 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Simulation for Policy Learning in Physical Human-Robot Interaction
Apr 09, 2026Developing autonomous physical human-robot interaction (pHRI) systems is limited by the scarcity of large-scale training data to learn robust robot behaviors for real-world applications. In this paper, we introduce a zero-shot "text2sim2real" generative simulation framework that automatically synthesizes diverse pHRI scenarios from high-level natural-language prompts. Leveraging Large Language Models (LLMs) and Vision-Language Models (VLMs), our pipeline procedurally generates soft-body human models, scene layouts, and robot motion trajectories for assistive tasks. We utilize this framework to autonomously collect large-scale synthetic demonstration datasets and then train vision-based imitation learning policies operating on segmented point clouds. We evaluate our approach through a user study on two physically assistive tasks: scratching and bathing. Our learned policies successfully achieve zero-shot sim-to-real transfer, attaining success rates exceeding 80% and demonstrating resilience to unscripted human motion. Overall, we introduce the first generative simulation pipeline for pHRI applications, automating simulation environment synthesis, data collection, and policy learning. Additional information may be found on our project website: https://rchi-lab.github.io/gen_phri/
Dexterous Manipulation Policies from RGB Human Videos via 4D Hand-Object Trajectory Reconstruction
Feb 09, 2026Multi-finger robotic hand manipulation and grasping are challenging due to the high-dimensional action space and the difficulty of acquiring large-scale training data. Existing approaches largely rely on human teleoperation with wearable devices or specialized sensing equipment to capture hand-object interactions, which limits scalability. In this work, we propose VIDEOMANIP, a device-free framework that learns dexterous manipulation directly from RGB human videos. Leveraging recent advances in computer vision, VIDEOMANIP reconstructs explicit 4D robot-object trajectories from monocular videos by estimating human hand poses, object meshes, and retargets the reconstructed human motions to robotic hands for manipulation learning. To make the reconstructed robot data suitable for dexterous manipulation training, we introduce hand-object contact optimization with interaction-centric grasp modeling, as well as a demonstration synthesis strategy that generates diverse training trajectories from a single video, enabling generalizable policy learning without additional robot demonstrations. In simulation, the learned grasping model achieves a 70.25% success rate across 20 diverse objects using the Inspire Hand. In the real world, manipulation policies trained from RGB videos achieve an average 62.86% success rate across seven tasks using the LEAP Hand, outperforming retargeting-based methods by 15.87%. Project videos are available at videomanip.github.io.
Geometric Red-Teaming for Robotic Manipulation
Sep 15, 2025Standard evaluation protocols in robotic manipulation typically assess policy performance over curated, in-distribution test sets, offering limited insight into how systems fail under plausible variation. We introduce Geometric Red-Teaming (GRT), a red-teaming framework that probes robustness through object-centric geometric perturbations, automatically generating CrashShapes -- structurally valid, user-constrained mesh deformations that trigger catastrophic failures in pre-trained manipulation policies. The method integrates a Jacobian field-based deformation model with a gradient-free, simulator-in-the-loop optimization strategy. Across insertion, articulation, and grasping tasks, GRT consistently discovers deformations that collapse policy performance, revealing brittle failure modes missed by static benchmarks. By combining task-level policy rollouts with constraint-aware shape exploration, we aim to build a general purpose framework for structured, object-centric robustness evaluation in robotic manipulation. We additionally show that fine-tuning on individual CrashShapes, a process we refer to as blue-teaming, improves task success by up to 60 percentage points on those shapes, while preserving performance on the original object, demonstrating the utility of red-teamed geometries for targeted policy refinement. Finally, we validate both red-teaming and blue-teaming results with a real robotic arm, observing that simulated CrashShapes reduce task success from 90% to as low as 22.5%, and that blue-teaming recovers performance to up to 90% on the corresponding real-world geometry -- closely matching simulation outcomes. Videos and code can be found on our project website: https://georedteam.github.io/ .
