inference. Experimental results demonstrate that the proposed algorithm improves the average inference accuracy by up to 12%.
Provably Convergent Federated Trilevel Learning
Dec 19, 2023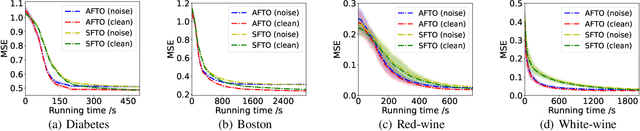
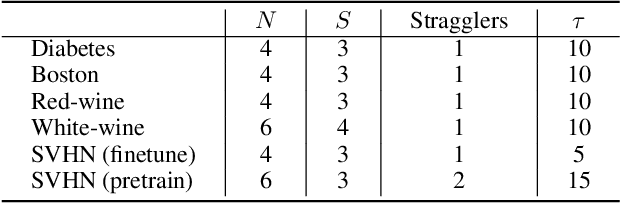
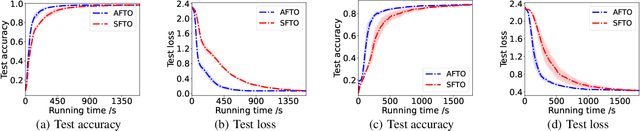
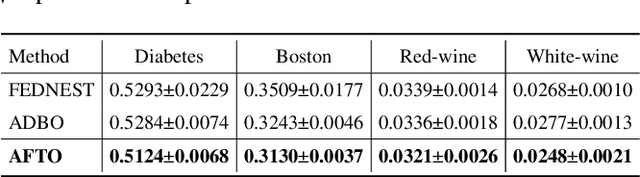
Trilevel learning, also called trilevel optimization (TLO), has been recognized as a powerful modelling tool for hierarchical decision process and widely applied in many machine learning applications, such as robust neural architecture search, hyperparameter optimization, and domain adaptation. Tackling TLO problems has presented a great challenge due to their nested decision-making structure. In addition, existing works on TLO face the following key challenges: 1) they all focus on the non-distributed setting, which may lead to privacy breach; 2) they do not offer any non-asymptotic convergence analysis which characterizes how fast an algorithm converges. To address the aforementioned challenges, this paper proposes an asynchronous federated trilevel optimization method to solve TLO problems. The proposed method utilizes $\mu$-cuts to construct a hyper-polyhedral approximation for the TLO problem and solve it in an asynchronous manner. We demonstrate that the proposed $\mu$-cuts are applicable to not only convex functions but also a wide range of non-convex functions that meet the $\mu$-weakly convex assumption. Furthermore, we theoretically analyze the non-asymptotic convergence rate for the proposed method by showing its iteration complexity to obtain $\epsilon$-stationary point is upper bounded by $\mathcal{O}(\frac{1}{\epsilon^2})$. Extensive experiments on real-world datasets have been conducted to elucidate the superiority of the proposed method, e.g., it has a faster convergence rate with a maximum acceleration of approximately 80$\%$.
FedAL: Black-Box Federated Knowledge Distillation Enabled by Adversarial Learning
Nov 28, 2023

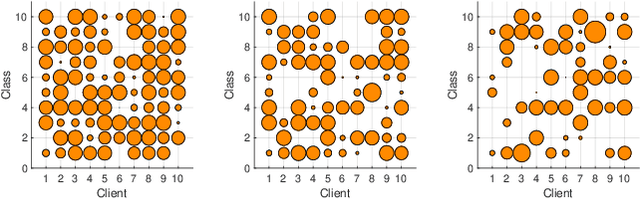

Knowledge distillation (KD) can enable collaborative learning among distributed clients that have different model architectures and do not share their local data and model parameters with others. Each client updates its local model using the average model output/feature of all client models as the target, known as federated KD. However, existing federated KD methods often do not perform well when clients' local models are trained with heterogeneous local datasets. In this paper, we propose Federated knowledge distillation enabled by Adversarial Learning (FedAL) to address the data heterogeneity among clients. First, to alleviate the local model output divergence across clients caused by data heterogeneity, the server acts as a discriminator to guide clients' local model training to achieve consensus model outputs among clients through a min-max game between clients and the discriminator. Moreover, catastrophic forgetting may happen during the clients' local training and global knowledge transfer due to clients' heterogeneous local data. Towards this challenge, we design the less-forgetting regularization for both local training and global knowledge transfer to guarantee clients' ability to transfer/learn knowledge to/from others. Experimental results show that FedAL and its variants achieve higher accuracy than other federated KD baselines.