 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable Preference Optimization for LLMs: A Bilevel Approach Beyond Direct Preference Optimization
Jul 10, 2025Direct Preference Optimization (DPO) has emerged as a popular and efficient alternative to reward modeling and reinforcement learning for aligning language models with human preferences. Despite its empirical success, the theoretical properties and intrinsic limitations of DPO remain underexplored. In this work, we first present a comprehensive analysis of DPO's dynamics from a probability evolution perspective. Our analysis reveals that DPO is highly sensitive to initialization. It also tends to misallocate probability mass, which can inadvertently shift probability toward irrelevant or undesired responses. This misallocation may unintentionally reinforce model bias, thereby compromising both the stability of model alignment and the consistency with intended preferences. Motivated by these theoretical findings, we propose a theoretically grounded bilevel optimization framework that tightly integrate supervised fine-tuning with an enhanced DPO objective a.k.a. stable preference optimization. Our approach introduces a principled regularization scheme to explicitly encourage absolute probability improvement for preferred outputs, while maintaining stable optimization dynamics. Experiments on challenging reasoning and summarization benchmarks elucidate that our method consistently improves reasoning accuracy and better aligns output distributions with intended preferences, outperforming standard DPO. Stable preference optimization provides new insights into the design of preference-based alignment objectives and opens up new avenues towards more reliable and interpretable language model alignment.
Unlocking TriLevel Learning with Level-Wise Zeroth Order Constraints: Distributed Algorithms and Provable Non-Asymptotic Convergence
Dec 10, 2024



Trilevel learning (TLL) found diverse applications in numerous machine learning applications, ranging from robust hyperparameter optimization to domain adaptation. However, existing researches primarily focus on scenarios where TLL can be addressed with first order information available at each level, which is inadequate in many situations involving zeroth order constraints, such as when black-box models are employed. Moreover, in trilevel learning, data may be distributed across various nodes, necessitating strategies to address TLL problems without centralizing data on servers to uphold data privacy. To this end, an effective distributed trilevel zeroth order learning framework DTZO is proposed in this work to address the TLL problems with level-wise zeroth order constraints in a distributed manner. The proposed DTZO is versatile and can be adapted to a wide range of (grey-box) TLL problems with partial zeroth order constraints. In DTZO, the cascaded polynomial approximation can be constructed without relying on gradients or sub-gradients, leveraging a novel cut, i.e., zeroth order cut. Furthermore, we theoretically carry out the non-asymptotic convergence rate analysis for the proposed DTZO in achieving the $\epsilon$-stationary point. Extensive experiments have been conducted to demonstrate and validate the superior performance of the proposed DTZO, e.g., it approximately achieves up to a 40$\%$ improvement in performance.
Tri-Level Navigator: LLM-Empowered Tri-Level Learning for Time Series OOD Generalization
Oct 09, 2024



Out-of-Distribution (OOD) generalization in machine learning is a burgeoning area of study. Its primary goal is to enhance the adaptability and resilience of machine learning models when faced with new, unseen, and potentially adversarial data that significantly diverges from their original training datasets. In this paper, we investigate time series OOD generalization via pre-trained Large Language Models (LLMs). We first propose a novel \textbf{T}ri-level learning framework for \textbf{T}ime \textbf{S}eries \textbf{O}OD generalization, termed TTSO, which considers both sample-level and group-level uncertainties. This formula offers a fresh theoretic perspective for formulating and analyzing OOD generalization problem. In addition, we provide a theoretical analysis to justify this method is well motivated. We then develop a stratified localization algorithm tailored for this tri-level optimization problem, theoretically demonstrating the guaranteed convergence of the proposed algorithm. Our analysis also reveals that the iteration complexity to obtain an $\epsilon$-stationary point is bounded by O($\frac{1}{\epsilon^{2}}$). Extensive experiments on real-world datasets have been conducted to elucidate the effectiveness of the proposed method.