Provably Convergent Federated Trilevel Learning
Dec 19, 2023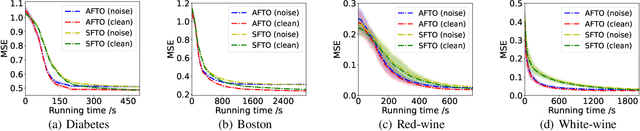
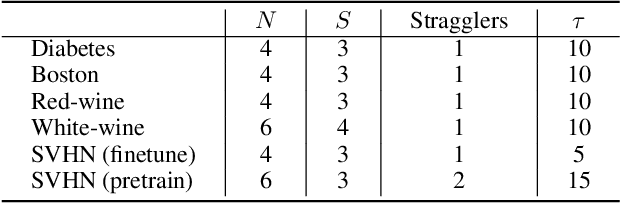
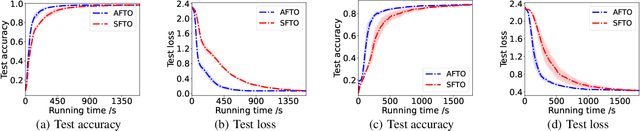
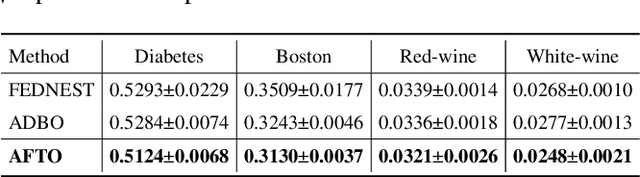
Trilevel learning, also called trilevel optimization (TLO), has been recognized as a powerful modelling tool for hierarchical decision process and widely applied in many machine learning applications, such as robust neural architecture search, hyperparameter optimization, and domain adaptation. Tackling TLO problems has presented a great challenge due to their nested decision-making structure. In addition, existing works on TLO face the following key challenges: 1) they all focus on the non-distributed setting, which may lead to privacy breach; 2) they do not offer any non-asymptotic convergence analysis which characterizes how fast an algorithm converges. To address the aforementioned challenges, this paper proposes an asynchronous federated trilevel optimization method to solve TLO problems. The proposed method utilizes $\mu$-cuts to construct a hyper-polyhedral approximation for the TLO problem and solve it in an asynchronous manner. We demonstrate that the proposed $\mu$-cuts are applicable to not only convex functions but also a wide range of non-convex functions that meet the $\mu$-weakly convex assumption. Furthermore, we theoretically analyze the non-asymptotic convergence rate for the proposed method by showing its iteration complexity to obtain $\epsilon$-stationary point is upper bounded by $\mathcal{O}(\frac{1}{\epsilon^2})$. Extensive experiments on real-world datasets have been conducted to elucidate the superiority of the proposed method, e.g., it has a faster convergence rate with a maximum acceleration of approximately 80$\%$.
Asynchronous Distributed Bilevel Optimization
Dec 20, 2022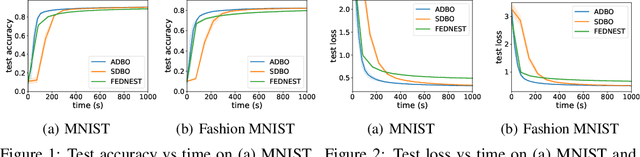
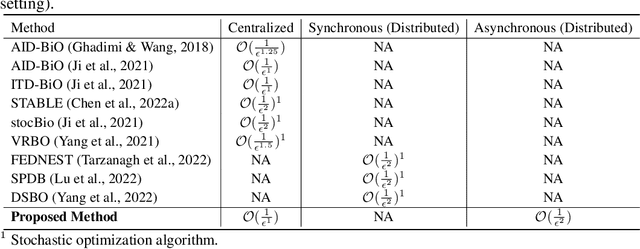
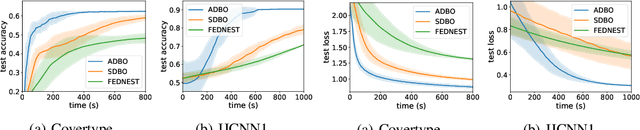
Bilevel optimization plays an essential role in many machine learning tasks, ranging from hyperparameter optimization to meta-learning. Existing studies on bilevel optimization, however, focus on either centralized or synchronous distributed setting. The centralized bilevel optimization approaches require collecting massive amount of data to a single server, which inevitably incur significant communication expenses and may give rise to data privacy risks. Synchronous distributed bilevel optimization algorithms, on the other hand, often face the straggler problem and will immediately stop working if a few workers fail to respond. As a remedy, we propose Asynchronous Distributed Bilevel Optimization (ADBO) algorithm. The proposed ADBO can tackle bilevel optimization problems with both nonconvex upper-level and lower-level objective functions, and its convergence is theoretically guaranteed. Furthermore, it is revealed through theoretic analysis that the iteration complexity of ADBO to obtain the $\epsilon$-stationary point is upper bounded by $\mathcal{O}(\frac{1}{{{\epsilon ^2}}})$. Thorough empirical studies on public datasets have been conducted to elucidate the effectiveness and efficiency of the proposed ADBO.
KDLSQ-BERT: A Quantized Bert Combining Knowledge Distillation with Learned Step Size Quantization
Jan 15, 2021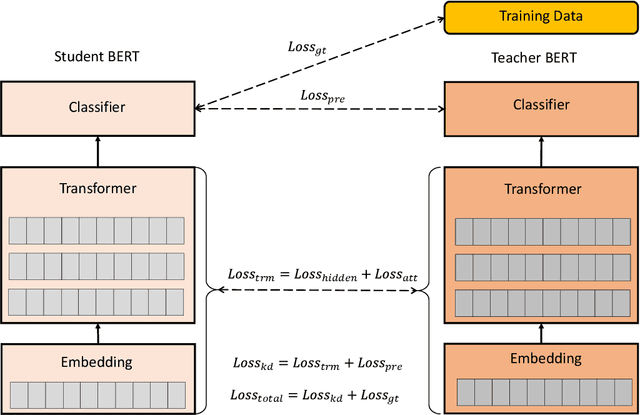
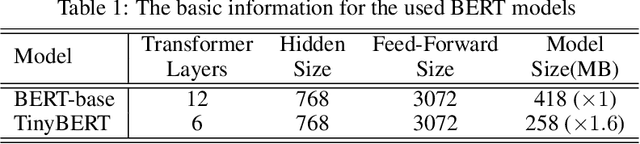
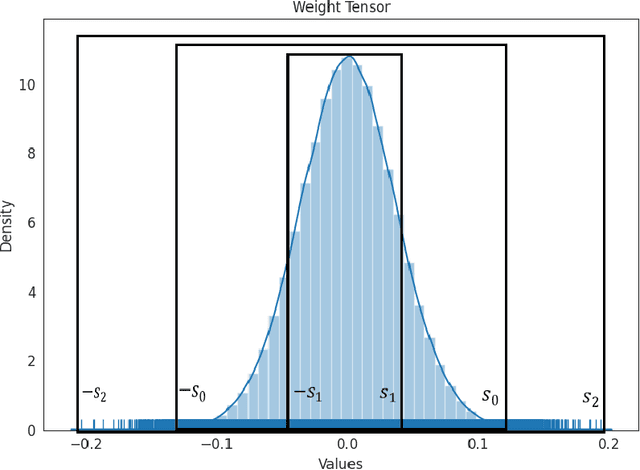
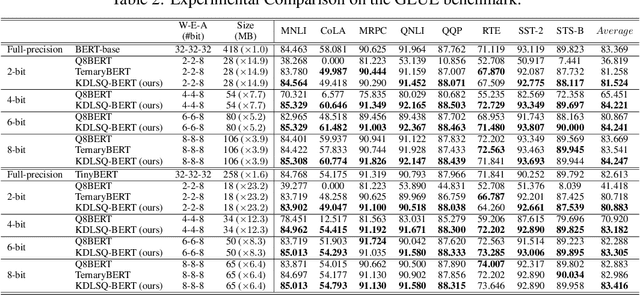
Recently, transformer-based language models such as BERT have shown tremendous performance improvement for a range of natural language processing tasks. However, these language models usually are computation expensive and memory intensive during inference. As a result, it is difficult to deploy them on resource-restricted devices. To improve the inference performance, as well as reduce the model size while maintaining the model accuracy, we propose a novel quantization method named KDLSQ-BERT that combines knowledge distillation (KD) with learned step size quantization (LSQ) for language model quantization. The main idea of our method is that the KD technique is leveraged to transfer the knowledge from a "teacher" model to a "student" model when exploiting LSQ to quantize that "student" model during the quantization training process. Extensive experiment results on GLUE benchmark and SQuAD demonstrate that our proposed KDLSQ-BERT not only performs effectively when doing different bit (e.g. 2-bit $\sim$ 8-bit) quantization, but also outperforms the existing BERT quantization methods, and even achieves comparable performance as the full-precision base-line model while obtaining 14.9x compression ratio. Our code will be public available.