Provably Convergent Federated Trilevel Learning
Dec 19, 2023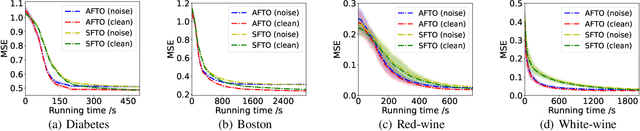
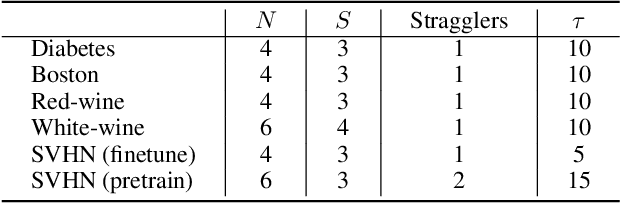
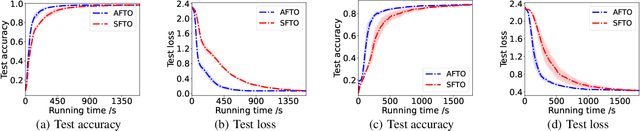
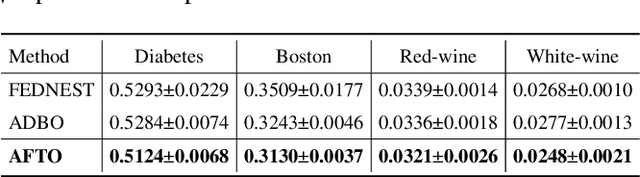
Trilevel learning, also called trilevel optimization (TLO), has been recognized as a powerful modelling tool for hierarchical decision process and widely applied in many machine learning applications, such as robust neural architecture search, hyperparameter optimization, and domain adaptation. Tackling TLO problems has presented a great challenge due to their nested decision-making structure. In addition, existing works on TLO face the following key challenges: 1) they all focus on the non-distributed setting, which may lead to privacy breach; 2) they do not offer any non-asymptotic convergence analysis which characterizes how fast an algorithm converges. To address the aforementioned challenges, this paper proposes an asynchronous federated trilevel optimization method to solve TLO problems. The proposed method utilizes $\mu$-cuts to construct a hyper-polyhedral approximation for the TLO problem and solve it in an asynchronous manner. We demonstrate that the proposed $\mu$-cuts are applicable to not only convex functions but also a wide range of non-convex functions that meet the $\mu$-weakly convex assumption. Furthermore, we theoretically analyze the non-asymptotic convergence rate for the proposed method by showing its iteration complexity to obtain $\epsilon$-stationary point is upper bounded by $\mathcal{O}(\frac{1}{\epsilon^2})$. Extensive experiments on real-world datasets have been conducted to elucidate the superiority of the proposed method, e.g., it has a faster convergence rate with a maximum acceleration of approximately 80$\%$.
Asynchronous Distributed Bilevel Optimization
Dec 20, 2022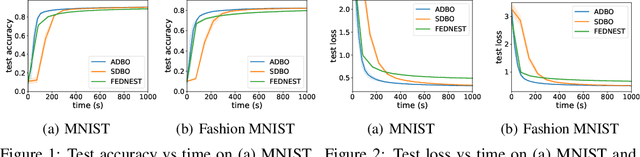
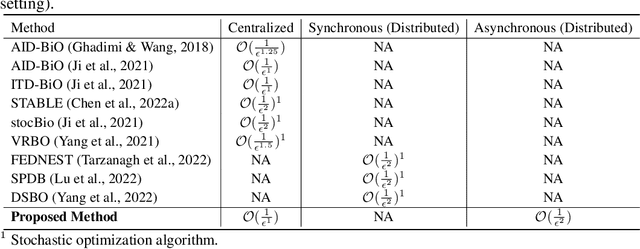
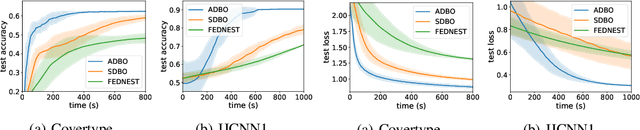
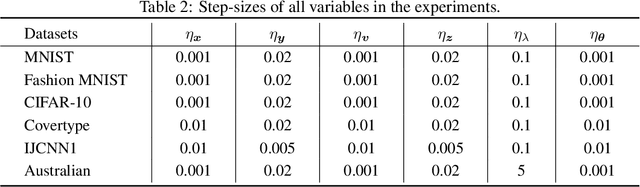
Bilevel optimization plays an essential role in many machine learning tasks, ranging from hyperparameter optimization to meta-learning. Existing studies on bilevel optimization, however, focus on either centralized or synchronous distributed setting. The centralized bilevel optimization approaches require collecting massive amount of data to a single server, which inevitably incur significant communication expenses and may give rise to data privacy risks. Synchronous distributed bilevel optimization algorithms, on the other hand, often face the straggler problem and will immediately stop working if a few workers fail to respond. As a remedy, we propose Asynchronous Distributed Bilevel Optimization (ADBO) algorithm. The proposed ADBO can tackle bilevel optimization problems with both nonconvex upper-level and lower-level objective functions, and its convergence is theoretically guaranteed. Furthermore, it is revealed through theoretic analysis that the iteration complexity of ADBO to obtain the $\epsilon$-stationary point is upper bounded by $\mathcal{O}(\frac{1}{{{\epsilon ^2}}})$. Thorough empirical studies on public datasets have been conducted to elucidate the effectiveness and efficiency of the proposed ADBO.